Just for Life.明月更几时2024-08-04T13:19:17.948Zhttps://muyuuuu.github.io/兰铃HexoCUFX(CUDA Framework eXtended): CUDA 计算框架https://muyuuuu.github.io/2024/08/04/CUFX/2024-08-04T06:31:33.000Z2024-08-04T13:19:17.948Z
利用下班时间学完了 CUDA,Anyway 忙起来真的很大程度能缓解焦虑,能忘记和忽略很多烦恼。所以寻思着结合这一年来所学,写了一个简单的 CUDA 计算框架:CUFX。
voidfoo(std::string& s){ std::cout << " left value ref " << s << std::endl; }
voidfoo(std::string&& s){ std::cout << "right value ref " << s << std::endl; }
voidfunc(std::string&& param){ foo(param); }
intmain(){ std::string s{"sad"}; func(s); // left value ref test func("test"); // left value ref test return0; }
万能引用
也许你会注意到,在 func 函数中,参数的写法为:std::string&& param,考虑一种情况,如果 func 的参数很多,比如有 n 个,那么 func() 函数就需要 2 的 n 次方个 fun() 函数,显然这不是一个好方法。也就是基于此,才有了万能引用,如果用万能引用的方式,则只需一个函数即可,如下:
1 2
template<typename T> voidfunc(T&& param)
如果一个变量或者参数被声明为类型 T&&,且 T 是一个被推导的类型,那这个变量或参数就是一个万能引用。
引用折叠
考虑以下代码:
1 2 3 4 5 6 7 8 9 10 11 12
template<typename T> voidfunc(T&& param){ // a为万能引用 // do sth }
intmain(){ int a = 1; int &b = a; fun(a); // OK fun(1); // OK fun(b); }
从上述代码可看,b 的类型为左值引用即 int &,如果不考虑引用折叠,那么 fun() 函数中 t 的类型就是 int & &&,显然这种声明方式,编译器会报错。而这里编译器却允许在一定的情况下进行隐含的多层引用推导,这就是 reference collapsing (引用折叠)。C++ 中有两种引用(左值引用和右值引用),因此引用折叠就有四种组合。如果两个引用中至少其中一个引用是左值引用,那么折叠结果就是左值引用;否则折叠结果就是右值引用。
1 2 3 4 5 6 7
using T = int &; T& r1; // int& & r1 -> int& r1 T&& r2; // int& && r2 -> int& r2
using U = int &&; U& r3; // int&& & r3 -> int& r3 U&& r4; // int&& && r4 -> int&& r4
最终会创建一个元素值都为 0 的数组 int arr[sizeof...(Args)]。由于是逗号表达式,在创建数组的过程中会先执行逗号表达式前面的部分 printarg(args) 打印出参数,也就是说在构造 int 数组的过程中就将参数包展开了,这个数组的目的纯粹是为了在数组构造的过程展开参数包。
if __name__ == "__main__": n_data_serial = [i for i inrange(100)] n_data_parall = [i for i inrange(100)] serial(n_data_serial) parall(n_data_parall) print(" Compare Res : {}".format(n_data_serial == n_data_parall))
voidsgemm_neon2(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) { int row, col, m; for (row = 0; row < d0; row+=4) { for (col = 0; col < d2; col+=4) {
voidrsgemm_neon1(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) { int row, col, m; for (row = 0; row < d0; row++) { for (m = 0; m < d1; m++) {
voidrsgemm_neon2(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) { int row, col, m; for (row = 0; row < d0; row++) { for (m = 0; m < d1; m+=4) {
float *pb0 = B + (m + 0) * d2; float *pb1 = B + (m + 1) * d2; float *pb2 = B + (m + 2) * d2; float *pb3 = B + (m + 3) * d2;
voidrsgemm_neon3(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) { int row, col, m; for (row = 0; row < d0; row+=4) { for (m = 0; m < d1; m+=4) {
float *pb0 = B + (m + 0) * d2; float *pb1 = B + (m + 1) * d2; float *pb2 = B + (m + 2) * d2; float *pb3 = B + (m + 3) * d2;
float *pc0 = C + (0 + row) * d2; float *pc1 = C + (1 + row) * d2; float *pc2 = C + (2 + row) * d2; float *pc3 = C + (3 + row) * d2;
仿佛不如字典简单?确切来说,这种方法有自己的适用场景:当 A 函数获取 info.get_item 信息后需要进行 postA 的后处理,当 B 函数获取 info.get_item 信息后需要进行 postB 的后处理。这样,就可以把 postA 和 postB 放入到 class Info 中,将分散到各地的相同逻辑的代码整合到一起。至于 "info1" 和 "info2" 这种硬编码,也可以用前面讲的东西规避掉。
model 就是数据解析,存储和维护一些数据结构,如果想要的数据不能直接获取,也可以在 model 里增加一些获取数据的接口。建议将 model 封装为一个类,在一个方法里读取文件,解析得到数据结构,并放到类成员中,方便接口调用获取数据,也避免重复读文件和数据传来传去带来的拷贝开销。交由一个对象去维护数据,由对象的接口去操作数据。而不是将数据读取放到全局变量,任由各个代码、各个函数随意操作。
view 是数据的展示,以什么形式和结构展示给用户,显示界面、写出文件或命令行输出等形式;
control 是交互的控制,用于捕捉用户请求,按照请求访问 model 的接口并获得想要的数据,再调用 view 接口反馈给用户。
当需要获取很多种类型的数据时,开发重点在 model 部分,因为 control 只是调用获取数据的接口,view 只是展示数据。当需要 A 类型的数据时,control 调用 model 的 getA() 方法即可,当需要 B 类型的数据时,调用 model 的 getB() 方法。
重点就是这两个方法去如何实现,如何设计高效的数据结构去维护数据,来减少数据的拷贝和优化获取数据的效率。总不能 getA() 的时候重新读文件,getB() 的时候再去读文件,对吧。这就需要在 model 部分下工夫,比如这次就用到了数据结构中经典的 dfs+树的后根法快速解析了数据。leetcode 没白刷了属于是
关于代码维护
额外的,在开发 model 时也有其他的收获:写代码尽可能将各个模块独立封装,写出高内聚,低耦合的传说级代码。虽然当函数很多时会很看着有些乱,怎么到处是函数?但是也有重要的优点:代码和数据重用方便。比如要增加一个新功能,只需要写一点函数,其他函数也许已经实现了,我们直接调用就好,而且不易出错。
因为是临时新建的仓库,所以目前处于 master 分支。执行下面命令,将本地的 master 分支推送到远程的 test 分支(远程没有的话会自动创建):
1
git push origin master:test // 不加 master: 会报错,因为本地没有 test 分支
修改错别字,不值得重新 commit
首先修改小错误,然后:
1 2
git add . git commmit --amend
如果此时直接 push 会报错,因为 git status 显示并没有新的内容。如果是提交到自己的分支,在不影响他人的开发的情况下可以直接:
1
git push origin master:test -f
这样仓库上只显示一次 commit 记录。如果不是强制推送,那么会遇到下面的问题:
1 2 3 4 5 6 7
To git@github.xxxx.git ! [rejected] master -> main (non-fast-forward) error: failed to push some refs to 'git@github.xxxx.git' hint: Updates were rejected because a pushed branch tip is behind its remote hint: counterpart. Check out this branch and integrate the remote changes hint: (e.g. 'git pull ...') before pushing again. hint: See the 'Note about fast-forwards' in 'git push --help' for details.
甚至还想感谢 XM,给我提供了人生的第一份工作,开了极具诱惑力的薪资,还是我很向往的工作方向。本科学的 A 方向,对 B 方向感兴趣,研究生学的 C 方向,对 E 方向感兴趣,但没有 E 方向的相关知识储备和项目经验,所以找工作准备的 D 方向。最后 XM 提供的工作方向是 E,兜兜转转还是遇到了最喜欢的方向,真的十分满足。其实还有一些宿命论的味道,我第一门学习的编程语言大一开设的 C++ 课程,之后对编程萌发了兴趣转专业去学计算机,未来的工作方向也是 C++,很长一段时间内都要靠它吃饭了。
来形容一下某头部大厂的面试,开局两个 hard 级别的 leetcode 题,我写上来了。结果以为后面会很顺畅,结果呢,面试全程就三个字,嗯,啊,好,面试结束。后来才知道他想用代码题来劝退我,早知道我就不写了。在形容一下某硬件大厂的面试:你了解过XX吗,我说没有;你用过XX吗,我说不好意思只听说过。面试直接结束,全程不到5分钟,至于简历里写了什么,你是做什么的一概不问。
京东,网易和腾讯的题目都是令人劝退的难度。如果说数学不会还能写个解,编程不会甚至不能写个空格。我还清楚的记得今年的网易,京东和百度都在围绕 red 这个字符串出题,红色意味着警告,可能告诉我们今年形式很严峻吧。蚂蚁笔试干脆交了白卷,后续的笔试也没有参加,不是看不上蚂蚁,是我真的累了;字节笔试一个不会,瞪着屏幕发呆两小时的感觉很难受。7月投了多少公司,8月就收了多少感谢信。
model: nn.Sequential = ... [m(x) for x in model] 不是
1 2 3 4 5 6 7 8
classA(nn.Module): backbone: nn.Module head: Optiona[nn.Module] defforward(self, x): x = self.backbone(x) if self.head isnotNone: x = self.head(x) return x
defforward(self, ...): # ... some forward logic @torch.jit.script_if_tracing def_inner_impl(x, y, z, flag: bool): # use control flow, etc. return ... output = _inner_impl(x, y, z, flag) # ... other forward logic
# Before: if x.numel() > 0: # This branch cannot be compiled by @script_if_tracing because it refers to `self.layers` x = preprocess(x) output = self.layers(x) else: output = torch.zeros(...) # Create empty outputs
# After: if x.numel() > 0: # This branch can now be compiled by @script_if_tracing x = preprocess(x) else: x = torch.zeros(...) # Create empty inputs # Needs to make sure self.layers accept empty inputs. # If necessary, add such condition branch into self.layers as well. output = self.layers(x)
classA(nn.Module): defforward(self, x): # Dispatch to different submodules based on a dynamic, data-dependent condition: return self.submodule1(x) if x.sum() > 0else self.submodule2(x)
classSolution { public: intmaxArea(vector<int>& height){ int n = height.size(); int l = 0, r = n - 1; int res = 0; while (l < r) { int t1 = height[l]; int t2 = height[r]; res = max(res, min(t1, t2) * (r - l)); if (t1 < t2) { l++; } else { r--; } } return res; } };
881. 救生艇
给定数组 people 。people[i] 表示第 i 个人的体重,船的数量不限,每艘船可以承载的最大重量为 limit。每艘船最多可同时载两人,但条件是这些人的重量之和最多为 limit。返回承载所有人所需的最小船数。示例:
栈区:程序自动向操作系统申请分配以及回收,速度快,使用方便,但是程序员无法控制。如果分配的内存超过了栈区的最大空间,会抛出栈溢出错误。const 局部变量也存储在栈区,栈区向地址减小的方向增长。系统为变量在栈上申请内存后,CPU 需要不断地判断变量是否已结束使用的生命周期,如果生命周期结束,系统就会释放为这个变量申请的栈内存,这样一来随着在栈上申请的变量增多,会对 CPU 造成额外的消耗。
堆区:程序员向操作系统申请一段内存,当系统收到程序的申请时,会遍历一个记录空内存结点的链表,找到第一个空间大于或等于所申请空间的堆结点,将该空闲结点从链表中删除,并将该结点的空间分配给程序,如果链表中空闲结点的空间大于申请空间的大小,系统会自动将对于的部分放入空闲链表中,故容易造成内存的碎片化,分配速度较慢,地址不连续。且堆区的内存由程序员申请,也必须由程序员负责管理和释放,否则会导致内存泄漏,堆的增长方向与内存地址的增长方向相同,因此在堆区上申请空间理论上是没有大小限制的,但是受安装内存条的大小和系统以及其他程序的占用,不是无限大的。不像栈上的变量那样,需要消耗 CPU 资源判断变量的生命周期,所以不会对 CPU 造成额外的消耗,这也是程序员申请堆上内存的优点。
malloc 可以申请到超出机器物理内存的大小,为什么说是一部分呢,因为可申请的内存不仅和已占用的内存相关,还和机器的 swap space (虚拟内存)相关,事实上在你给你机器装 Linux 系统的时候应该碰到过,那就是磁盘分区的时候会有一个 swap设定,只需要知道它是一种挂载在物理硬盘上,用来存放一些不太频繁使用的内存,是一种低速的物理内存的扩展。
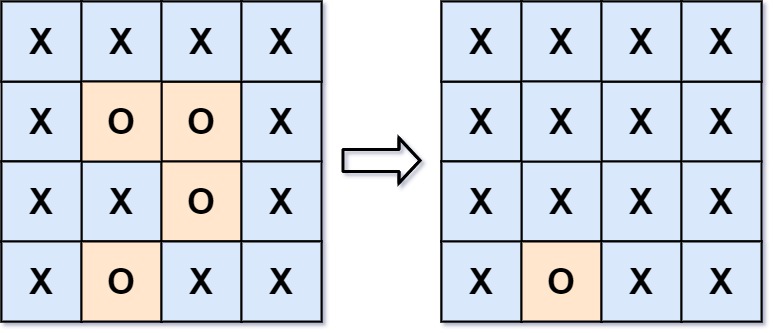
classSolution { public: int n, m; voidsolve(vector<vector<char>>& board){ n = board.size(); m = board[0].size(); // 替换边界 for (int i = 0; i < n; i++) { dfs(i, 0, board, '+'); dfs(i, m-1, board, '+'); } for (int i = 0; i < m; i++) { dfs(0, i, board, '+'); dfs(n-1, i, board, '+'); } // 填充内部的 O for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (board[i][j] == 'O') { dfs(i, j, board, 'X'); } } } // 替换回来 for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { if (board[i][j] == '+') { board[i][j] = 'O'; } } } }
// dfs 查找相连的 O voiddfs(int r, int c, vector<vector<char>>& board, char pad){ if (r < 0 || c < 0 || r >= n || c >= m) { return; } if (board[r][c] == 'O') { board[r][c] = pad; dfs(r + 1, c, board, pad); dfs(r - 1, c, board, pad); dfs(r, c + 1, board, pad); dfs(r, c - 1, board, pad); } } };
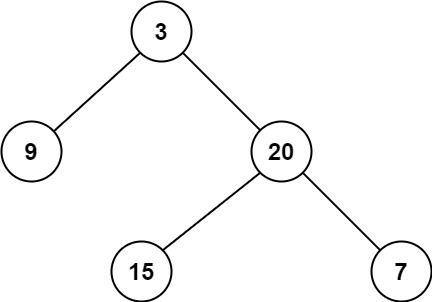
queue.push(root); while (queue.size()) { int s = queue.size(); for (int i = 0; i < s; i++) { auto node = queue.top(); queue.pop(); if (node->left != null) queue.push(node->left); if (node->right != null) queue.push(node->right); } }