某天(今天)下午闲的没事干,想起了当初学了一堆的深度学习的数学概念,还看了Keras的官方文档,既然会写(抄)代码和懂了理念,不如自己折腾点东西玩玩。
说干就干.png,本来是想做个OCR系统在写个GUI界面弄个小软件的,因为种种原因放弃(不喜欢那个数据集),猫狗大战的话数据量太大。挑来挑去选择了迁移学习,使用VGG16的结构去识别MNIST手写文字,怎么感觉有一个好的开始却选择了一个low的实现呢?其实也无所谓,重点是实现过程,有了这次过程实现以后的迁移学习就不是问题了。
如果对本文有疑问或者想找男朋友,可以联系我,点击此处有我联系方式。
迁移学习
所谓迁移学习,是在数据样本较少或者没有GPU或者缺钱的情况下,直接使用别人训练好的参数权重而不是自己重新训练,毕竟自己穷的买不起GPU。当然,别人训练好的权重在自己的小数据集里面同样能取得很好的效果,因为前期的权重无非是提取些水平、数值、纹理特征,而这些基本特征与具体的数据集无关。
比如自己写了十层的网络,可以冻结前九层网络的参数使其不参与训练,在最后添加一层为自己的分类层,将数据带入前九层得到输出$y$,最后一层接收$y$为输入,只训练最后一层的权重预测输出,同时也能得到较好的结果。
同样得到下面的结论:
当数据越多,冻结的层数也越少(训练自己的特征),当有相当可观的数据时,应该从头开始自己训练。
下载数据集
MNIST数据集的下载和导入:
- 下载地址
- numpy导入:
1
2
3
4
5
6
7path='examples/mnist.npz'
f = np.load(path)
x_train1, y_train = f['x_train'], f['y_train']
x_test1, y_test = f['x_test'], ['y_test']
f.close()
下载VGG16权重
提示:
- vgg16_weights_tf_dim_ordering_tf_kernels.h5 表示全部VGG16权重。
- vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5 表示不要最后全连接层的权重。
要下载第二个,因为最后一层是自己要重新定义和训练的,所以不要VGG16原始的最后几层的权重。然而top一共是3层,权重参数的大小就从50MB突变到了500MB。可想最后3层得多少参数。
执行环境
- python 3.5
- keras 2.2.2
- 代码执行的话,一段代码copy进一个jupyter lab的格子里执行就行。像下面那样,怎么总感觉在说废话。。。
![]()
数据预处理
如果用的是其他数据选择性忽略这里。
不幸的是VGG16能接受的图片大小至少是48,必须有RGB三通道,奈何MNIST数据集的大小是28,还没有RGB通道,只能使用numpy快速处理一下。
将图片填充为48 $\times$ 48和三个通道,三个通道就用自己本身复制三次代替,填充值为0。
1 | import keras |
实际的训练数据有60000,我试了一下导入全部数据结果CPU和内存差点爆炸,因为我穷买不起GPU,所以只能用小部分数据做着玩玩,反正学的是思路,再说了迁移学习适合小数据,我只是选择了小部分数据。
1 | # 100个训练数据 |
VGG16迁移
1 | height, width = x_train.shape[1], x_train.shape[2] |
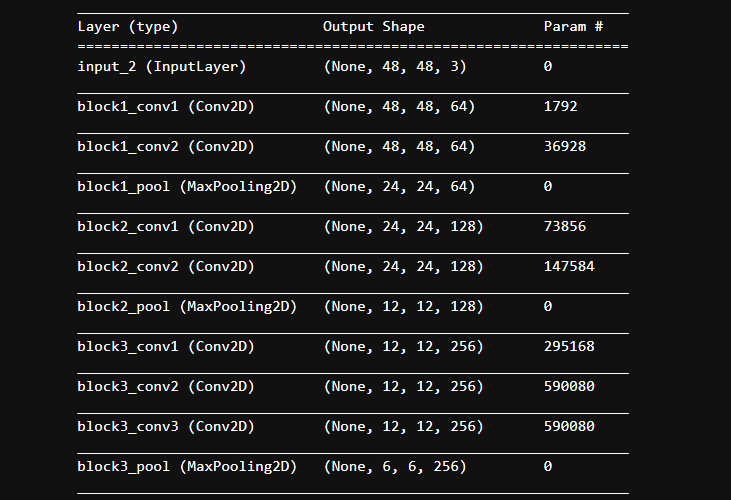
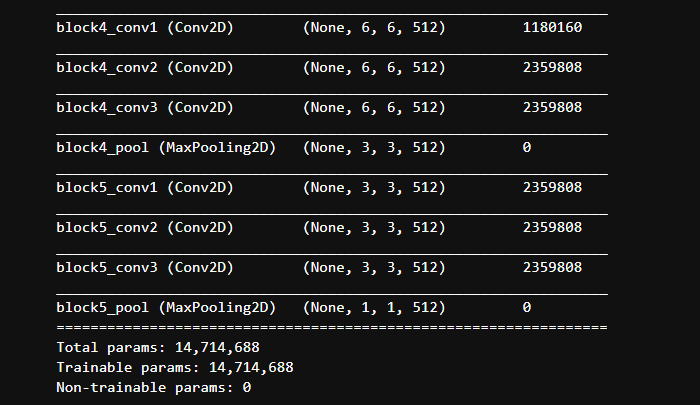
我们发现迁移过来的VGG16是长这样的:最后一层的输出是(1, 1, 512)。那么添加的下一层的全连接层的输入维度就是512。
加入自定义层
将原始图片导入VGG16得到现在开始加入自己自定义的层,我添加了一个100个节点的全连接层和10个节点的全连接层。记得第一层的输入维度是512哦~
1 | # 输出VGG16的计算特征 |
模型训练
训练自己的自定义层,相信反向传播,相信优化器。1
2
3
4
5
6
7x_data = x_data.reshape(100, 512)
y_label = y_train.reshape(100, 1)
# Sequence模型接受类别的数据类型为one-hot或者词向量,这里只能使用one-hot。
y_one_hot_labels = keras.utils.to_categorical(y_label, num_classes=10)
# 开始训练
model.fit(x_data, y_one_hot_labels, epochs=10, batch_size=32)
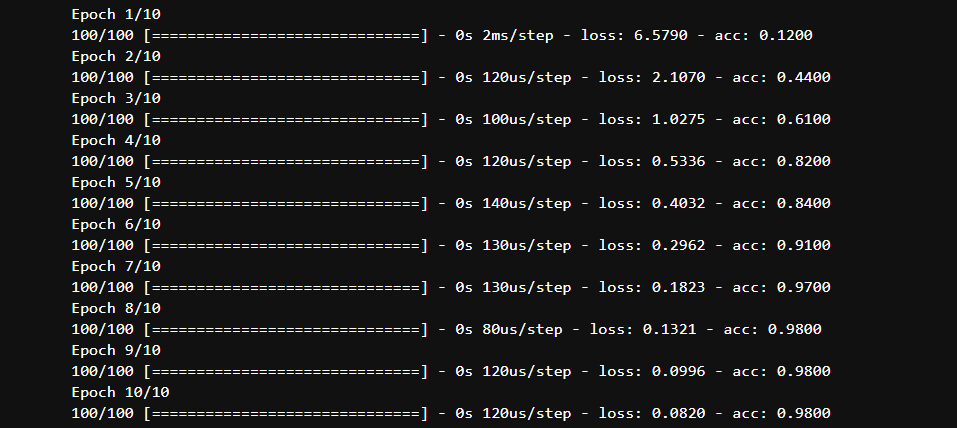
训练误差
测试
训练完毕后就是在自己的测试数据上跑一跑,evaluate以下,同样用VGG16计算测试集的输出,将输出带入自定义网络进行预测,和标准数据对比。1
2
3
4
5
6
7
8test_feature = base_model.predict(x_test, batch_size=32)
print(test_feature.shape)
x_test_feature = test_feature.reshape(10, 512)
y_test_label = keras.utils.to_categorical(y_test, num_classes=10)
score = model.evaluate(x_test_feature, y_test_label, batch_size=32)
结语
实际上socre的得分不是很好,测试集上的准确率只有60%。这说明了什么呢?训练集的误差小,测试集的误差很大,归结下原因:
- 对数据集的筛选,导致了训练集和测试集的来源不同,也就是测试集里面的数据网络没见过。
- 个人认为不是网络的原因,因为训练集的误差很小。就算是过拟合也是由样本太少导致的。

