感觉一篇博客写太长也不是很好,所以把RNN拆成了两部分,在描述了经典的RNN结构之后,再来看看为了满足实际应用,RNN结构所作出的变化和适应。
本文收录内容:
- 双向循环神经网络
- 深层的RNN模型
- 序列化与注意力
还是在实际的背景下对于这些概念的理解,或者说是为了满足实际背景而产生了这些观念,学会变通和利用已有的知识进行问题转换。
双向RNN
背景描述,来看下面的句子:
The mountain is four kilometers above sea level which named TEST
大概意思是TEST山的海拔是四千米,当做提问模型的时候,问题是TEST mountain height is:,显然,对于RNN而言,需要了解前文的信息高度,和后文的信息名称,也就是需要综合考虑前后文的信息,这个时候,双向RNN问世了。
此时的网络结构为:
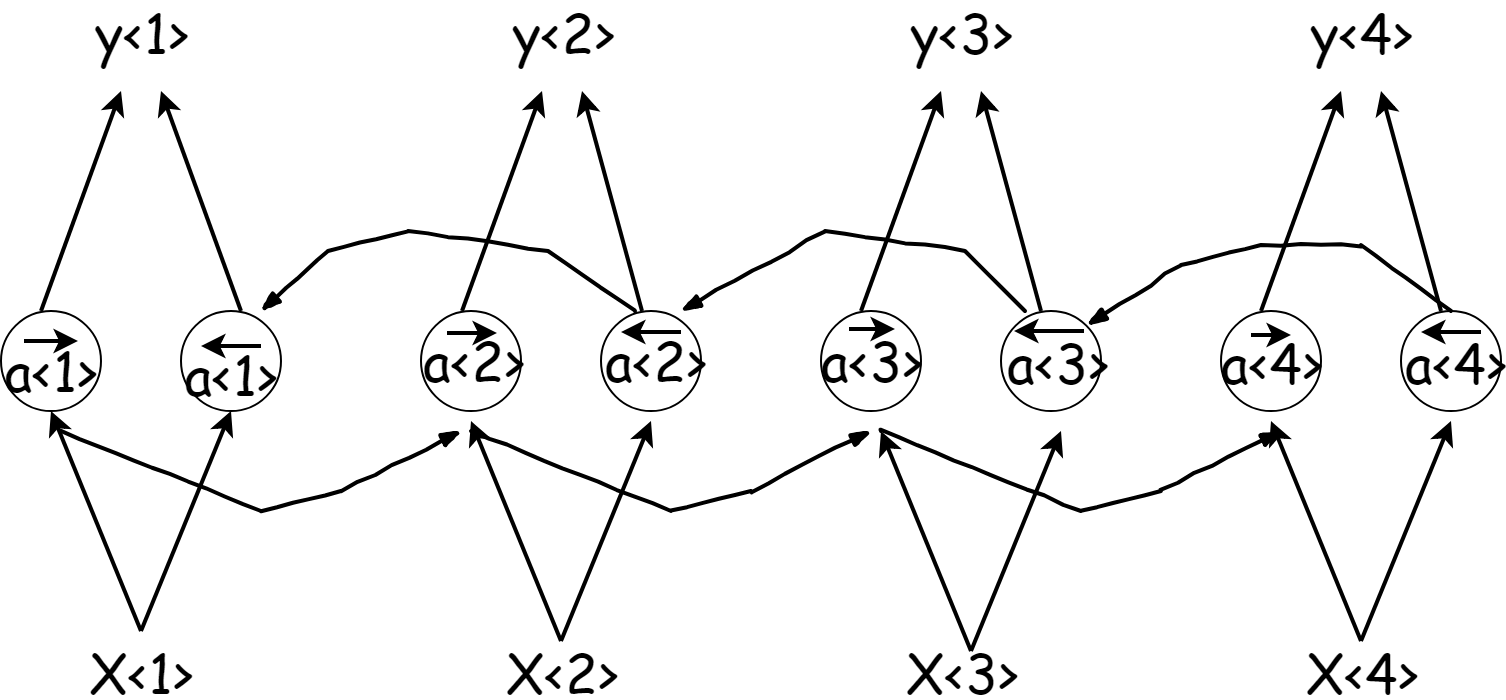
即在正向传播的过程中会有中间信息$\overrightarrow{a^t}$,此时加入一个反向行走的信息$\overleftarrow{a^t}$,(我先吐槽一下mathjax真丑,功能不够强大)。当然俩个$a$和两个$a$所用的参数是不一样的,在预测$y$的时候,加入两个$a$的信息:
简单的kears实现:1
2
3
4
5
6
7
8
9
10
11from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.layers import Embedding
from keras.layers import LSTM
model = Sequential()
model.add(Bidirectional(LSTM(10, return_sequences=True), input_shape=(5, 10)))
model.add(Bidirectional(LSTM(10)))
model.add(Dense(5))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
深层RNN
这个时候总有些闲的蛋疼的人觉得原版的RNN不够舒服,想要去加深RNN的层数来追求精度(装x)效果。
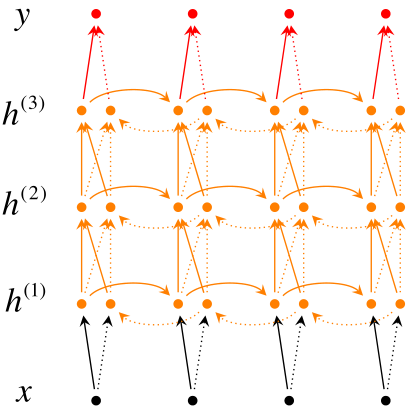
其实加入三个相互连接的层参数已经不少了,能达到绝大部分人的需求。
如果还想加深,那就么就是在单个输出的后面堆叠各种层,但是在后面堆叠的层中,第一个单词的层和第二个单词的层相互之间没有联系了,也就是三层之后的层中就没有$a$了,只是的单独的训练参数和预测。
注意力机制
在机器翻译的过程中,或者说在人工阅读文本的过程中,更倾向的是阅读一小段文本然后翻译一小段,很少去翻译很长的句子,或者说在阅读的过程中,阅读下面的句子肯定很少记得上上文的信息。这就是注意力机制,把注意力放在附近的句子中,而不用注意很远的信息。
也就是,附近单词的注意力权重大,而距离越远的单词注意力权重越小。而且每个单词和每个单词所用的权重也是不一样的。
通俗理解:对每一个单词设立权重$\alpha$,对第一个单词而言,第一个单词与另外所有的单词$t$应该满足$\alpha_{11}$到$\alpha_{1t}$的和是1,然后第一次的记忆信息$c_1$为:
为了满足记忆力的权重之和为1,借鉴softmax的处理方式,以$t$表示第$t$个输入的单词,$T$表述输入单词的长度,以$x$表示第$t$个单词和另外$x$个单词之间的联系:
而$\mathrm{exp}(e_{t,x})$是由另外的全连接层$F$训练而来,$F$的输入为上时刻隐藏层的未激活值,即$\hat{y}$之前的值,和这一层的信息值$a_t$。即:
在不断的训练后,计算出权重$\alpha_{t,x}$之后,就可以为所欲为啦~

