开学前的瞎折腾第二弹,爬取博客数据,分析作者喜好。
在写这个的时候,突然想起来开学的英文单词怎么说来?百度翻译居然是open school,我自己瞎翻译的school start,话说正确的翻译应该是啥。
然后还是闲的没事开始写起了爬虫,恩,记得是上Web 编程课的时候没兴趣听,自己开始在下面瞎鼓捣爬虫技术,当时爬了几个小例子但是也没搞太明白,不如实战一下。
回归正题,本文收录内容:使用爬虫爬取我自己的博客,当然给出最通用的爬虫分析和程序,内容如下:
博客的主要发表时间
博客的数量,标题;
标签的数量种类,用户偏好等
使用matplotlib粗暴的绘图分析一下
因不蒜子暂时没有开放第三方的API,所以没办法爬取每篇博客的访问量,分析博主哪类文章写的比较受欢迎,等不蒜子开放API后再来完善此工作。
注意,以下python程序最好在jupyter lab中运行,写一句看一句,而且后面的程序还会用到前面的变量。
爬虫 我最通俗的理解,一个程序,这个程序将想要访问的网址(一个或多个)下载下来,然后解析一下网址内容,获取里面想要的数据。当然也可能自己在海量的网页里手动下载数据,那么我在这里祝你长命百岁。
上面提到了两个概念,下载网页内容和解析网页内容,这个时候python依靠强大的计算生态很好的完成了任务,目前比较受欢迎的下载请求库为requests,解析库为BeautifulSoup。
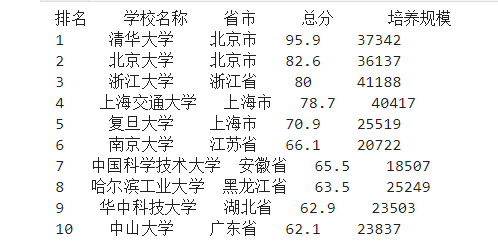
一个简单的例子,在中国大学排名网中爬取前十名的学校。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import requestsfrom bs4 import BeautifulSoupallUniv = [] def getHTMLText (url ): ''' encoding是编码方式 status_code属性是返回状态,200正常,404失败 text是文本对应页面内容 raise_for_status()是方法,与status_code相同 timeout是请求超时时间 get主要是获得数据 ''' try : r = requests.get(url, timeout=30 ) r.raise_for_status() r.encoding = 'utf-8' return r.text except : return "" def fillUnivList (soup ): data = soup.find_all('tr' ) for tr in data: ltd = tr.find_all('td' ) if len (ltd) == 0 : continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList (num ): print ("{:^4}{:^10}{:^5}{:^8}{:^10}" .format ("排名" ,"学校名称" ,"省市" ,"总分" ,"培养规模" )) for i in range (num): u = allUniv[i] print ("{:^4}{:^10}{:^5}{:^8}{:^10}" .format (u[0 ],u[1 ],u[2 ],u[3 ],u[6 ])) def main (): url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html' html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser" ) fillUnivList(soup) printUnivList(10 ) main()
结果如下:
爬取标题 先访问(下载)一下:1 2 3 4 import requestshome_url = "https://muyuuuu.github.io/" from bs4 import BeautifulSoupr = requests.get(home_url)
访问成功后开始解析,访问不成功的话,抱歉我不知道怎么解决。
1 soup = BeautifulSoup(r.text, "lxml" )
接下来借助正则表达式,来爬取博客的标题:
1 2 3 4 5 6 7 8 import rep_ = re.compile ('<[^>]+>' ) blog_title = p_.sub("" , str (soup.title)) print (str (home_url) + 'Blog Title is : \n' + str (blog_title))print (soup.title)
输出如下:
爬取标签 在我的博客中,标签页是使用tags命名的,如果标签页不一样记得修改。
1 tags_url = home_url + r'tags/'
然后开始访问标签页和解析:
1 2 3 r_tags = requests.get(tags_url) soup = BeautifulSoup(r_tags.text, "lxml" ) body = soup.body
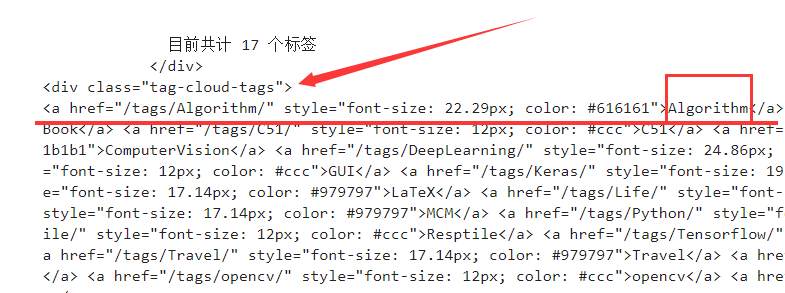
爬取标签数量 然后我们查看body中的内容,发现所有的标签是这样的,标签都位于div中类名是tag-cloud-tags里面,然后还需要获取标签的内容:标签都位于tag-cloud-tags中的a部分。图太大了,没截全。
然后就毫不留情的获取这里的内容,看看这里有几个标签:
1 2 3 data = body.find('div' , {'class' :'tag-cloud-tags' }) a = data.find_all('a' ) print (str (home_url) + 'Blog tag number : ' + str (len (a)))
输出:
爬取标签内容 首先我们来看看a里面的内容都是啥:
1 2 3 tag_size = [] tag_name = [] print (a[0 ])
如果是这样的话,接着用上面的p_正则表达式去除尖括号,留下的就是标签内容啦:
1 2 3 4 5 p_ = re.compile ('<[^>]+>' ) for i in range (len (a)): tag_name.append(p_.sub("" , str (a[i]))) print (tag_name)
然后细心的会发现,在hexo-next主题中,标签字的大小能体现出标签的数量多少,比如在上面的a中,我们发现,Algorithm的字体大小是22.29px,C51的大小是12px,因为我经常写算法的文章,自从参加完比赛写了个小车后就没碰过C51,所以C51的标签就比较少。
接着利用正则表达式匹配出这些数字来:
1 2 3 4 5 p_size = re.compile ('\s\d{2}.*px' ) tag_size = [] for i in range (len (a)): tag_size.append(p_size.findall(str (a[i]))) print (tag_size)
发现这么处理都是字符串加列表,不利于后面写代码,稍微预处理一下:
1 2 3 4 5 6 test = re.compile (r'\d+\.?\d+' ) for i in range (len (tag_size)): tag_size[i] = (test.findall(str (tag_size[i][0 ]))) for i in range (len (tag_size)): tag_size[i] = float (tag_size[i][0 ])
然后一切正常:
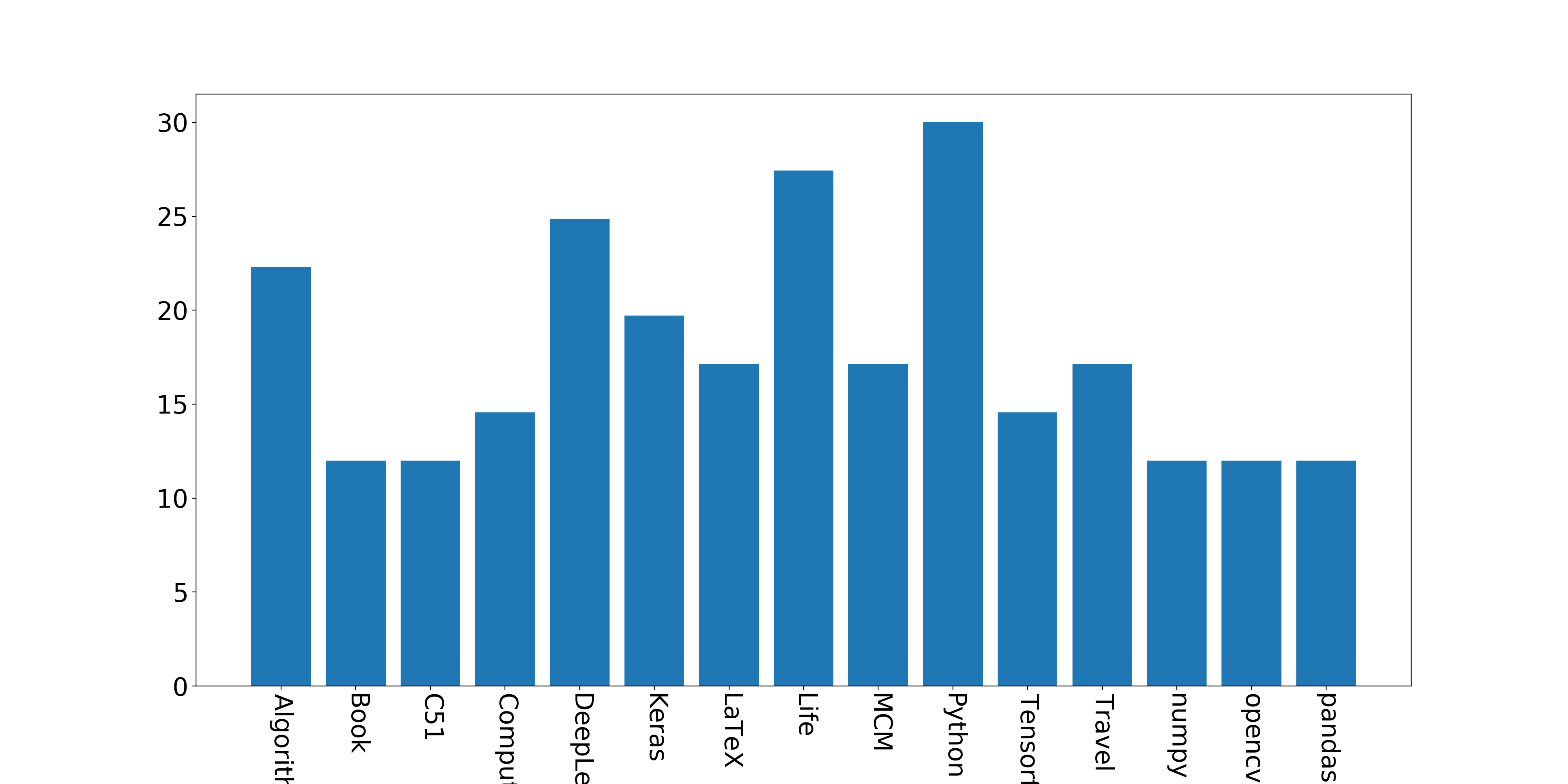
接下来画个图,统计一下标签:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import matplotlib.pyplot as plt name_list = tag_name num_list = tag_size plt.figure(figsize=(20 , 10 )) plt.bar(range (len (num_list)), num_list, width=0.8 , tick_label=name_list) font2 = { 'weight' : 'normal' ,'size' : 30 ,} plt.tick_params(labelsize=23 ) plt.xticks(rotation=270 ) plt.savefig('test.png' , dpi=200 )
分析结果如下:
爬取时间 在我的hexo-next主题下的博客中,使用了创建时间和更新时间,所以我能爬取到我每个博客的创建时间,如果博客没有创建时间的这个接口的话,就别瞎折腾了。
而且,每篇博客的创建时间在当前主页面中都有,也就是打开我博客第一页,第二页也好,都会发现五篇博客的创建时间。
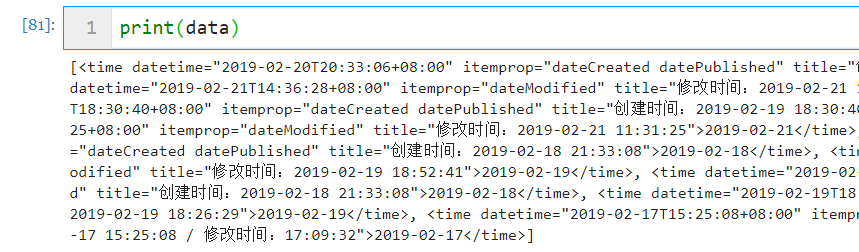
同样,查看home_url返回的解析内容,发现创建时间位于time标签下:
1 2 3 4 5 6 r = requests.get(home_url) soup = BeautifulSoup(r.text, "lxml" ) body = soup.body data = body.find_all('time' ) print (data)
然后利用正则表达式匹配创建时间:
1 2 3 4 publish_time = [] time = re.compile ('创建时间:\d{4}-\d{2}-\d{2}' ) publish_time.extend(time.findall(str (data))) print (publish_time)
爬取博客数量 因为目前我的博客页数为6页,每页最多5篇博客,所以,我需要让程序模拟人的行为,自动点击下一页,一共爬取这六页博客中的创建时间:
1 2 3 4 5 6 7 8 9 for page in range (2 , 7 ): url = home_url + r'/page/' + str (page) + r'/' r = requests.get(url) soup = BeautifulSoup(r.text, "lxml" ) body = soup.body data = body.find_all('time' ) publish_time.extend(time.findall(str (data))) print (publish_time)
根据博客的创建时间,就能得到博客的数量(一个博客肯定,只能对应一个创建时间):
分析时间因素 然后就开始统计,博主经常在哪年哪月经常发博客了,其实上面对时间的正则匹配上,亦可以多匹配出时间点,就能分析出博主经常在几点发博客了,是上午发,下午发,还是标准的夜猫子。
1 2 3 time_sub = re.compile (r'创建时间:' ) for i in range (len (publish_time)): publish_time[i] = time_sub.sub("" , publish_time[i])
然后就从上面的结果中分离出年份和月份。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 year = [] month = [] year_pattern = re.compile (r'\d{4}' ) month_pattern = re.compile (r'-\d{2}-' ) month_sub = re.compile (r'-' ) for date in range (len (publish_time)): year.extend(year_pattern.findall(publish_time[date])) month.extend(month_pattern.findall(publish_time[date])) for date in range (len (month)): month[date] = month_sub.sub("" ,month[date]) year = list (map (eval , year)) month = list (map (int , month))
然后就开始数据分析专场的开车了,是时候导入pandas了:
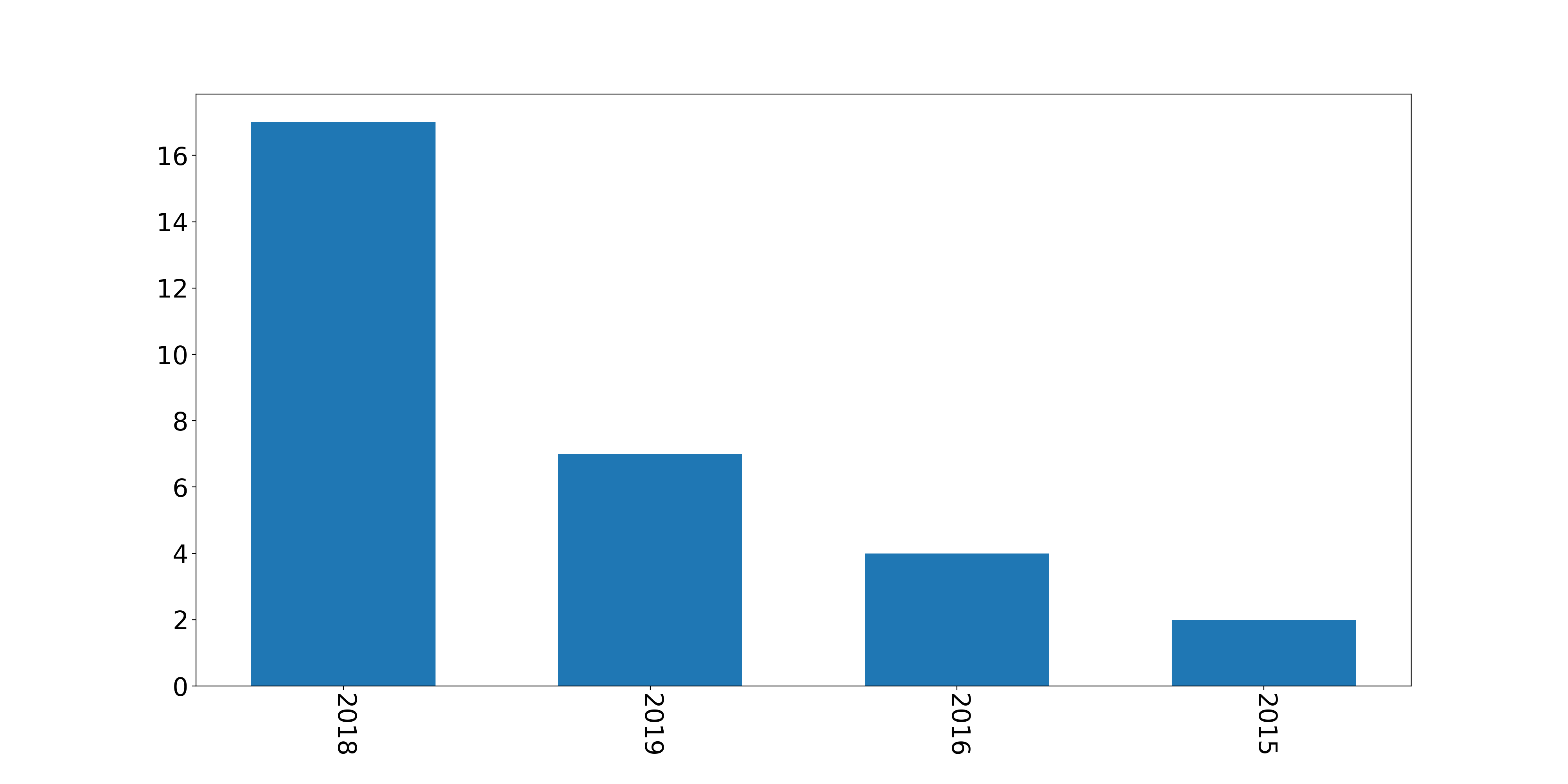
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import pandas as pdyear_result = pd.value_counts(year) name_list = year_result.index num_list = year_result.values plt.figure(figsize=(20 , 10 )) plt.bar(range (len (num_list)), num_list, width=0.6 , tick_label=name_list) font2 = { 'weight' : 'normal' ,'size' : 30 ,} plt.tick_params(labelsize=23 ) plt.xticks(rotation=270 ) plt.savefig('test1.png' , dpi=200 )
没错,我2018年9月搭建的博客,所以目前2018年的博客数量最多。
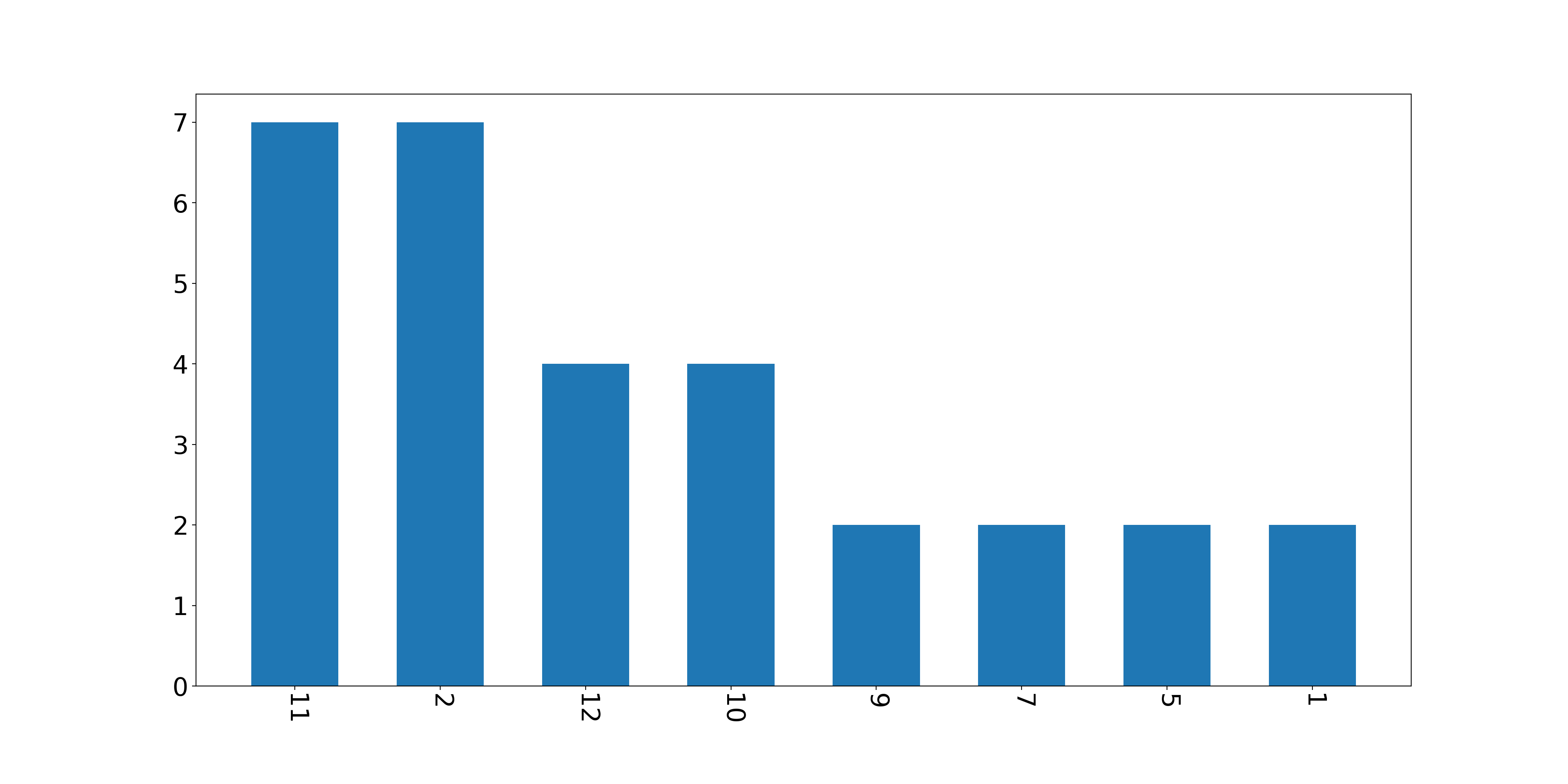
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 month_result = pd.value_counts(month) name_list = month_result.index num_list = month_result.values plt.figure(figsize=(20 , 10 )) plt.bar(range (len (num_list)), num_list, width=0.6 , tick_label=name_list) font2 = { 'weight' : 'normal' ,'size' : 30 ,} plt.tick_params(labelsize=23 ) plt.xticks(rotation=270 ) plt.savefig('test2.png' , dpi=200 )
看来目前集中在秋冬两季写博客。
结语 留下三个坑等自己填吧:
在时间分析的角度,可以更换正则表达式匹配,匹配出时间点,分析博主经常在几点发博客,进而分析作息规律。(貌似又回到了数据分析的老本行)
等待不蒜子开放第三方API,爬取每篇博客的访问人数,就能知道博主写的哪方面的博客最受欢迎了。
分析每篇博客的创建时间和更新时间,能够反映出博主对博客的维护程度与热爱与否。
其实爬虫更像是数据结构的过程,先查看网页源代码,分析网页的结构,利用库解析结构后,怎么导出数据就看自己编程功底了。又是在变相的考察数据结构这个计算机的送命课。