在上个世纪,规则派的思想制约了自然语言处理的发展。比如主语后面是谓语,还有各种时态规则,加上当时并不是很强大的处理器,自然语言处理根本做不起来。在编译原理中,即使只有很少的语法,处理起来也很困难,更别说要规则话自然语言的语法了。那么统计派的学者登上历史舞台,解决了这个问题,甚至可以说是开创了现代人工智能世界的大门。
起初并不对NLP的东西感兴趣,但是还是回归思想。数学和计算机的应用层出不穷,但背后的数学思维值得学习和借鉴。本文收录:
- 简单分词(基于维特比算法)
- 统计语言模型
- 词嵌入模型:负采样、Word2Vec,Skip Gram等
其实我总在思考,感觉编译原理中对句法成分分析的东西也不是不能用到NLP中,不过最近事太多了,有时间再去研究吧。应该有前人的研究成果的,到时候读论文先。
分词
首先,对于一个句子:“燕山大学生”,是分为燕山大学-生呢还是燕山-大学生呢?显然有二义性。二义性的句子还是靠后来的统计模型加以解决。(猜想:是不是现实世界过于灵活的东西都不能加太多的限制规则)。假设有两种分词方法,第一种是$A$,第二种是其他的分词方法$B$。对于两种分词方式,计算其产生句子的概率:$P(A)>P(B)$,那么就认为$A$的分词方法是最好的。
如何计算出来生成句子的概率来比较大小呢?当然是统计模型和维特比算法。
统计语言模型
借助马尔可夫性(一个假设,此时刻状态只与上一时刻状态相关,即今天的天气只与昨天的天气有关)。假设一个词$w_i$出现的概率只与前一个词$w_{i-1}$相关。那么一个句子$S$出现的概率就是$P(S)=P(w_1)\cdot P(w_2|w_1)\cdot P(w_3|w_2)\cdots P(w_n|w_{n-1})$。现在来看这个联合概率分布$P(w_n|w_{n-1})$和边缘概率分布$P(w_n)$呢?开始统计。当数据量足够大的时候,我们可以认为出现的频率就是事件发生的概率。$P(w_i)$就是$w_i$这个词出现的频率,$P(w_n|w_{n-1})$就是这两个词一起出现的频率。既然得到了词出现的概率,在计算句子出现的概率就不难了。之后就能轻易的确定出最好的分词方法。
维特比算法
但是,不能穷举所有分词情况下每个句子出现的概率,过于复杂。比如一次分词就判断一下,一次分词就判断一下还是很复杂的。这个时候就有维特比算法了,算法的核心思想是动态规划,不过这个算法最初是用来解决通信领域的问题,现在被用在了求最短路径、导航等领域。
算法的核心思想:可能会有多种分词,每次分词导致的结果还不同,就会得到下图的一个网络。每个分词的区域都是一个网络的岔路口。
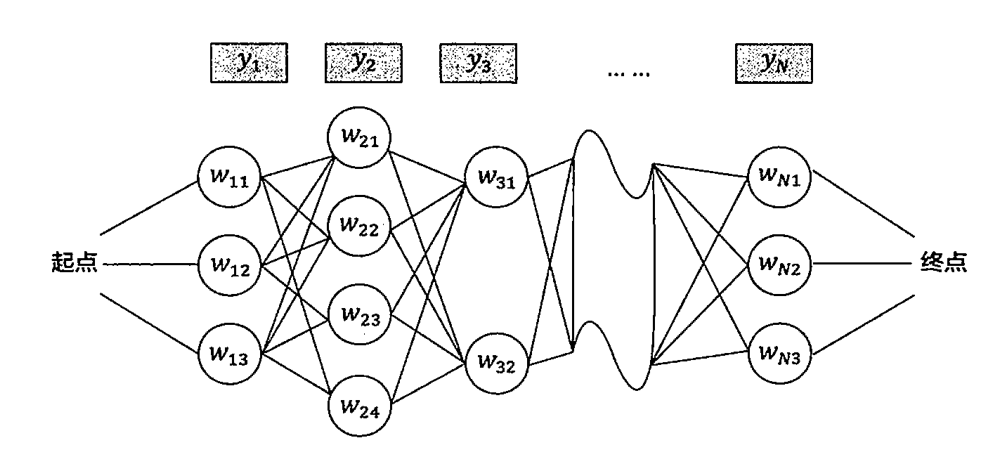
首先:如果从S到O的最短路径经过了A,那么S到A的路径也一定是最短的。否则可以选出另外一条最短路径代替SA。
其次:好了没其次了。看算法吧。
起点设为$S$,第一个状态有三个节点,对应三种分词情况。计算$S$到它们的距离$d(S,w_{1n})$,对于第二个状态的节点$w_2$,从$S$到状态2的路径必经过状态1,对应的路径长度是$d(S,w_2)=d(S,w_1)+d(w_1,w_2)$,然后一个暴力破解找个最小值,就是必须经过的状态1的节点。之后同理,到状态3的时候就能确定出经过哪一个状态2的节点。循环往复,就能求出起点到重点的最短路径,也确定了最好的分词方案。
时间复杂度分析:节点最多有$D$个状态,句子的长度是$N$,那么时间复杂度是$O(N^2\cdot D)$。也就是对于一个很复杂的句子,当每一步分词有10种情况,句子长度为10,1000次计算对CPU而言是小儿科,无论句子多复杂,分词永远都是瞬时的。
对了,这个算法也用在了输入法上,就是一边打字一边出结果的那种。输入拼音 “nihao”,输入法提示的内容是“你好”,拼音”ni”有好多字,拼音”hao”也对应好多字。只需要选择一种最为可能的方案即可,而这个方案也不是遍历所有的”ni”, “hao”情况输出的,而是用了动态规划的思想降低了时间复杂度。这也是一个典型的维特比算法的应用。

Word2Vec
词嵌入模型
有了前文的基础后,有循环神经网络的基础就更好了,开始更深入的自然语言处理。
在之前提到的循环神经网络解决翻译、推测的博客中,都是使用的one-hot作为输入。当然结果也是能看的,那么对于一个输入:apple candy,现在把apple换成orange,那么是不是还能推理出candy呢?基本不能,为啥呢,因为apple和orange的one-hot的距离相差太大,神经网络可能学习不到这么大跨度的距离。
这时候如果有个表就好了,在这个表里面每个单词都有自己的300维特征向量。apple有自己的特征向量,orange有自己的特征向量。这两个特征向量距离很近,但是与Iron这个词的特征向量又很远。总之是现实中相似物体词汇的特征向量接近,八杆子打不着的物体词汇的特征向量距离就远。那么就能很轻易的从apple candy推导出orange candy。那么这个表就叫做词嵌入(embedded)表,如何求这个词潜入表呢?目前有多种方案。
为什么叫词嵌入呢,因为词嵌入表的作用就是把这个词赋予了一个多维的向量,比如300维,那么这个词就嵌入在一个300维的空间里。
传统方案
首先,记词嵌入表为$E$,假设有1000个词和想生成300维特征,先随机生成$E$,维度是$300\times 1000$。则对于一个one-hot编码,$E\cdot O=e$,即嵌入表乘以一个词的one-hot得到这个词的特征向量,而所有词的特征向量组成嵌入词表。此时一个只能推断的任务:I want a glass orange candy,candy是需要推断的内容。
那么我们先把 I, want, a, glass, orange的$e$给求出来(glass 的 $e$ 求法为:$E\cdot O_{\mathrm{glass}}$,$O_{glass}$是glass的one-hot编码)。把5个$e$扔给一个softmax单元,希望的输出为juice。反向传播,训练这个网络直到误差逐渐的减小,最后得到想要的$E$。
这个时候把orange换成apple,因为apple和orange的$e$很接近,很容易从orange candy 推导出 apple candy了。
Skip Gram
给定一个句子:”Black Widow is a playable character in Lego Marvel’s Avengers, voiced by Scarlett Johansson.”从中选择一个单词作为上下文context,在正负五个单词内选择target, 建立一个监督学习的模型,建立从context到target的映射,这个网络的规模就会比上一个算法的规模小一点。
交叉熵计算误差时还是使用的one-hot编码。
这里的softmax是有参数的:
负采样
和Skip Gram算法类似,先来一个句子:”Avengers Assemble is an American animated television series based on the fictional Marvel Comics superhero team known as the Avengers”。
随机选择一个词汇,比如avengers, 在选择它的下一个词汇Assemble,这个映射关系就是正样本。在随机从牛津字典里面选取五个单词,比如“organized”,“cup”作为负样本。继续一个神经网络的拟合:$P(y=1|c,t)$。
在$\hat{y}$的过程中,输出维度取决于单词的数量,如果有1000个单词,那么我们之训练6个节点,1个是正样本的,另外5个是选择的负样本的。一波训练之后求出$E$。
情感分类
以现在常见的影评为例:“这是哪个智障导演拍出来的无剧情无主线,无病呻吟的破电影”,让后评分是一个星。对于此类的数据,我们可以用每个词汇的$e$,作为循环神经网络的输入,规定这个网络的输出是星的数量。在大量的数据训练下,我们会得到对于一个评论进行分级,进而确定大家对这个电影的评论好坏。
只要还有类似的评论,就很快的能从评分数量的角度来数字量化好坏程度。
类比推理
继续,man相对与doctor, 等于woman相当于什么。我们只需要在选择一个向量$e_x$,使下式成立:
然后把这个$x$向量求出来即可。但是,为了消除性别歧视,doctor相对于man,那么woman的结果也应该是doctor。所以在训练结束后,形如性别类、种族类的词汇还需要进一步处理。比如对于性别而言,需要消除在性别方向上的差异。
形如,我们知道了男人的特征向量$e_{man}$和女人的特征向量$e_{woman}$,将这两个向量相减,可以认为差异最大的那一维有性别的成分。然后平均一下那个温度上的差异就可以啦。


