往一个领域里走的越深,发现设计的知识越多越难(主要是自己知识过于贫瘠),虽然我很确信我还处于很浅的位置。今天又鼓捣了一天,发现涉及的内容太多了,一个文章放不下,还是单独成文,组成一个系列?算了,先整理下所学知识吧。
通过关系让不同表的字段之间建立联系,比如用外键去约束另一个表字段的取值,而这在实际开发中也是很常见的东西。
对两个表创立了联系,这样查询和操作起来也会方便很多:只在表中声明表之间的关系,之后每次使用就完全无需手动交叉搜索,而是像对待一个表中的数据一样直接使用。
参考 relation 相关代码的参考 这篇文章写的不错的。
完整代码链接 https://github.com/muyuuuu/SQLAlchemy/tree/master/SQLAlchemy/relation
建议参考全部代码进行学习。
外键 外键是在A表中存储B表的主键,以便和B表建立联系的关系字段,且外键只能存储单一的数据。如:
1 2 A表:学号,姓名,专业 B表:课程号,成绩,学号
那么B表的学号是B表的外键,能确定A表唯一的学生,且取值受限于A表。
一对多关系 比如一个作者可以写多篇文章,一个文章只能属于一个作者(不考虑科技论文的第一作者、第二作者等),我们想查询一个作者的所有文章。
如上,外键只能存储单一数据,所以外键要定义在多这一侧,所以外键定义在文章表内。
而关系属性在出发侧定义,所以关系定义在作者表内。代码如下(连接数据库那部分的就不写了,详情参考这里 ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Author (Base ): __tablename__ = 'authors' id = Column(Integer, primary_key=True ) username = Column(String(64 ), index=True ) email = Column(String(64 ), unique=True ) to_articles = relationship('Article' ) class Article (Base ): __tablename__ = 'articles' id = Column(Integer, primary_key=True ) title = Column(String(50 ), index=True ) body = Column(Text) author_id = Column(Integer, ForeignKey('authors.id' ))
注意事项:
authors.id 中的 authors 是表名,id是那个类里面的属性。relationship 定义了一个属性,参数为对应的要联系表的类名。
在作者数据表中,没有使用Column去定义文章这一栏,是因为relation会将Author类和Article类建立联系,这个关系被调用时,会在关系的另一侧article内的外键字段内,查找所有外键字段为当前查询值(author表的主键id),并返回查询结果,即对应该作者的多篇文章。
写入实例 1 2 3 4 5 6 7 lanling = Author(username = 'lanling' , email = 'lanling@gmail.com' ) test1 = Article(title = 'test1' , body = 'asdasdasd' ) test2 = Article(title = 'test2' , body = 'eiubfefvwiev' ) session.add(lanling) session.add(test1) session.add(test2) session.commit()
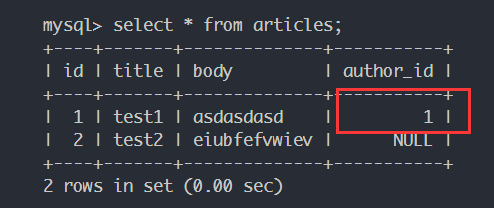
建立联系 从多的一侧建立联系 设立当前文章的作者的id是1:
1 2 test1.author_id = 1 session.commit()
查看数据库端的更改:
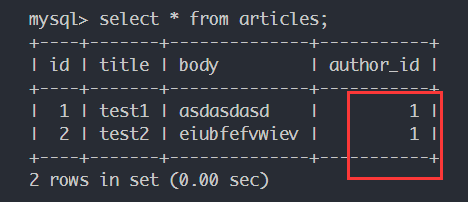
从少的一侧建立联系 给lanling作者追加一篇文章:(lanling作者的id是1)
1 2 lanling.to_articles.append(test2) session.commit()
再次查看数据库内是否修改:
可以看到两篇文章的author_id表示作者都是lanling。
查看联系结果 1 2 3 4 5 6 7 a = session.query(Author).filter (Author.id == 1 ) print (a[0 ].username)for i in lanling.to_articles: print (i.title) print (test1.author_id)for i in lanling.to_articles: print (i.body)
输出:
1 2 3 4 5 6 lanling test1 test2 1 asdasdasd eiubfefvwiev
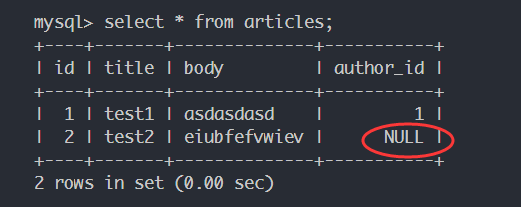
移除关系 在一这一侧直接remove即可。
1 2 3 4 5 lanling.to_articles.remove(test2) session.commit() for i in lanling.to_articles: print (i.body)
数据库端情况:(之后的创建实例、设置关系的操作均会影响数据库端,所以不再重复展示)。
输出:
建立双向联系 在两侧都添加关系属性,用于获取对方记录的关系称为双向关系。
比如:查询一个作者写了哪些书,查询书的作者是谁这样的双向查询。但在多的一侧,返回值是一个数据,即一本书的作者只能是单个人,不能以列表的形式去访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Writer (Base ): __tablename__ = 'writers' id = Column(Integer, primary_key=True , index=True ) name = Column(String(10 )) books = relationship('Book' , back_populates='writers' ) class Book (Base ): __tablename__ = 'books' id = Column(Integer, primary_key=True , index=True ) publish = Column(String(10 )) writer_id = Column(Integer, ForeignKey('writers.id' )) writers = relationship('Writer' , back_populates='books' )
其中back_populates用来连接对方,不连接只是简单的增加一个属性,操作关系的一方并不会影响另一方,但连接双方后,操作关系的一方,涉及到的另一方也会跟随变。
且参数必须严格设置为关系另一侧的类的属性值。
Writer类的relationship属性名books,必须对应Book类的关系中的back_populates中的值。
加入实例:
1 2 3 4 5 6 7 muyu = Writer(name='muyu' ) test1 = Book(publish='asde' ) test2 = Book(publish='fwf' ) session.add(muyu) session.add(test1) session.add(test2) session.commit()
建立关系:
1 2 3 4 5 6 test1.writers = muyu print (test1.writers.name) for i in muyu.books: print (i.publish)
1 2 3 4 5 test2.writers = muyu print (test2.writers.name)for i in muyu.books: print (i.publish)
输出:
因为设置了双向关系,所以将某个book的writer属性设为None,就会解除对应 Writer 对象的关系,此时在 writer 方查询,并不会查询到对应的 book 信息。
1 2 3 test2.writers = None for i in muyu.books: print (i.publish)
只输出:asde。
一对一关系 一个丈夫有一个妻子,一个妻子有一个丈夫,用这个例子吧(不考虑重婚和离婚)。此处不建立双向关系,与上个例子不同的是需要加入uselist=False。
1 2 3 4 5 6 7 8 9 10 11 12 13 class husband (Base ): __tablename__ = 'husband' id = Column(Integer, primary_key=True ) name = Column(String(10 )) wife = relationship('wife' , uselist=False ) class wife (Base ): __tablename__ = 'wife' id = Column(Integer, primary_key=True ) name = Column(String(10 )) husband_id = Column(Integer, ForeignKey('husband.id' )) husband = relationship('husband' , uselist=False )
加入实例 1 2 3 4 5 6 7 8 9 10 11 12 name1 = husband(name='name1' ) name2 = husband(name='name2' ) name3 = wife(name='name3' ) name4 = wife(name='name4' ) session.add(name1) session.add(name2) session.add(name3) session.add(name4) session.commit()
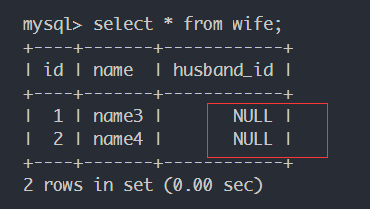
建立联系 1 2 name1.wife = name3 name2.wife = name4
查看联系的结果:
此外,即使在表内建立了联系,而不执行session.commit(),联系的更改不会提交的数据库:
而在最后执行session.commit()后,更改会提交到数据库:
多对多联系 一个学生有多个老师,一个老师有多个学生,以这个例子说明。
在多对多关系中,每一个记录都可以与关系另一侧的多个记录建立关系,而不是一个。所以需要把多对多分拆成两个一对多关系。做法是:新创建一个表,专门存储映射关系。原本的两个表无需设置任何外键。
关系表一定要写在数据表前面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 assocation_table = Table('association' , Base.metadata, Column('stu_id' , Integer, ForeignKey('students.id' )), Column('teach_id' , Integer, ForeignKey('teachers.id' )), ) class Student (Base ): __tablename__ = 'students' id = Column(Integer, primary_key=True ) name = Column(String(10 )) teachers = relationship('Teacher' , secondary=assocation_table, back_populates='students' ) class Teacher (Base ): __tablename__ = 'teachers' id = Column(Integer, primary_key=True ) name = Column(String(10 )) students = relationship('Student' , secondary=assocation_table, back_populates='teachers' )
创建实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 stu1 = Student(name='name1' ) stu2 = Student(name='name2' ) stu3 = Student(name='name3' ) stu4 = Student(name='name4' ) teach1 = Teacher(name='teach1' ) teach2 = Teacher(name='teach2' ) teach3 = Teacher(name='teach3' ) teach4 = Teacher(name='teach4' ) session.add(stu1) session.add(stu2) session.add(stu3) session.add(stu4) session.add(teach1) session.add(teach2) session.add(teach3) session.add(teach4) session.commit()
建立联系 同样,要使用append和remove去添加和删除。stu1 有两个老师,teach2 有 两个学生。
1 2 3 4 5 6 7 8 stu1.teachers.append(teach1) stu1.teachers.append(teach2) teach2.students.append(stu3) for i in teach2.students: print (i.name) for j in i.teachers: print (j.name)
输出1 2 3 4 5 name1 teach1 teach2 name3 teach2
结语 感觉我还是描述的有些混乱,且,建议参考全部代码 进行练习。