数据表并不是一成不变的,添加新的模型类或者给已有的模型类添加删除属性都是很正常的事情,此时都需要更新表。而只修改原有代码的表,重新部署是不能生效的,原因是那个表已经存在了。
举一个苛刻的例子:你的老板说,我们不要时间戳这个属性,你说好,写好代码并用了一年。一年后,你的老板说,把时间戳给我加上。这就涉及到了数据库的迁移。但是又不想:拷贝原有数据、重新建表、复制数据这样的更新,这种工作量很大很累赘,且数据是无价的,所以学会数据库迁移很有必要。
我想起了一个培训班来我们学校上课,说:公司不会给你重启服务器,所以一定要保证一次性把表写对不能更爱,呵,怪不得你的水平也只能来我校讲课。
创建数据表
首先创立数据表,python models.py执行,并提交一个实例。(但这里并不用写提交的代码,只需要写数据表这个类即可,因为在数据库迁移的时候,这个表的内容会被系统自动提交)
1 | from sqlalchemy import Column, Integer, String, Text, Date, Time, create_engine |
可以看到数据库中的记录:
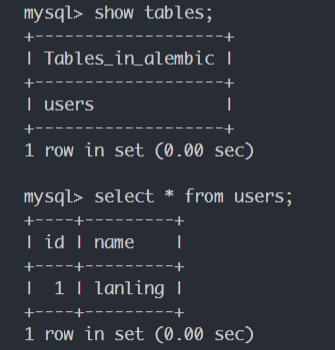
初始化
在models.py目录下执行初始化命令:alembic init migrate,其中的migrate是要初始化的文件夹名称。会得到以下的目录结构:
1 | Alembic |
修改 alembic.ini
我的是MySQL, 其他的DBMS可能不一样,密码,端口,数据库名改成和自己一样的。
1 | sqlalchemy.url = mysql+pymysql://root:MyNewPass@localhost:3306/alembic |
修改 env.py
目标是让 alembic 获取模型模块中定义的信息。我的目录结构的修改方式代码如下,如果代码结构不同,下面代码无法生效。
将target_metadata = None 改为以下代码,
1 | import os |
更新
假设想在数据库内新建一个表,那么先自动创建更新的版本,执行以下命令(字符串里面的是备注信息,随意改):
1 | alembic revision -m "create tables password" |
然后会在命令行内得到提示:生成了一个乱码开头的.py版本文件,在versions文件夹内找到这个文件,手动编写升级操作和降级操作,必须要写降级,万一升级升错了,岂不降不回去。
1 | def upgrade(): |
开始升级
命令行执行:alembic upgrade head,但更新会重新执行models.py里面的内容,所以会有
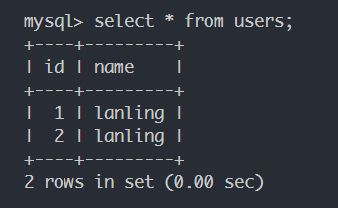
所以建议 models.py 里面只定义和提交,不写入数据。发现已经新建了password这个数据库:
推荐的models.py写法(不用提交和创建实例):
1 | from sqlalchemy import Column, Integer, String, Text, Date, Time, create_engine |
假设我们要给一个表格新加一列,而重启服务器,拷贝原有数据库的数据,在创建新的数据表加入新的一列,在写入新的数据是很猥琐的行为,所以有必要使用数据库迁移。
我们再次创建一个更新版本:
1 | alembic revision -m "add location column in users table" |
同样会在命令行的提示中,得到一个乱码开头的.py更新文件,在文件中编写更新函数:
1 | def upgrade(): |
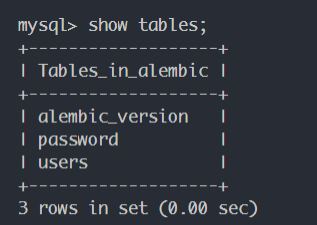
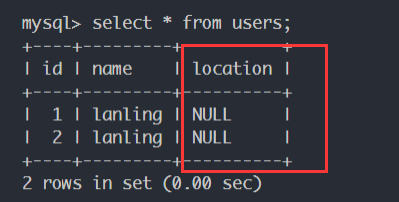
命令行执行:alembic upgrade head开始升级,发现升级成功,而数据库内也做了改动:
本文参考
https://www.cnblogs.com/turingbrain/p/6372086.html
https://zhuanlan.zhihu.com/p/90106173
https://www.cnblogs.com/derek1184405959/p/9100502.html
虽然参考了他们的文章,但是说实话他们写的并不好,我也是看了好多篇文章才终于搞懂如何更新的。
结语
得看一个项目,看看人家怎么写的代码,怎么组织的文件和分工。目前的代码还不够pythonic。如
- 每次会话完是否关闭?
- 数据库的连接次数该怎么设置?(链接次数过多且不释放资源,会严重拉底系统性能)

