作为一个程序员,我发现我不会写多进程和多线程的程序,实在羞愧,在赶完毕业设计后准备开一个多线程编程的坑。本文是我这种小白从无到有的学习收获,内容较多,还请耐心观看。因疫情原因没在学校,手头没有一本靠谱的《操作系统》的书籍,大多东西为网上搜刮而来后整理,可能不严谨。今天有空了回来填坑。
从物理机开始
本文以Linux操作为主,Windows操作不太了解。首先先从物理机出发,了解物理CPU、CPU的核、线程是什么概念。物理CPU指实际存在的CPU处理器,安装在PC主板或服务器上。首先查看物理CPU个数,查看电脑有几个CPU:
1 | grep 'physical id' /proc/CPUinfo | sort -u |
执行结果反馈如下:(后期解释为什么是12个id为0的记录)
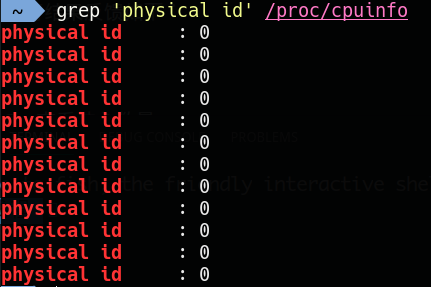
其id均为0,表示我电脑有一个CPU(从0开始编号)。CPU中包含物理内核,比如多核CPU,单核CPU。这个多核或者单核已经集成在CPU内部了,那么来查看一下核心数量,就是买电脑的时候常听商家常说的4核CPU或者8核CPU:
1 | grep 'core id' /proc/CPUinfo | sort -u | wc -l |
我这里输出的结果为6,表示我的是6核CPU。同时,你在买电脑的时候听说过,6核12线程,4核8线程的CPU,那么,再看一下自己的电脑支持几个线程:(说了半天终于到线程了)。
1 | grep 'processor' /proc/CPUinfo | sort -u | wc -l |
输出的结果是12,表示我的电脑的处理器是一个CPU,且是6核心12线程的。所谓的6核12线程,6核指的是物理核心。用Intel的超线程技术(HT, Hyper-threading)将物理核虚拟而成的逻辑处理单元,现在大部分的主机的CPU都在使用HT技术,用一个物理核模拟两个虚拟核,即每个核两个线程,总数为12线程。所以在操作系统看来是12个核,但实际是一个物理CPU中的6个物理内核虚拟出来的12个线程:
此时我们需要知道:一个核心只能同时执行一个线程。
进程与线程的概念
进程
- 进程是操作系统的CPU调度和资源分配的单位,是执行中的程序,是一个程序在一个数据集上的一次执行。是程序的一个实例,程序的一次运行。包括代码段,当前活动(PC,当前要指向指令的地址;堆栈,函数参数、临时变量;数据,全局变量,处理的文件;堆,动态内存分配);
- 程序是进程的代码部分。进程在内存,程序在外存。
当写完一份程序,编译为二进制的可执行文件并执行时:可执行的.exe文件可以理解为一种程序,程序本身也是指令的集合,而进程才是程序(那些指令)的真正运行。程序本身不会运行,运行的程序叫进程。进程会标记程序要访问的地址、要执行的操作等,执行完毕后进程会被销毁。
若干进程有可能与同一个程序有关系,如循序和平行。进程A需要得到进程B的处理结果才能继续运行,所以进程A要等待进程B执行完,这叫循序;进程C和进程D没有关系,这俩可以同时进行,这叫平行。
举个生动的例子:某生产流水线,得先通过质量安检才能包装,所以质量检查和包装这两个进程不能同时进行,有明显的先后顺序,这叫循序;对于没有明显先后顺序的,比如电脑打开两个软件,一个负责聊天,一个负责放音乐,这两个进程毫不相干,所以同一时刻谁先执行谁后执行无所谓的,没有明显的先后顺序,这叫平行。
也许你会问:音乐软件和聊天软件这两个进程不是同一时刻在一起执行吗?其实不是的,计算机只能串行执行不同的进程,即执行进程A的时候不能执行进程B,所以同一时刻,计算机只能执行一个进程。你所谓的边听音乐边聊天,其实是计算机中断实现的。先执行聊天进程,在以极低的间隔切换到音乐进程,只是这个时间间隔短暂,短暂到肉眼无法察觉,你感受不到。所以宏观是并行的,微观是串行的。
当系统内存在的多个进程的时候,操作系统会根据进程的优先级算法来决定先执行谁,后执行谁,A的优先级高,那就先执行A。确定进程的优先级有很多算法,详情参考《操作系统》。以我的电脑为例,启动系统,打开一堆软件,肯定不止12个进程,而多个进程以优先级的形式在仅12个核的CPU上轮番执行,保证系统的有条不紊。
进程也是线程的容器。每一个进程都有一个主线程,一个CPU核心在同一时刻只能执行一个线程。所以,最简单的比喻多线程就像火车的每一节车厢,而进程则是火车。车厢离开火车是无法跑动的,同理火车也不可能只有一节车厢,多线程的出现就是为了提高效率。
总结一下:进程是操作系统进行资源(包括CPU、内存、磁盘IO等)分配的最小单位,而进程中的线程是CPU调度和分配的基本单位。我们打开的聊天工具,浏览器都是一个进程。进程可能有多个子任务,比如聊天工具要接受消息,发送消息,这些子任务就是线程。
而资源分配给进程,且不同进程之间不共享资源,线程共享所在进程的资源。
线程
线程是操作系统调度和CPU执行的基本单位。它被包涵在进程之中,一条线程指的是进程中一个单一顺序的控制流,一个进程中可以有多个线程,每条线程并行执行不同的任务,线程的运行中需要使用计算机的内存资源和CPU。
同一进程中的多条线程将共享该进程中的全部系统资源,如访问数据、地址空间等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread-local storage)。
在多核或多CPU,或支持HT的CPU上使用多线程程序设计的好处是显而易见,即提高了程序的执行吞吐率。多核CPU在毕竟同一时刻跑多个任务,单核CPU同一时刻只能跑一个任务。
总结:进程是资源分配的最小单位,线程是CPU调度的最小单位。线程和进程的区别在于,子进程和父进程有不同的代码和数据空间,而多个线程则共享数据空间,每个线程有自己的执行堆栈和程序计数器为其执行上下文。更多区别:
- 代码角度:进程包含线程,线程是进程中的一段代码;
- 资源角度:进程是资源分配的基本单位,线程得到的资源来自进程,共享使用;
- 调度角度:进程中的线程切换不会引起进程切换,线程是基本调度单位;
- 切换角度:进程切换代价大,线程切换代价小;
- 生命周期:进程撤销会撤销所有线程,线程撤销不会影响进程。
串行、并行、并发
串行:多个任务,执行时一个执行完再执行另一个。比喻:吃完饭再看视频。
并发:多个线程在单个核心运行,同一时间一个线程运行,系统不停切换线程,看起来像同时运行,实际上是线程不停切换。比喻: 一会跑去厨房吃饭,一会跑去客厅看视频。
并行:每个线程分配给独立的核心,线程同时运行。比喻:一边吃饭一边看视频。
在了解完串行、并行、并发的概念后,可以更多的理解多进程和多线程了:
多进程
当你运行一个程序,你就启动了一个进程。在同一个时间里,同一个计算机系统中如果允许两个或两个以上的进程处于运行状态,这便是多任务。
现代的操作系统几乎都是多任务操作系统,能够同时管理多个进程的运行。多任务带来的好处是明显的,比如你可以边听mp3边上网,与此同时甚至可以将下载的文档打印出来,而这些任务之间丝毫不会相互干扰。如果这些任务同时在一个核上运行,这就是并发,如果这些任务分配到了多个核心,这就是并行。
如何实现并发?详情参考《操作系统》,可以粗暴的理解为利用系统中断,根据优先级确定先执行谁。执行A,中断一下去执行B,执行一会儿B,在中断一下返回去执行A,如此循环往复。
并行运行的效率显然高于并发运行,所以在多CPU的计算机中,多任务的效率比较高。同理,如果在多CPU计算机中只运行一个进程(线程),就不能发挥多CPU的优势。
多线程
在计算机编程中,一个基本的概念就是同时对多个任务加以控制。许多程序设计问题都要求程序能够停下手头的工作,改为处理其他一些问题,再返回主进程。
最开始的时候,那些掌握机器低级语言的程序员编写一些中断服务例程,主进程的暂停是通过硬件级的中断实现的。尽管这是一种有用的方法,但编出的程序很难移植,由此造成了另一类的代价高昂问题。中断对那些实时性很强的任务来说是很有必要的。
但对于其他许多问题,只要求将问题划分进入独立运行的程序片断中,程序在逻辑意义上被分割为数个线程,并将数个线程分配给多个核,使整个程序能更迅速地响应用户的请求。多线程是为了同步完成多项任务,即在同一时间需要完成多项任务的时候实现的。假如操作系统本身支持多个处理器,那么每个线程都可分配给一个不同的处理器,真正进入并行运算状态。
从程序设计语言的角度看,多线程操作最有价值的特性之一就是程序员不必关心到底使用了多少个处理器(处理器不够可以并发),可以创建100个线程一起来嘛。

