之前一直在看他们用『因果扩张卷积』这个东西,当时我只看到了一张图,大概了解了那是个什么东西。今天,在某次比赛中用到了这个模型,顺手看了下源代码,来做个整理。
在时序序列的预测问题中,很容易想到LSTM等循环神经网络。给定序列数据,预测下一时刻的输出,如翻译、问答等。
\begin{equation}
p(x)=\prod_{t=1}^T P(x_t|x_{t-1},…,x_1)
\end{equation}
当然也可以有隐藏状态:
\begin{equation}
p(x|h)=\prod_{t=1}^T P(x_t|x_{t-1},…,x_1, h)
\end{equation}
时至今日,也可以用 CNN 来代替这一过程,卷积的输入是历史数据,产生一个时刻的输出。且,相对而言 CNN 的参数要少很多,也可以叠加 CNN 层。需要注意的是,因果扩张卷积包括因果卷积和扩张卷积两部分。
扩张卷积
扩张卷积是为了增大卷积核感受野而设计的一种东西,看图就知道了:
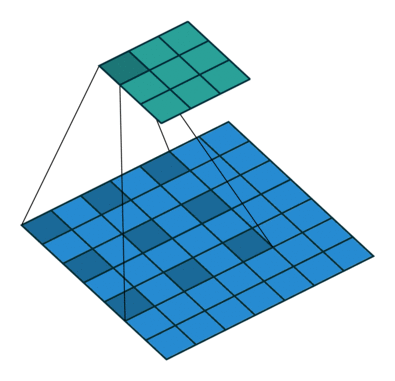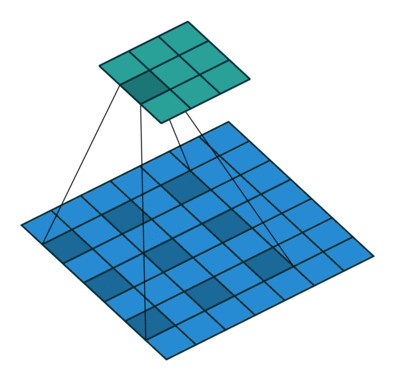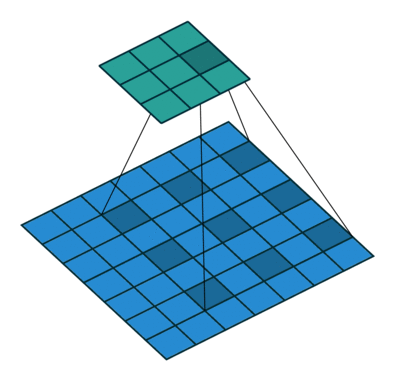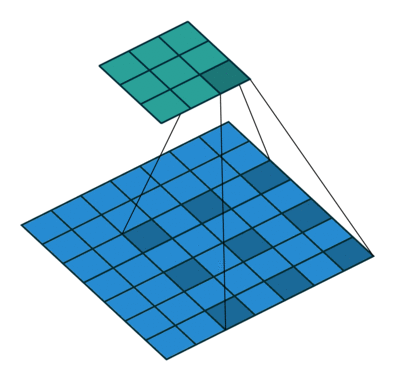
卷积核与图像计算时填充了间隙,在移动相同步伐的情况下,能卷积更多的数据,这样就能扩大视感受野。这里的扩张步是2。代码实现也很简单,指定参数即可:
1 | model = torch.nn.Conv2d(in_channels, out_channels, kernel_size, dilation=1) |
默认情况下dilation取值为1,也就是没有扩张。
因果卷积
因果卷积的重点突出在因果两个字上,输入的历史数据是因,输出的数据是果。来看一下模型结构图,这里有三层卷积网络。
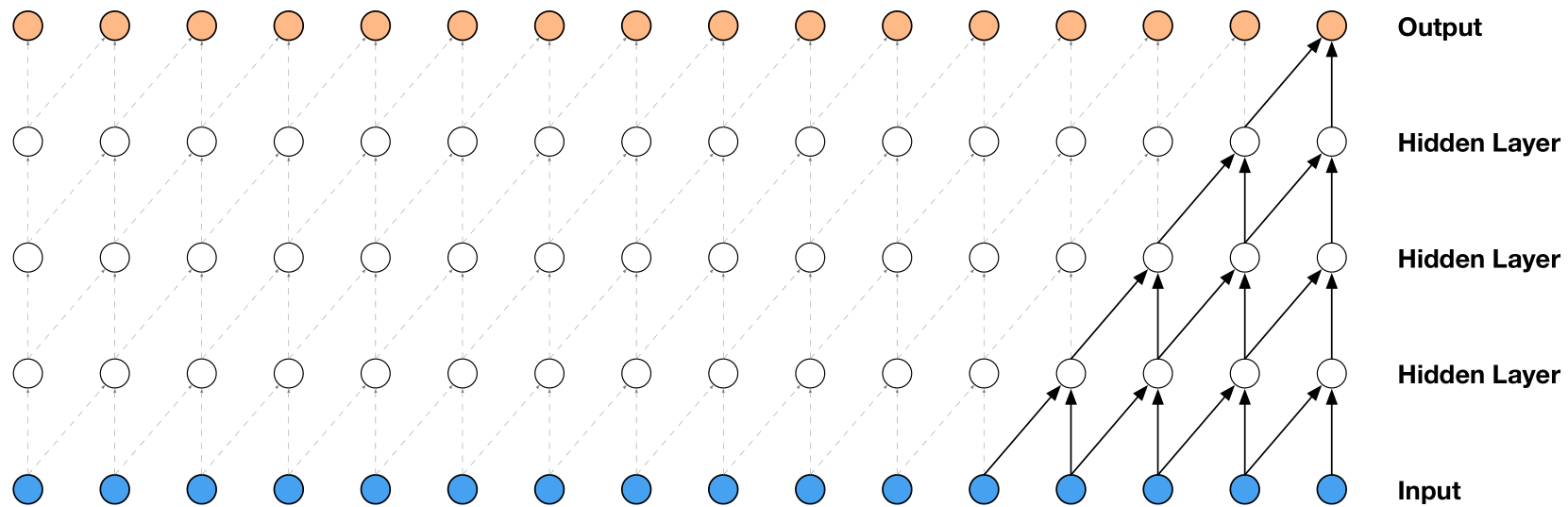
第一层的卷积块读取几个历史数据,经过后几层的卷积块后输出一个数据,达到预测的目的。
但是,在逐层卷积的同时,每步只卷积两个模块。这就导致了视野域比较小。所以增加了扩张卷积,来增大网络的感受野,即:每次预测时能比之前看到更多的数据,做出更稳定的决策。此时的网络结构为:
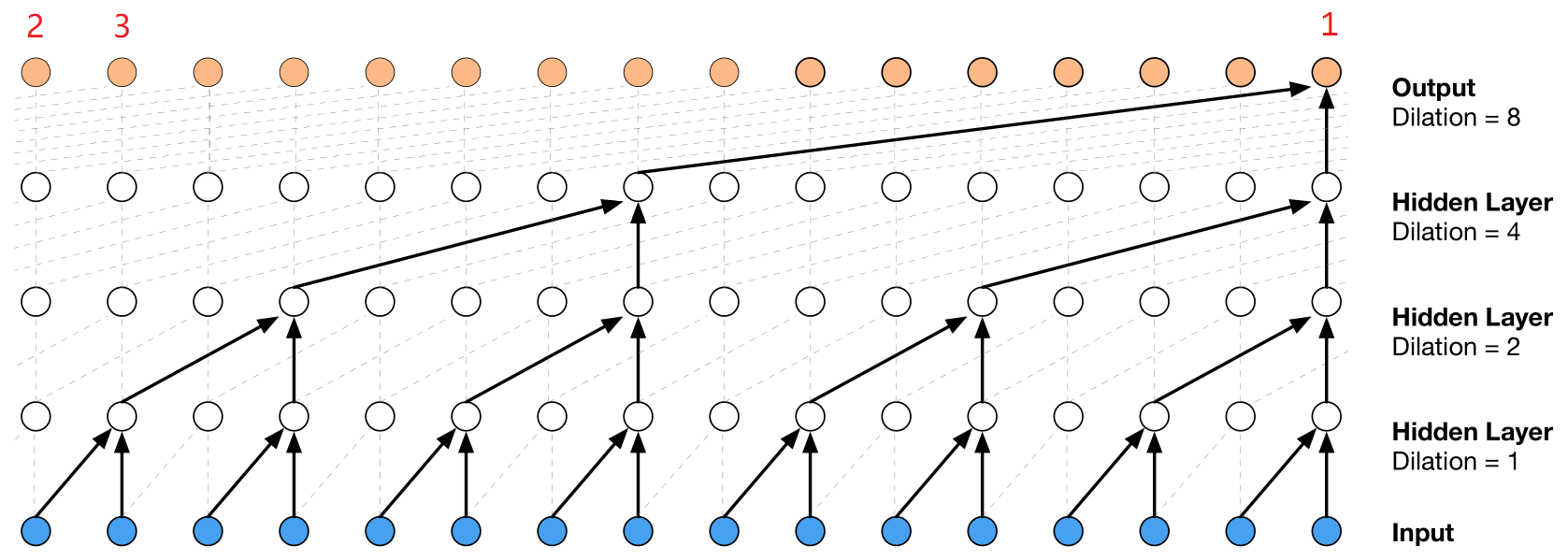
可以看到网络在预测输出时,能看到16个数据的信息,比之前的5个数据的信息要多出三倍,做出的决策也会更加稳定。在某种意义上,也就能像LSTM那样处理序列数据了。
也会你会有疑问,1号节点有历史数据,假设1号节点已经是输出序列的最后一个元素了,那2号节点和3号节点呢,他们的输入从哪里来?看了代码我才明白,填充即可,也就是conv里面常用的padding。卷积过程保证输入和输出的长度不变,填充多少,
至于残差连接或加入条件信息,这些都是可以的,在 casual dilated conv 首次被提出的论文中都有这些内容。
代码
读懂一个算法精髓最好的方式是读代码,理解一个算法精髓最好的方式是尝试去理解它为什么这么做,而不是这么做有什么好处。

