CV 系列的论文和程序得一点点开坑了。目前准备的计划任务是:FCN,OHEM,Mask RCNN,YOLO,Focal loss,Seesaw loss。别问,问就是网上一点点查阅得到的,然后写写代码。
2022 年回来填坑,因为之前接了一个语义分割的项目,所以看了一些相关的论文,当时整理的内容都在草稿里躺着,今天想起来,于是决定补充到这个博客里。注意:我看一些 github 的第三方不错的实现,多多少少在模型结构上和原论文不完全一致,因此网络结构部分略写了。
什么是语义分割
语义分割的直观解释可以见下图,计算照片中的每一个像素点的类别,进而得到哪些像素点属于同一类,把一些物体给分割出来:

FCN
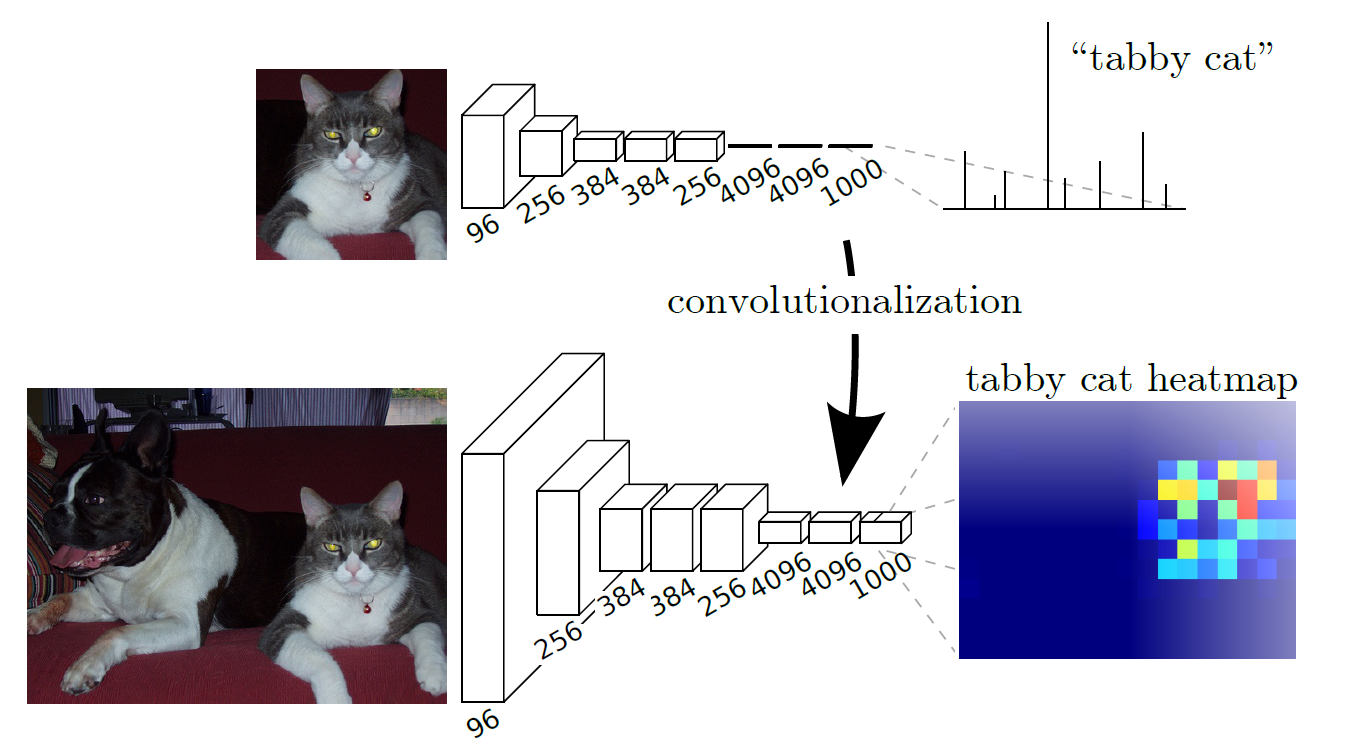
CNN 能够对图片进行分类,可是怎么样才能识别图片中特定部分的物体,在这篇论文之前,还是一个未解难题。
- 对于传统的分类网络,经过 CNN 不断卷积、池化的处理,最后进入全连接网络,预测当前图片的分类。但会丢失空间信息,无法预测每个像素的分类。
- 对于目标检测的网络,也是经过 CNN 不断卷积、池化的处理,在最后的特征图上预测类别和位置。但识别出来的是目标框,并非物体的轮廓边界。
而 FCN 的创新之处在于,使用卷积操作替换了分类网络的全连接,可以保留特征的高度和宽度信息,再通过上采样使得输入输出保持在相同尺寸,这样就可以预测每个像素点的类别,通过交叉熵损失函数计算损失并反向传播。网络结构如下,用下面的卷积替换上面的全连接:
上采样
经过不断的卷积,图像的尺寸会减少而维度会增加。所以为了使得网络输出的图像尺寸和原图像一致,需要进行一些上采样,使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息。最后在与输入图等大小的特征图上对每个像素进行分类,逐像素地用 softmax 分类计算损失,相当于每个像素对应一个训练样本。这部分在论文的第三章有所描述。
而上采样采用的操作是转置卷积(Transposed Convolution),如下图 2 所示,蓝色是输入,青色是输出,白色的 padding 部分为 0,将图像的尺寸瞬间增加了一倍。需要注意的是,转置卷积不是卷积的逆运算。而文中发现,这种形式的上采样是最有效的,且,可以通过叠加网络之前层的输出(类此残差),获得更好的精度。此外文中特意表明了转置卷积也是卷积层,按照普通的卷积层进行训练即可。
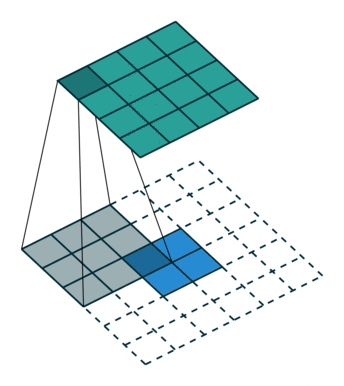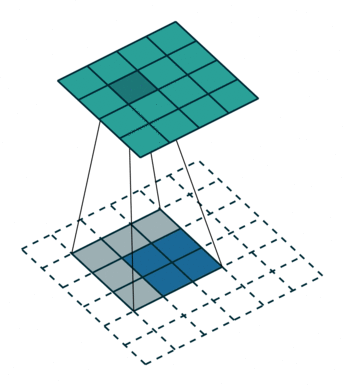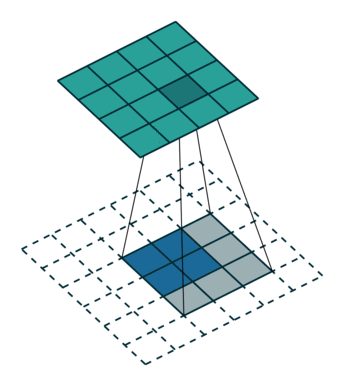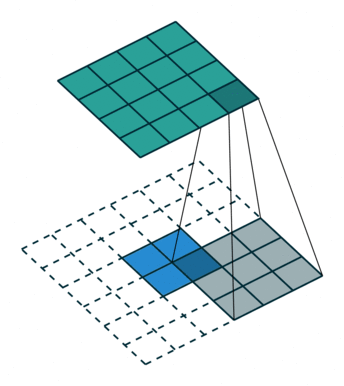
融合操作
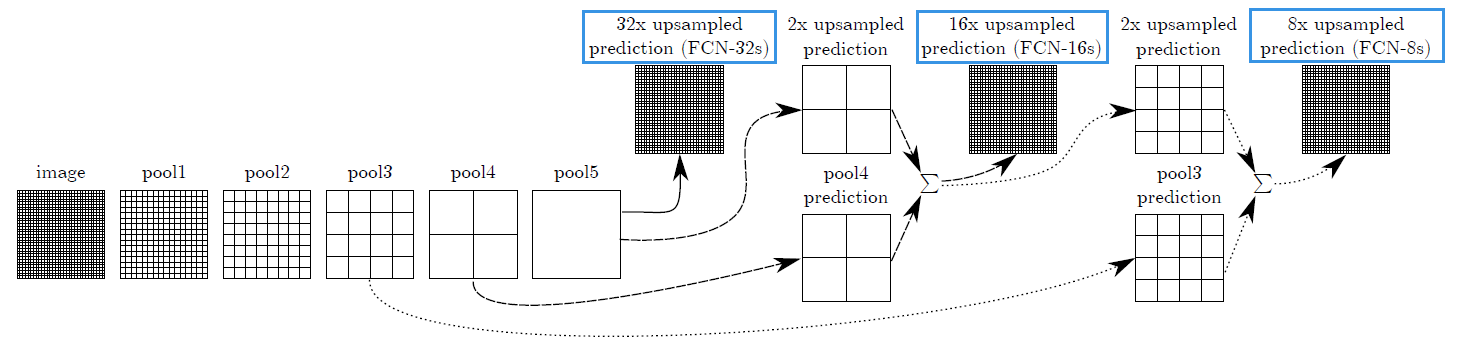
如上图所示,论文给出了 FCN 的三种版本。
- 对于 FCN-32s,直接在最后一层进行 32 倍的上采样,原始空间信息倍大量丢失
- 对于 FCN-16s,将 pool5 后的结果进行 2 倍上采样,与 pool4 的结果相加,得到结果 $F$,而后进行 16 倍上采样
- 对于 FCN-8s,将 $F$ 与 pool3 后的结果相加,而后进行 8 倍上采样
论文中的结论是,FCN-8s 的效果要好一些,毕竟更多的利用了原始空间信息。网络结构图如下 3 :
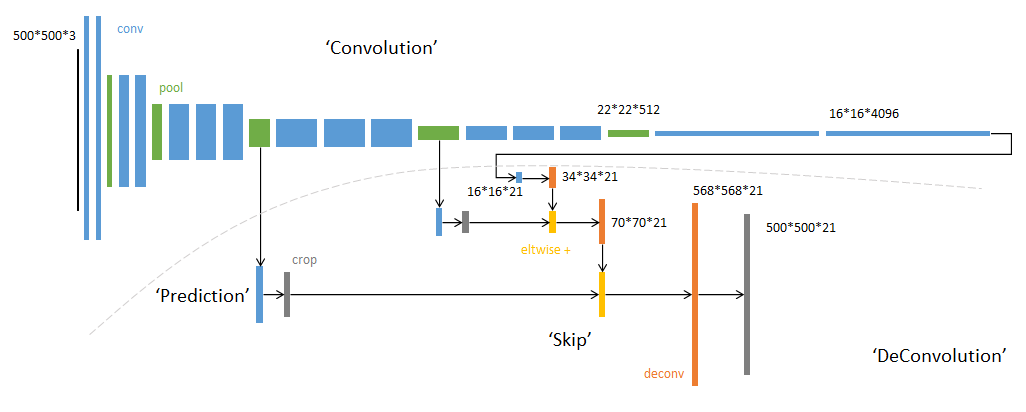
程序
网上看到了份程序,逻辑写的还不错:
https://github.com/pochih/FCN-pytorch/blob/master/python/fcn.py
尺寸在我裁剪图片的时候进行了放缩,不要太在意。

解码
若要可视化展示结果,需要对网络输出的结果进行解码。如标注图片上的类别等。假设输入图像的尺寸是 [800, 800] 的,当前类别数量是 21,会得到 [bacthsize, num_classes, height, width] 的输出。假设当前 batchsize 是 1,那么就需要在 num_classes 张 [height, width] 大小的图片中选择出每个像素点的类别。
1 | out = fcn(data)['out'] |
DeepLab
由于前面详细介绍了 FCN,对语义分割有了初步的认知,后面的 DeepLab,UNet 和 UperNet 就会略写。
DeepLabV1
首先给出了语义分割存在的问题:
max-pooling下采样导致的图片分辨率降低,为了解决这个问题,作者使用了膨胀卷积。- 空间不敏感问题。分类器本来就具备一定空间不变性,当图片发生变化,分类结果也不会改变,但是分割结果应该发生改变,这里我也认为是
max-pooling导致的。作者使用了条件随机场解决,但我看后面的分割网络没有在采用这个结构,于是没有深究。
由于选用的是 VGG16 作为 backbone,进行了和 FCN 一样将全连接替换卷积层,此时图片经过后会下采样 32 倍。由于采样倍率太大导致难以复原原图,因此最后的两个 maxpool 的步距设置为 1,此时就是下采样 8 倍。最后三个3x3的卷积层采用了膨胀卷积,膨胀系数 dilation=2。
此外,针对第一个替换全连接的卷积层,实现了 largeFOV (field of view),使用 3X3 且 膨胀系数 dilation=12 的卷积核扩大感受野,相对于 FCN 减少了 kernel size,降低参数量的同时加快训练速度。
另外一个创新点是 MSC(multiscale),多尺度融合,将原图经过卷积、前四个 max-pool 的输出经过卷积,这五个分支的输出最后相加,得到结果。无论采用多尺度与否,都是将最后的输出通过双线性插值进行上采样,得到和原图同样的大小。
程序
DeepLabV2
相对于 DeepLabV1,我个人的理解就是换了 backbone,引入了 ASPP (atrous spatial pyramid pooling) 模块。
- 分辨率低的问题:由于替换了 backbone,再次面临了和 DeepLabV1 一样的问题,将最后几个
max-pooling的步距设置为 1,并配合使用膨胀卷积。 由于分割目标存在多尺度问题,作者提出了
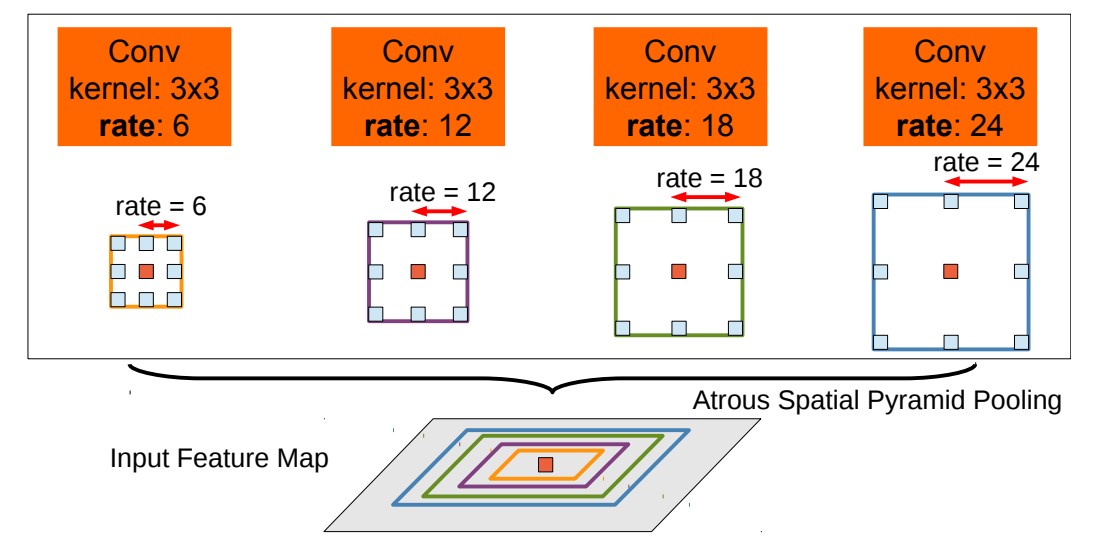
ASPP和多尺度训练两种方法解决。ASPP如下图所示,对输入的特征图并联 4 个分支,每个分支的膨胀率不同,也就是感受野不同,从而解决目标多尺度的问题。最终对四个分支进行求和。![]()
对于多尺度训练而言,将输入图像缩小一些,并通过双线性插值得到和不缩放同样大小的特征图。针对每个像素点的类别,使用的是这些特征图中最大的值。
- 此外,学习率使用
poly策略进行更新,没训练一定的步数学习率就会衰减一些,文中说提高了 3.6 个点。
\begin{equation}
lr \times = (1 - \frac{iter}{n_{}iter})^p
\end{equation}
DeepLabV3
- 引入
multi-grid,每个block中的三个卷积有各自膨胀率,例如Multi Grid = (1, 2, 4),block的dilaterate=2,则block中每个卷积的实际膨胀率为2* (1, 2, 4)=(2,4,8)。 - 改进了
ASPP,总结一下就是,对特征图进行平均池化、卷积、标准化和激活,在经过 4 路并联的卷积层。对这五路输出进行concat拼接,经过1X1卷积降维后输出。相当于细化了特征提取的过程。 - 移除了条件随机场。
DeepLabV3+
我觉得到 DeepLab 发展到这个版本看着舒服一些。对于 DeepLabV3,论文中写如果 Backbone 为 ResNet101,Stride=16(下采样 16 倍)将造成后面 9 层的特征图不得不使用膨胀卷积;而如果下采样 8 倍,则后面 78 层的计算量都会变得很大,这就造成了 DeepLabV3 如果应用在大分辨率图像时非常耗时。我个人认为它的创新点在解码器和网络模型的改进上:
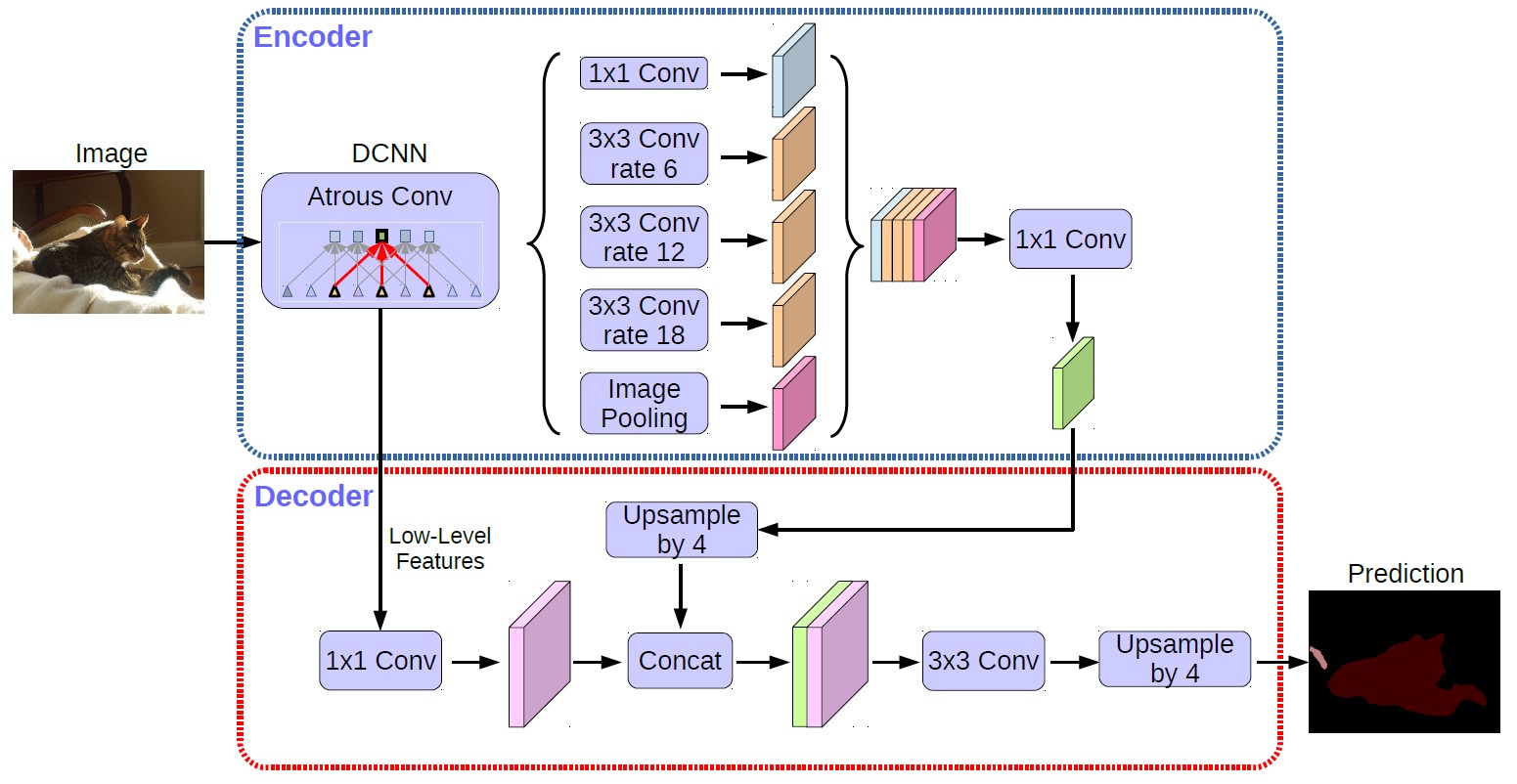
- decoder 如何工作的,直接看图就好,文字描述一大堆反而显得很乱。
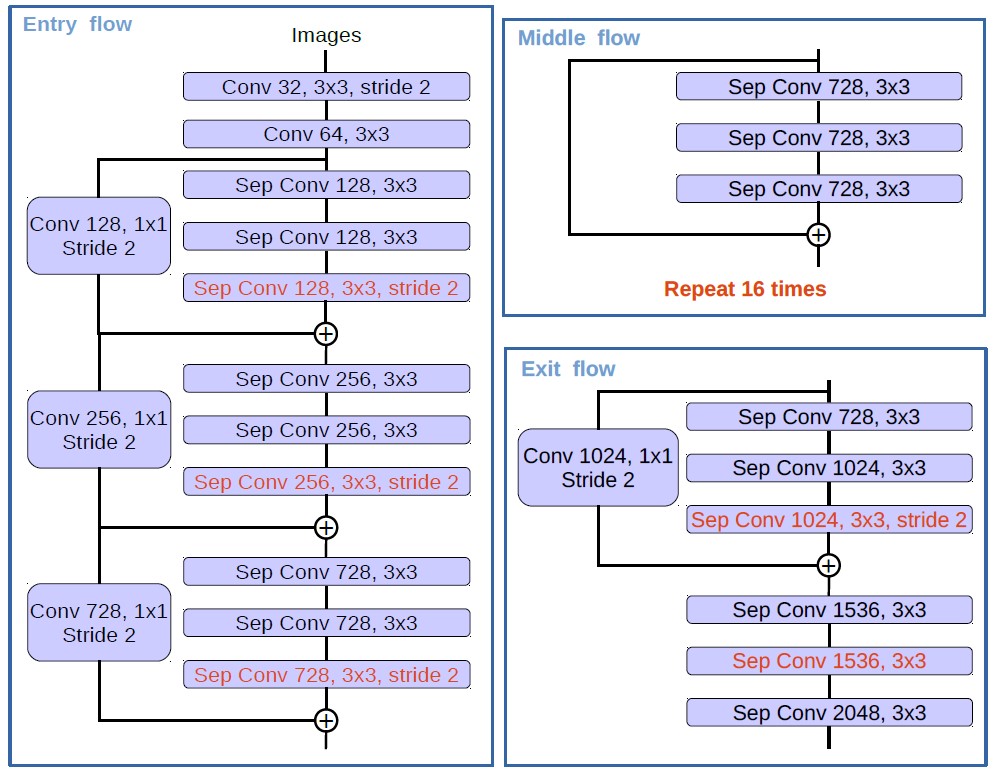
- backbone 替换为 Xception,在 Entry flow 中,首先是两个
3X3的卷积,然后是三个用深度可分离卷积代替3X3卷积的残差模块。然后是 Middle flow,这是一个左侧没有卷积的残差模块,同样这里也是用的深度可分离卷积,然后重复16次。最后是 Exit flow,这里就是一个残差模块和三个深度可分离卷积。最终图片倍下采样 8 倍。
出于对谷歌的信任,我当时试用了这个网络,效果很不错。
U-Net
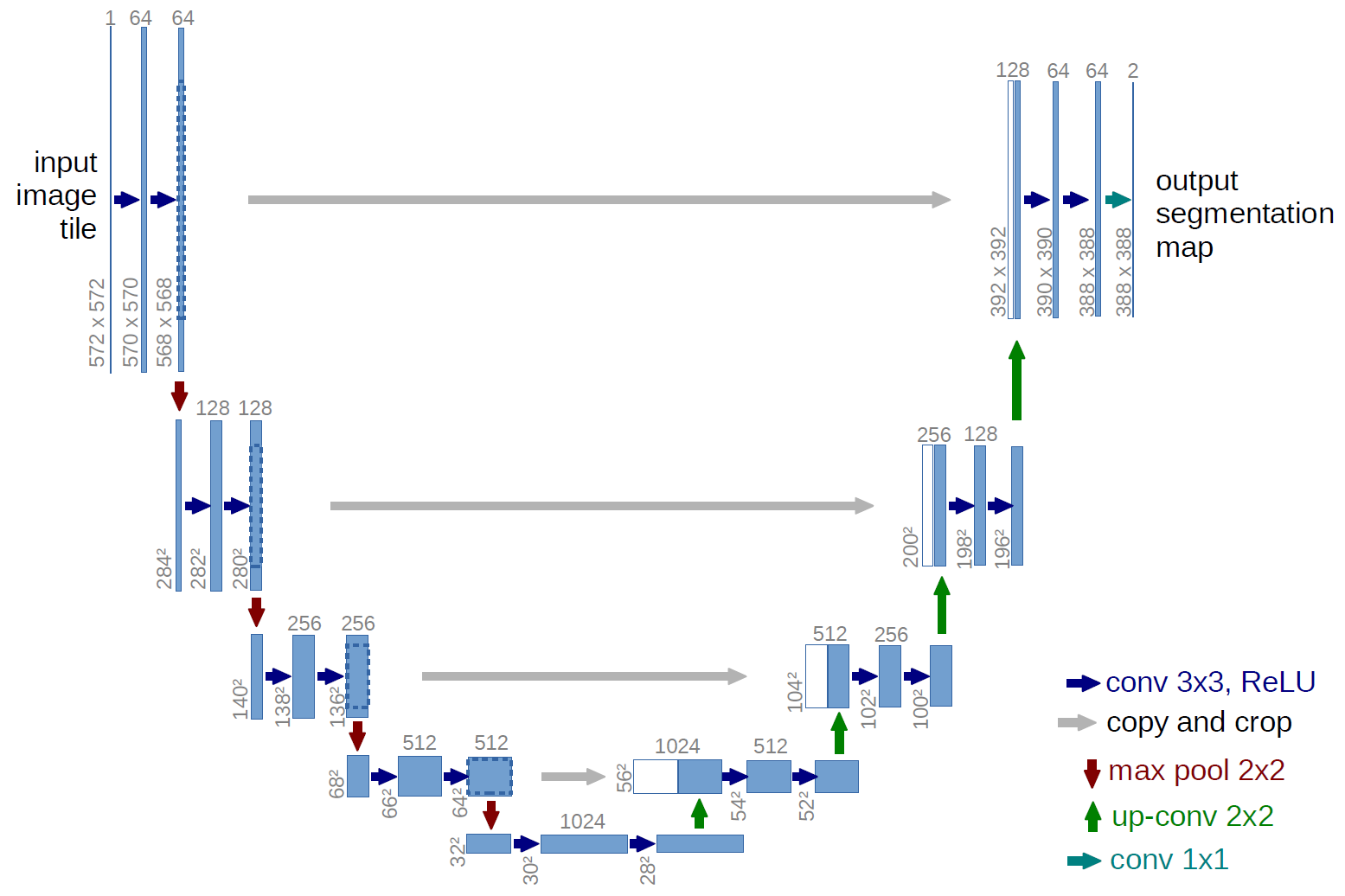
此外,U-Net 5 的网络结构也适合做分割,一图胜千言。上采样使用的是前文提到过的转置卷积。在原论文中,灰色连接的两个特征图尺寸是不一样的,因此需要裁剪并选择中间部分。由于输入和输出的大小是不同的,为了得到图像的分割结果,需要对图像的边缘进行镜像填充处理。不过在他人的程序实现中,卷积的时候添加了 padding 进行处理,这样就得到了同等大小的输入和输出。
PAN
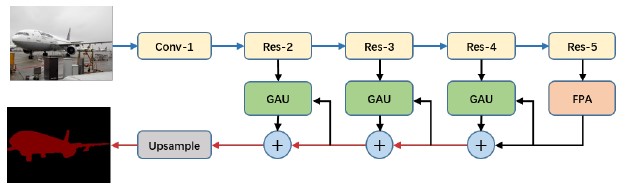
当时出于对旷世的信任,加上直观感觉这个网络结构也不错,也使用了一下 PAN 这种分割结构,我认为的创新点有两个:
- 与 SPP 不同,使用了 FPA(Feature Pyramid Attention)结构进行多尺度特征融合。全尺寸特征图的 global pooling 和卷积可以理解为注意力机制,将全局上下文信息作为先验知识引融入到通道的重要性中。
![]()
- 将高维特征使用 global pooling 将图像上采样到
1X1大小,经过卷积层后和低维特征进行相乘。![]()
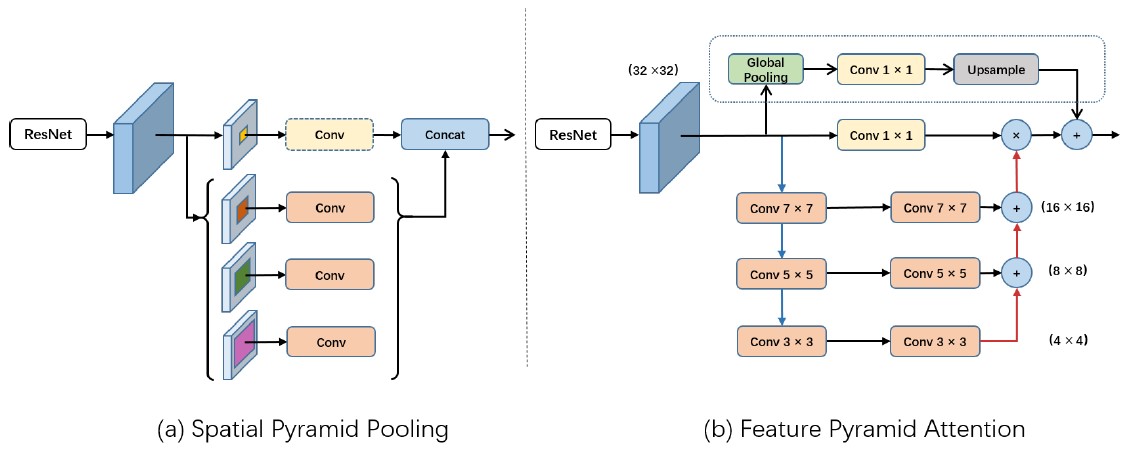
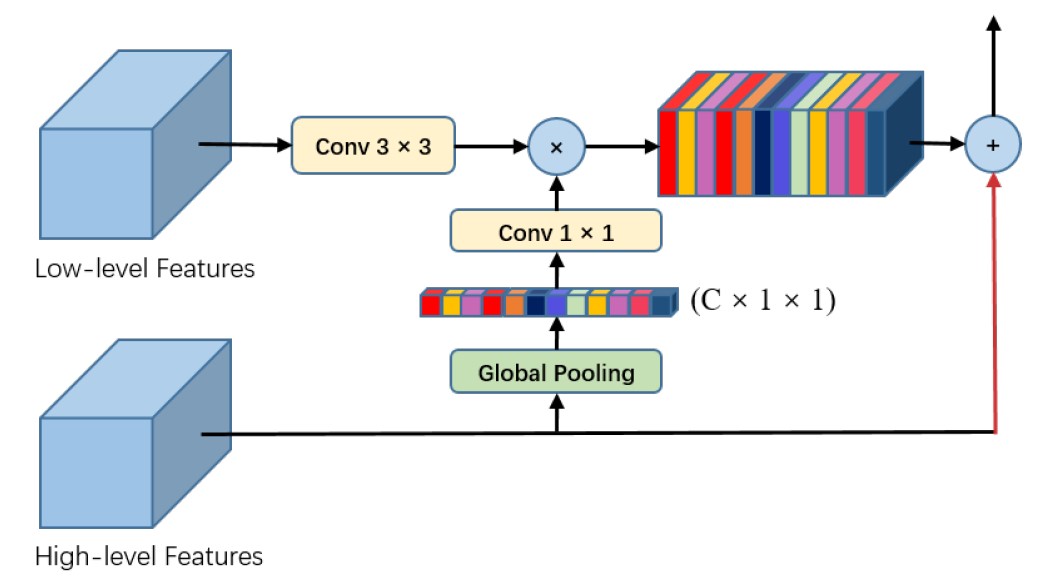
细节的话,global pooling 是通过 avgpool 实现的,将图像上采样到 1X1 大小。FPA 中的上采样是通过转置卷积实现的。
UperNet
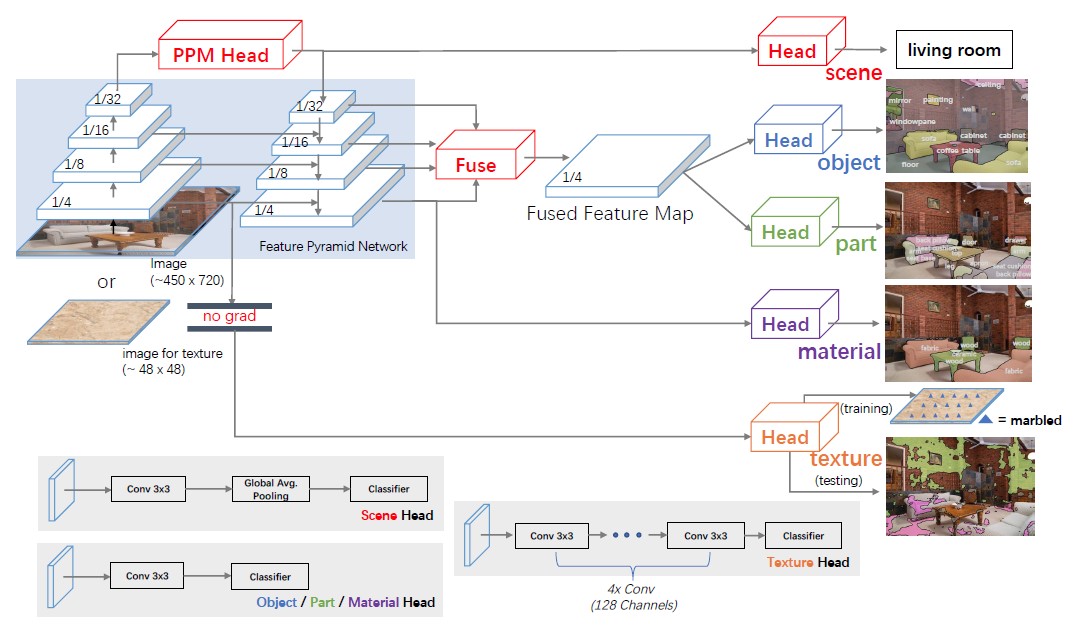
这是一种统一感知解析网络,看图说话就是:经过 backbone 和 FPN 提取到的特征图,可以应用到各种场景,目标检测、场景识别、材料识别或者文本生成等,而这当然也可以用到语义分割中。
这里的实现我是直接通过 mmseg 工具箱实现的,效果很不错。

