还是老样子,不看代码永远不能称为学会了。况且 YOLO V2 有一些优化还是很常见的,如 Anchor Box 和多尺度训练。我之前也只是听说过这些名词,并不知道如何在程序中使用,索性直接读了程序了解一下,程序写的还是比较精彩的。另外:这是第一篇用 vim 写的博客。
YOLO v2
论文地址:https://arxiv.org/abs/1612.08242
提供两个代码地址:第一个适合看模型、损失和多尺度训练,第二个适合看 anchor box 如何用到模型中,但是需要注意的是有 bug,但写的比第一个容易理解。
作者基于之前的 YOLO v1,提出了一些改进的策略,快速的同时准确率也大幅度提升。训练检测网络的同时,在 ImageNet 数据集上进行训练,提升了网络的分类能力。文章的一开始,作者指出了检测存在的几个问题:
- 小目标检测能力受限
- 目标检测数据集的类别远远小于分类数据集的类别,且,不可能对检测数据集进行标注。所以能不能使用多个分类的数据集提升网络能识别的类别数呢?
Better
作者进行了一些尝试来提升网络的性能:
- Batch Normalization,在卷积层后、激活层前加入 BN 层,大约提升了 2%。BN 层帮助网络实现正则化,能移除之前的 droupout层。
- 提高分辨率,将 v1 的 224 尺寸变为 448 尺寸,并先在 ImageNet 上训练 10 次,使得网络适应高分辨率,而后在检测任务中进行微调。
- 使用 Anchor Box 提升定位精准度,预测相对 anchor box 的坐标偏移,预测偏移相对直接预测坐标会简单些。这样提升了网络的召回率。此外,图片的 Ground Truth 一般都是正方形,1:2 的长方形或者 2:1 的长方形,预先准备几个几率比较大的 bounding box,再以它们为基准进行预测。
- 为了设置合适的 Anchor Box 的大小,对数据集的盒子进行 K-means 聚类,筛选出合适的 bounding box 大小。K-means 没有使用 欧拉距离,而是 $1-\text{IOU(box, center)}$,即盒子的 IOU 越大,距离越小。
以上都是微小的改进,下面的三点改进是比较大的。
Direct location prediction
作者使用 Anchor Box 的时候发现早期的网络不稳定,原因来自 $(x,y)$ 的预测。在 RPN 网络中,预测出 $t_x$ 和 $t_y$,$(x,y)$ 的计算为:
\begin{aligned}
x &= (t_x * w_a) + x_a \\
y &= (t_y * h_a) + y_a \\
\end{aligned}
由于 $t_x,t_y$ 的输出值不受限制,$(x,y)$ 能忽略 Anchor Box 的存在而而满天飞。所以网络增加了 sigmoid 函数限制 $t_x,t_y$ 的取值在 0 到 1 之间。具体一点,就是更改网络的输出为 $(t_x, t_y, t_w, t_h, t_o)$。由于 YOLO 的预测的尺寸、中心点的坐标都是相对图片的占比,比如一个目标位于图片的正中心,那么 $(x,y)=(0.5,0.5)$ 。如果当前格子相对图片的偏移是 $(c_x,c_y)$,Anchor Box 之前的宽和高是 $(p_w,p_h)$,那么预测的 bounding box 输出为:
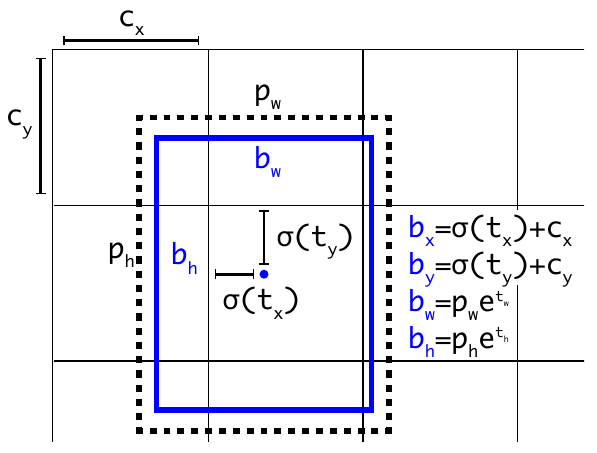
此外,置信度的输出替换为 $\sigma (t_o)$。
Fine-Grained Features
为了提升小目标的检测精度,增加了 passthrough layer,用类似残差连接的方式传递前几层的特征到网络后面,堆叠高层特征和低层特征到不同通道上。

Multi-Scale Training
为了使模型适应不同的尺寸,不再单一的固定单张图片的大小。而是在网络迭代 10 个 batch 后,网络通过下采样来产生新的输入尺寸来读取图像。这样简单的操作,使得模型适应不同尺寸的图像。
Faster
这里的快是为了保证准确率而尽可能快,所以未必会比 YOLO v1 快。作者提出了 DarkNet-19 (黑暗网络,好中二的名称)作为模型的 backbone,相比 VGG16 还是比较快的。之后:
- ImageNet 预训练 160 个 epoch,训练期间使用了随机裁剪、旋转、颜色变换等增强方式;
- ImageNet 的尺寸是 224,为了适应高分辨率的图像,将输入层的尺寸调为 448,再次在 ImageNet 上训练 10 个 epoch;
- 更改网络结构,移除分类层添加检测头。对于 VOC 数据集而言,每个格子输出 5 组参数,也就是预先有 5 个 Anchor Box,每组参数是 20 个类别的得分 5 个盒子参数,所以每个盒子一共 125 个参数。而后 passthrough layer 预测小目标的输出。
用检测数据进行训练时,训练了 160 个 epoch ,也使用了随机裁剪、旋转、颜色变换等增强方式。
Stronger
数据比模型更重要。那么有没有办法把 classification 数据集也利用起来?毕竟它们虽然没有提供坐标信息,但是也提供了类别信息,这部分类别信息能够显著拓展检测的类别数。当输入是 detection 数据时,按照正常的训练过程进行反向传播;当输入的是 classification 数据时,只计算和更新类别对应的 loss 和网络参数。
与 Faster 训练方式不同的是,将分类数据集和检测数据集进行联合训练。此时存在的问题是,分类数据集和检测数据集不是同一个数据集,如果检测数据集的标签是「狗」,那么分类数据集的标签很可能是「泰迪、田园犬」等,所以要合并这些标签。论文采用树的结构融合这些标签,得到具有 1396 个节点的树。针对每一个 anchor,预测出长度为 1396 的矢量,对该矢量按照层级关系进行同层级的 softmax 得到条件概率,根据全概率公式连乘即可得到所属类别的条件概率。

经过这种弱监督式的融合数据集训练后,YOLO v2得以检测超过9000种类别,因此得名为YOLO 9000。
code
模型部分
1 | # 生成 anchor 个 [类别,x, y, w, h] 这样的数据 |
数据与损失
对于加载数据部分,由于是多尺度训练,所以先要把图像 resize 到指定的输入尺寸,而后对标签中的宽度、中心点进行放缩,而后返回盒子、类别标签即可。
1 | batch['images'].append(images) |
众所周知,对于卷积神经网络而言,输入图像的尺寸大小不同,输出的图像尺寸也不会一样。而网络超参数始终是固定的,适应多尺度训练是在损失函数中进行的,将标签数据的尺寸适配到网络输出的尺寸,这样就实现了多尺度训练。而后开始计算损失和反向传播,也就是这个函数所做的。
之后就是损失函数部分了,重点是来看看是如何基于 anchor box 进行预测的,不过仍然可以确定的是,不管是分类损失,还是 IOU 损失或 bounding box 损失,使用的都是 MSE 损失函数。
对于标签数据而言,重要的是看懂这里的流程:
- 遍历当前的 batch size,处理每一个 batch;
- 对预测输出和真实标签进行 IOU 计算,筛选出大于阈值的 bounding box 作为正样本,其余样本忽略;
- 筛选出与真实标签大小最为接近的 anchor box,基于 anchor box 计算和真实框的偏移量。anchor box 是预先设置的,anchor box 没有位置的概念,不是基于某个框生成的,anchor box 在整个训练期间是不变的。假设是第 2 个 anchor box 最接近。由于标签数据的维度和网络输出的维度相同,将标签数据的第 2 维填充为对应标签。这样,其余数据回被忽略。这一部分代码。
结语
这一部分代码还是耐心读吧……我也读了一晚上。也确实没发现网上有哪篇博客写的比代码还要详细清晰。读完了代码,我也知道了代码中如何实现多尺度训练和使用 anchor box。据说 YOLO v3/v4/v5 都是一些工程上的 trick 了。应该只会读那些具有创新点的代码,其他代码会选择性了略过了。

