寒假开始前还是把在学校里遗留的工作先搞完,所接项目的目标是实现半监督语义分割。既然是半监督,就先来看一下半监督的经典论文,我选了经典的、结构相似的三篇论文。
第一篇是:NIPS 2017 的 Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,因为我发现伪标签相关的论文或多或少有它的影子。
第二篇是:ICCV 2021 的 End-to-End Semi-Supervised Object Detection with Soft Teacher,微软出品的半监督目标检测,质量上还是比较让人相信的,且语义分割也可以借鉴目标检测的东西。
第三篇是:ECCV 2021 的 Semi-supervised Semantic Segmentation via Strong-weak Dual-branch Network,因为搜半监督语义分割,最新的进展论文就是它了。
文章最后有代码实现。才发现好久没更新博客了。
背景
因为现实世界标注数据比较昂贵,但无标注的数据很容易获得,那么基于少量标注数据和大量无标注数据的训练,也就是半监督训练也成为了研究的热门。简单来说,半监督分为两类:
- 伪标签,用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(
pseudo label),挑选其中认为分类正确的无标签样本,把选出来的无标签样本用来训练分类器,这样就使用了无标签数据。 - 协同训练,假设每个数据可以从不同的视角(对应到
torch的话,就是不同的torchvision.transform)进行分类。不同视角可以训练出不同的分类器,分类器对不同视角的图片分类结果应该相同。然后用这些从不同视角训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。由于这些分类器从不同视角训练出来的,可以形成一种互补,而提高分类精度,就如同从不同视角可以更好地理解事物一样。
半监督图像分类
这篇论文还是很简单的:
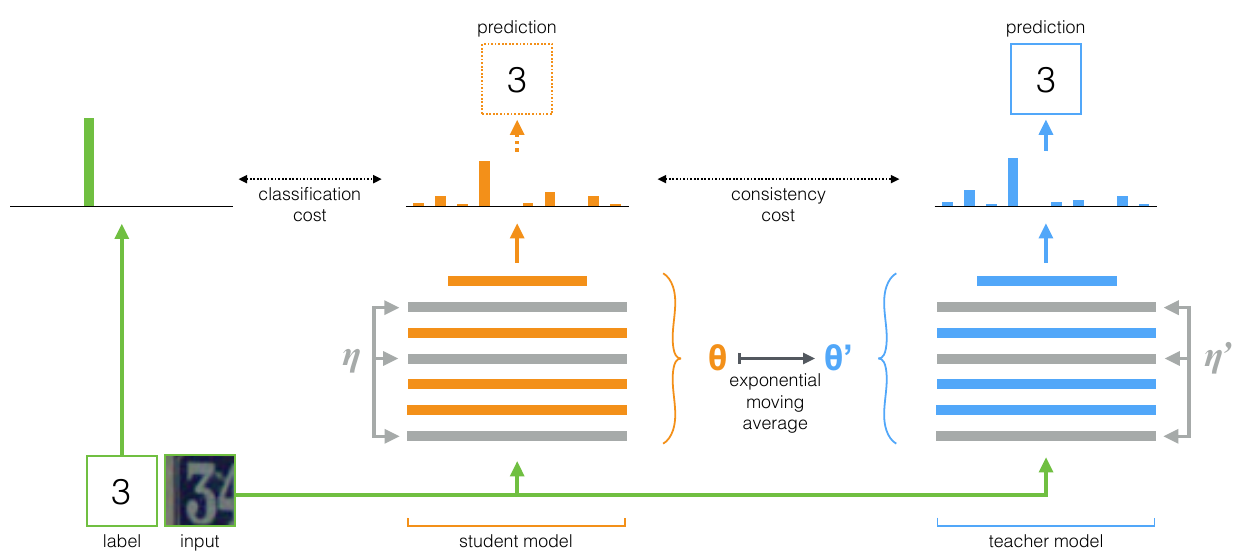
但论文中的训练过程写的不是很清楚,看了代码了解了完整的训练流程:
- 有标签输入学生的预测输出和
one-hot label进行对比,这个是分类损失;和教师的输出使用consistency cost进行对比,论文中用的是两个模型输出的二阶范数,代码提供了mse和kl散度两个损失。第二个loss根据epoch调整权重,epoch越大,权重越大。 - 两个权重相加,反向传播更新学生的模型,
exponential moving average (EMA)更新教师模型,能在每个batch后聚合信息而不是每个epoch后才聚合信息,这样能获取更好的表示。 - 最后使用教师模型进行预测。
至于无标签数据部分,就是一批数据作两次变换,第一组视为有标签,第二组数视为无标签。
这篇论文的思想可以总结为:作为教师,用来产生学生学习时的目标;作为学生,则利用教师模型产生的目标来进行学习。
半监督目标检测
如果说分类图像的数据难以标注,那么目标检测的数据更加难以标注。
半监督目标检测的重点是:提升伪标签质量,伪标签质量好了也利于后续的训练。传统的半监督目标检测是多阶段方法:使用标签数据训练一个检测器,之后对无标签数据生成伪标签,再次训练检测器。但是也很容易受到限制:如何保证伪标签的质量?标签数据和无标签数据分布不一致怎么办?且不是端到端的,多年前写 MTCNN 的时候就感觉不是端到端就很不方便。
同样类似 mean teacher 的结构,创建两个模型,并使用 EMA 更新教师模型。教师模型指导学生模型的训练,而不是简单的提供伪标签就结束了。在获取学生模型生成的预测后,得分大于某个阈值的视为前景,以此保证伪标签的质量,但即使这样仍然有很多预测结果是背景,后文会给出解决方案。
对于无标签数据,控制标签数据和无标签数据在一个 batch 中的比率,从 0.5 开始,衰减到最后的 epoch 为 0。
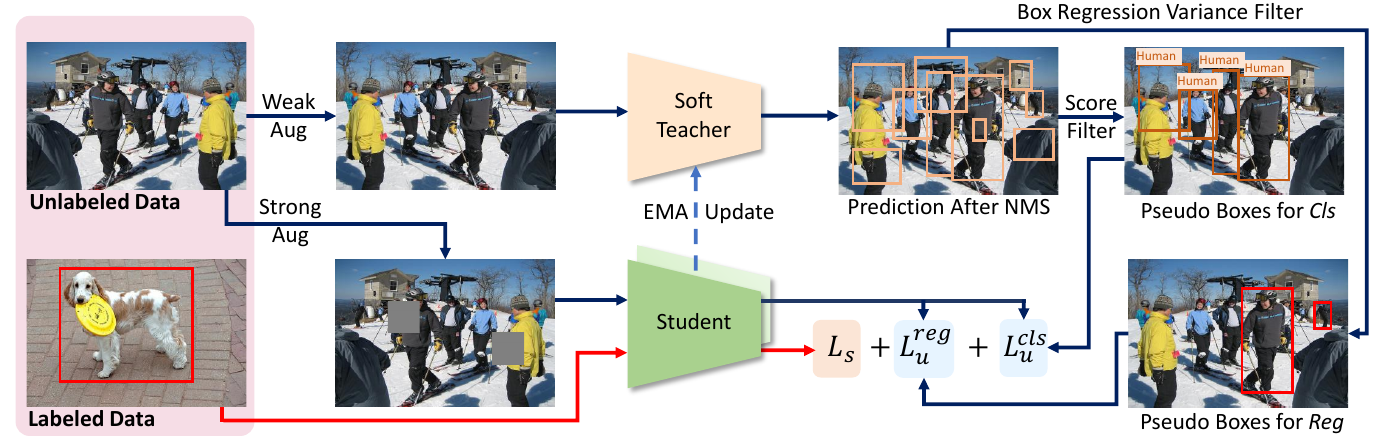
在图里可以看到:教师模型对无标签数据进行弱数据增强,并生成盒子的伪标签和类别的伪标签。学生模型读入有标签数据,得到一个损失 $L_u$ ,对无标签数据使用强数据增强,预测结果和教师模型生成的伪标签对比,又得到一个损失 $L_s$ 。最后的损失为 $L_s + \alpha L_u$。
对于 $L_u$ 的分类部分,与半监督分类的一致性分布损失相反,目标检测的伪标签相对复杂,无标签数据上能检测出上千个盒子,即使 NMS 之后也会留下很多盒子,所以选择前景分数大于某个阈值的作为盒子,但是阈值高导致召回率低,也就是说,学习模型的前景被匹配为背景。为了避免这个问题,在得到学生模型计算出的前景和背景后,前景直接和伪标签进行对比,背景使用可靠性分数进行加权。
对于 $L_u$ 的盒子部分,前景得分并没有提供很好的定位信息,也就是说使用得分作为阈值筛选教师提供的盒子伪标签没啥用,那么如何使盒子的定位信息更加可靠呢?论文是这么做的,在教师生成的标签盒子周围附近进行随机采样,再次得到预测的盒子,重复这个过程$N$(实验部分取 10)次得到多个盒子,计算这些盒子的标准差,标准茶大于 0.5 的才视为前景的盒子。
代码是用 mmdetection 写的,几年前我用过这个东西,暂时不考虑精读代码,这个并不是大众用户的东西,暂时不考虑精读代码。
半监督语义分割
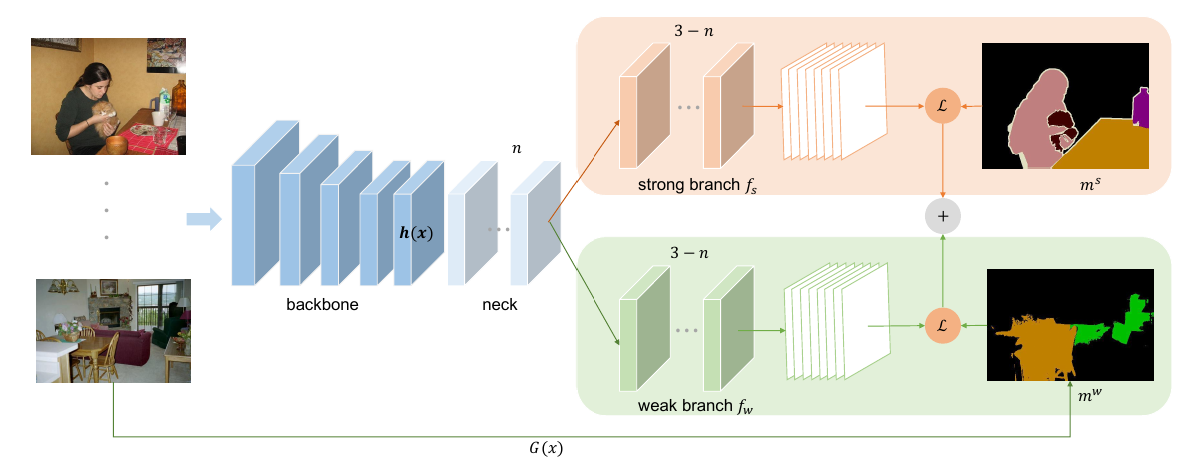
这篇论文的结构和上面两篇论文的结构很像,在这一瞬间仿佛世界线收束了,虽然这个论文没提供代码,但个人感觉这个方法是靠谱的。
它在语义分割的时候分为有标签样本和弱标签样本,弱标签样本是用别的方法生成的,我没有细看生成的方法。因为我准备在这篇论文的结构上在加一个教师网络,用教师网络生成伪标签,剩下的东西和半监督图像分类差不多了。
代码
代码用的 segmentation model pytorch,我看了下代码,魔改成半监督的话还是比较简单的,思路有了,代码都好说。会在不久的将来开源程序和结果,预计三月初。

