
阿里灵杰问天引擎电商搜索算法赛,来详细的记录一下参加这个天池比赛的流程以及我眼中的检索。因为之前从未涉足 NLP 领域,对 NLP 的了解也仅限于大二的时候看完《数学之美》手写过 TF-IDF 算法,我甚至不知道什么是 bert。
为了防止更多的人踩坑,能愉快的参与进来,于是决定把我的做法和程序分享出来,供参赛选手参考。之前在交流群里大概说了我的做法,私聊我的人我也都告诉了他们大概怎么去做,在那几天看到好多人在排名突飞猛进保送到了 0.2 分左右,甚至超过了我,还是比较开心的。这次做一个系统的分享,我甚至会告诉你怎么做是不对的,也希望你能有更创新的想法。走过路过给我的 github 点个 star 就行了,孩子要秋招了,这对我比较重要。(2022年3月20日,0.22的得分排名 21,3月24日,这个得分只能90名,大家太卷了)。
前言
每天坐在电脑面前查方案、读论文、写代码,每天都加班到凌晨,提交了近一周的 0.0X 的成绩,提交这么多成绩意味着我写了更多的代码。可还是排名倒数,提交成绩的时候一度不敢看排行榜。还有很多反向优化的操作,期间写错代码的次数更是数不胜数。单刷比赛确实感觉不容易,尤其是对我这种到处借显卡的人。除了思路出错和程序出错,读论文和尝试代码的速度也不如组队,写完程序满心欢喜,出来结果满眼失望,经历了一周这样的反反复复,还好稳住了心态,坚持了下来。大型诉苦现场。
在 21 年 7 月的时候,接到了某互联网研究院的项目。我这里简化一下,给定一张图片,在数据库中快速的检索出相似的图片。因为对面采用的方法是使用欧式距离一张一张的比对,速度很慢,我表示对这种做法很震惊,从大学随便找个本科生至少也知道不应该这么做。而检索任务可以分为两阶段,第一阶段为特征提取,第二阶段为特征比对。因为当时对面提供了原始数据提取后的特征,于是当时只完成了特征比对任务。
时隔半年,我又遇到了相同场景的任务,不过此时要解决的是第一阶段,如何将原始数据提取为一个好的表示,也是这个比赛的关键内容。本文从数据、损失、模型等多个方面来阐述一下如何才能 work,以及为什么能 work。
关于向量索引
从计算机视觉、自然语言与语音处理,这三大类的搜索与推荐,只要物品能够被向量化表示,就可能会看到向量索引的身影。因为向量索引不是本文的重点,这里就简单略过。可以参考我之前的文章:局部敏感哈希算法的C++实现。
特征检索也叫向量索引,学术上对应的专有名词叫 Approximate Nearest Neighbor Search (ANNS),即近似最近邻搜索。为什么是近似,而不是我们想要的精确?这就是精度与时间、算力资源的折中,采用了牺牲精度换取时间和空间的方式,从海量的样本中实时获取跟查询最相似的样本。一种高效的向量索引算法,应该满足3个基本条件:
- 实时查询,支持海量(百亿、千亿级别)规模库量级的实时查询;
- 存储高效,要求构建的向量索引模型数据压缩比高,达到大幅缩减内存使占用的目的;
- 召回精度好,top@K有比较好的召回率;
目前主要的方法有:基于树的索引(KD 树)、基于哈希的索引(局部敏感哈希方法)、矢量量化方法(OPQ)和基于图的索引(HNSW )等。更多内容可以参考这里:https://yongyuan.name/blog/vector-ann-search.html
当时通过编写线程池、空间换时间等操作优化了他人开源的局部敏感哈希算法,修复了他人开源线程池存在的 bug,达到了令人满意的速度和精度。
关于特征提取
这是一个很经典也很实用的问题,在 2022 年的今天,随着对比学习的发展,特征提取也迎来了新的热度。而 TF-IDF(文本),SIFT(图像)等非深度学习提取特征的方法本文就不谈了。
如果使用深度学习来提取特征,如果是图像,模型可以使用 resnet 或者 ViT 等成功的模型,如果是本文,那么可以使用他人预训练好的 bert,我比较推荐 hugging face 和 Nezha。因为前些日子看了 CV 领域的自监督论文,随着模型结构越来越简单,改进集中体现在损失函数上,常用的就是 SimCLR 论文中的对比损失,也叫 InfoNCE 损失函数,而好巧不巧,SimCSE 也用的是这个损失函数。因此,详细来讨论一下这些损失函数,我也没有足够的算力去调网络结构。
简单的优化距离
一开始我的想法很简单,既然标注了样本对,那么一个样本视为 anchor,人工标注的答案视为 positive,在数据库中随机选取一个视为 negative,当然在这里也可以进行在线难例挖掘,不过这种改进还是要在实现 baseline 之后再进行。
选择样本后,将提取到的特征进行标准化,优化 anchor 和 positive 的距离,使他们更加接近,使 anchor 和 negative 的距离更远。为了达到这个目标,在叠加一个交叉熵损失。距离可以选择余弦距离或者欧氏距离,我看 github 的开源项目大部分是余弦距离。具体示意图如下所示:

我想大部分人最开始的想法都是这样,但是这么做合理嘛?显然不合理。
- 因为即使使用随机数,两者的余弦距离也会很高:
![]()
负样本对的目标都“过低”了,因为对于“困难样本”来说,虽然语义不同,但依然是“相似”,相似度不至于0甚至-1那么低,如果强行让它们往0、-1学,那么通常的后果就是造成过度学习,从而失去了泛化能力,又或者是优化过于困难,导致根本学不动。这句话引自科学空间。

别看这种损失函数差劲,triplet loss 也一样,面临模型坍塌损失持续为零的现象。至少我两次在工程中使用 triplet loss 都出现了这种情况,而 triplet loss 模型坍塌在 ECCV 2020 的一篇论文【Semi-Siamese Training for Shallow Face Learning】中也解释过,出现坍塌的场景均为:样本种类多,但是每类的样本很少。而实际证明,这种方案做出来的特征向量,检索的 MRR@10 指标很低,大概在 0.05 就是极限了。心态爆炸的一周:
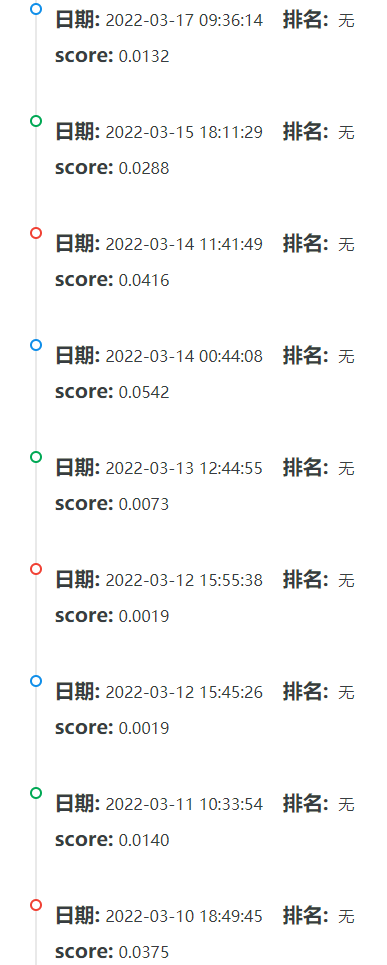
CoSENT 使用
顺着这个思路,查到了苏神的 CoSENT,不得不说从思路到代码都很新颖。如果让我总结一下,那么就是只需要让负样本之间的距离比正样本之间的距离更远就好了,远多少让模型去决定。遂有如下的损失函数(以我的使用经验,损失值会收敛到 0.0X 左右,而且很稳定),而且这个损失函数的代码写法也很棒,建议仔细阅读源码。
\begin{equation}
\log \Biggl(1 + \sum_{(i,j)\in \Omega_{pos}, (k,l)\in \Omega_{neg}} e^{\lambda (\cos(x_k, x_l)-\cos(x_i, x_j))}\Biggr)
\end{equation}
在最开始的时候,我设置正样本和负样本的比例为 1:1,效果不怎么好,可以说是负优化。我又读了一些论文,发现公司的模型都有两部分,其中离线的部分数据量大且训练慢,这么做的好处是训练到更多的数据。那么思路来了,我把正负样本调节到 1:10,负样本并不随机选取,而是顺序遍历全部语料库,因为 1:10 的比例可以囊括所有的样本,这种方法训练时常线性增加,毕竟数据量大了,但是效果好了很多。在 3080 卡,batch size = 2 的情况下,训练时间为 36 小时,得分在 0.15 左右。
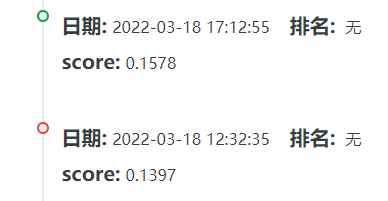
SimCSE
SimCSE 是做 NLP 的,但是仔细看了它的损失函数,会发现这种对比损失在 CV 领域也是存在的,比如 SimCLR 算法。这篇论文的想法简单却有效:
- 如果是无监督,同一个 batch 中,同一个句子经过模型两次会得到不同的结果视为正样本,不同句子视为负样本。使得正样本之间距离近,负样本之间距离远。
- 如果是有监督,那么输入三个句子,一个为 anchor,一个为 positive,一个为 negative,使同一个 batch 中,正样本距离近,负样本距离远。正样本只有同一个句子的 anchor 和 positive,负样本包括两部分:anchor 和 negative,当前 anchor 和其他句子的 positive 与 negative。
因为 SimCSE 支持无监督和有监督训练,那么想法自然也就来了:我看之前的比赛,RMB 玩家为了使得模型更加贴合当前任务的数据集,都要进行 MLM 预训练,但这种方法很耗时间,不适合我这种到处借显卡的人。所以,我用 SimCSE 的无监督方法训练语料库,使得模型贴合当前任务,在这之后,使用标注数据再训练模型来完成任务,岂不完美。个人的参数是,无监督训练 1 个 epoch,有监督训练 5 个 epoch(损失还很大,没有收敛),得分在 0.2 左右,而且 batch 越大,得分越好。
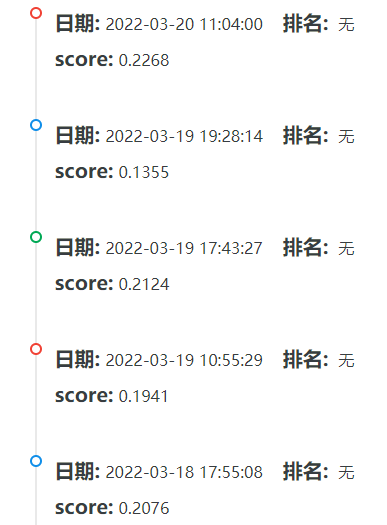
那么 SimCSE 和 CoSENT 如此相似,都是不优化距离,为什么 SimCSE 简单有效呢?这得从他们的损失函数说起:
- 对于 CoSENT,只让负样本的距离大于正样本的距离,但是:负样本对之间的不同,正样本对之间的不同却没有考虑到,也就是利用的信息少。
- 而 SimCSE 却没有这个缺陷,一个 anchor 会计算 batch 中全部句子的距离并 softmax,并经过交叉熵损失,仅仅将与 positive 的距离视为标签 1,其他视为距离 0。也就是说,读取 batch 含有的全部的信息,并抑制除正样本对外其他表示的距离,利用的信息更多。这也就是前文说的,为什么 batch 越大效果越好。
其他 trick
数据不做任何形式的预处理,为什么呢?因为 query 来自用户的输入,这里面存在特殊字符、语序错误、错别字等现象很正常,处理掉反而不好。至于 item 则是商品信息,大家逛淘宝也会发现,商品信息的标注文字几乎没有标点符号,而是很多形容词的堆叠,处理掉也不好。比如:优质木制办公室家用卧室可调接高度带灯光插座多功能折叠桌,它是病句吗?是的,但是就是要查找这样的句子,没必要纠错和预处理。(我没有做消融实验,也没有做数据预处理的实验,这一点仅凭个人分析)。
使用 pool output 而不是 max pool 最后的隐层输出,也许你会问:使用 max pool 捕获最强的特征,也就是捕获句子中最关键的词,只要词匹配对就匹配完成了。但是想一个例子:优质木制办公室家用卧室可调接高度带灯光插座多功能折叠桌 和 优质木制办公室家用卧室可调接高度带灯光插座多功能支架,如果使用 max pool,模型初始阶段很容易捕捉错关键词,但是 pool output 就不一样了,我是全部的语义表示,哪怕只有一个词不一样,输出的表示也不一样。(这个我做了实验)。
模型输出的最后经过 normalization(p=2),为什么呢?我们来看个例子:假设 anchor 的表示是 [0.5, 0.8],positive 的表示是 [0.6, 0.7],如果计算欧式距离,此时是 0.14。如果我标准化之后,anchor 的表示是 [0.53, 0.85],positive 的表示是 [0.65, 0.76],此时的欧氏距离是 0.15。那么有什么用呢?[0.6, 0.7] 和 [0.5, 0.8] 虽然在每一维都很接近,但是维度间的差距却很大,因此 [0.6, 0.7] 并不是很好的表示,需要加大惩罚力度。而 [0.4, 0.9] 这样的 positive 的表示在标准化之后,和 anchor 的距离是 0.14。可见,如果不标准化,那么 [0.4, 0.9] 和 [0.6, 0.7] 等价;如果标准化,[0.6, 0.7] 就不是一个好表示。(这个也做了实验)。
交互式匹配(我没有尝试)。这个灵感来自于早年间看过的一个多模态项目,这个项目通过评论和股票的时序数据作为两个模态来预测股价,两个模态进行了四不像的 transformer 操作,我没理解这是为什么,两者进行了注意力的融合,但是取得了不错的结果。我在想,这次任务没办法进行交互式匹配,但我可以在模型的隐层进行这样的注意力融合,并增加一个分类的分支给注意力提供标签。
- Dense Passage Retrieval for Open-Domain Question Answering 这个论文我看了,想法粗暴简洁,和 SimCSE 差不多,但我没算力去尝试。
- SWA(stochastic weight averaging),我查别人的比赛代码看到了它,效果看着不错。而且早年间用 mmdetection 的时候,确实发现模型在最后几个 epoch 涨分很厉害,但是调参不够友好,在最后阶段我会尝试,现阶段不考虑。
- 难例挖掘,我觉得付出和收益不成正比,没有尝试。
- 以上 trick 可以拿到一个不错的分数,另外其他的 trick 我会在初赛结束后分享,真心太卷了。
排雷
- 双塔结构不要尝试了,即 query 一个全连接,doc 一个全连接,两者共享一个 bert,企图让两者的表示分开不混杂在一起,但效果奇差无比。
- SimCSE 的损失函数在 CV 的自监督领域也有应用,我尝试把 CV 自监督领域最新的损失套用到这里,但结果很难收敛。
程序
https://github.com/muyuuuu/E-commerce-Search-Recall
为什么不用 tensorflow?我 17 年 10 月学 tf 的时候,它那个 with session 和 placeholder 我实在理解不了,那会儿才大二,编程功底很差。19 年 4 月再去看的时候,编程风格和语法大改,好像是什么磁带?梯度一会儿有一会儿没有,混乱的api设计导致代码写的晕晕的,而且和 keras 的关系我也没理解。20 年 7 月的时候我又去看,仿佛完全 keras 化,tf.keras 我实在是被震惊到了,编程风格和语法又又又有改动。我怕我学会了它又出现了 tf.torch,20 年 10 月左右入坑 pytorch,API 稳定,用着也很顺手,也就放弃了学 tf。
不过还是建议各位用 tf,毕竟这个项目最终要落地到工程,这就涉及到部署和性能优化,不是简简单单实现一个算法就可以完美解决所有问题。
参考
- CoSENT:https://kexue.fm/archives/8847/comment-page-1
- Pytorch CoSENT 损失函数:https://github.com/shawroad/CoSENT_Pytorch
- simcse 的有监督和无监督训练:https://github.com/zhengyanzhao1997/NLP-model/tree/main/model/model/Torch_model/SimCSE-Chinese

