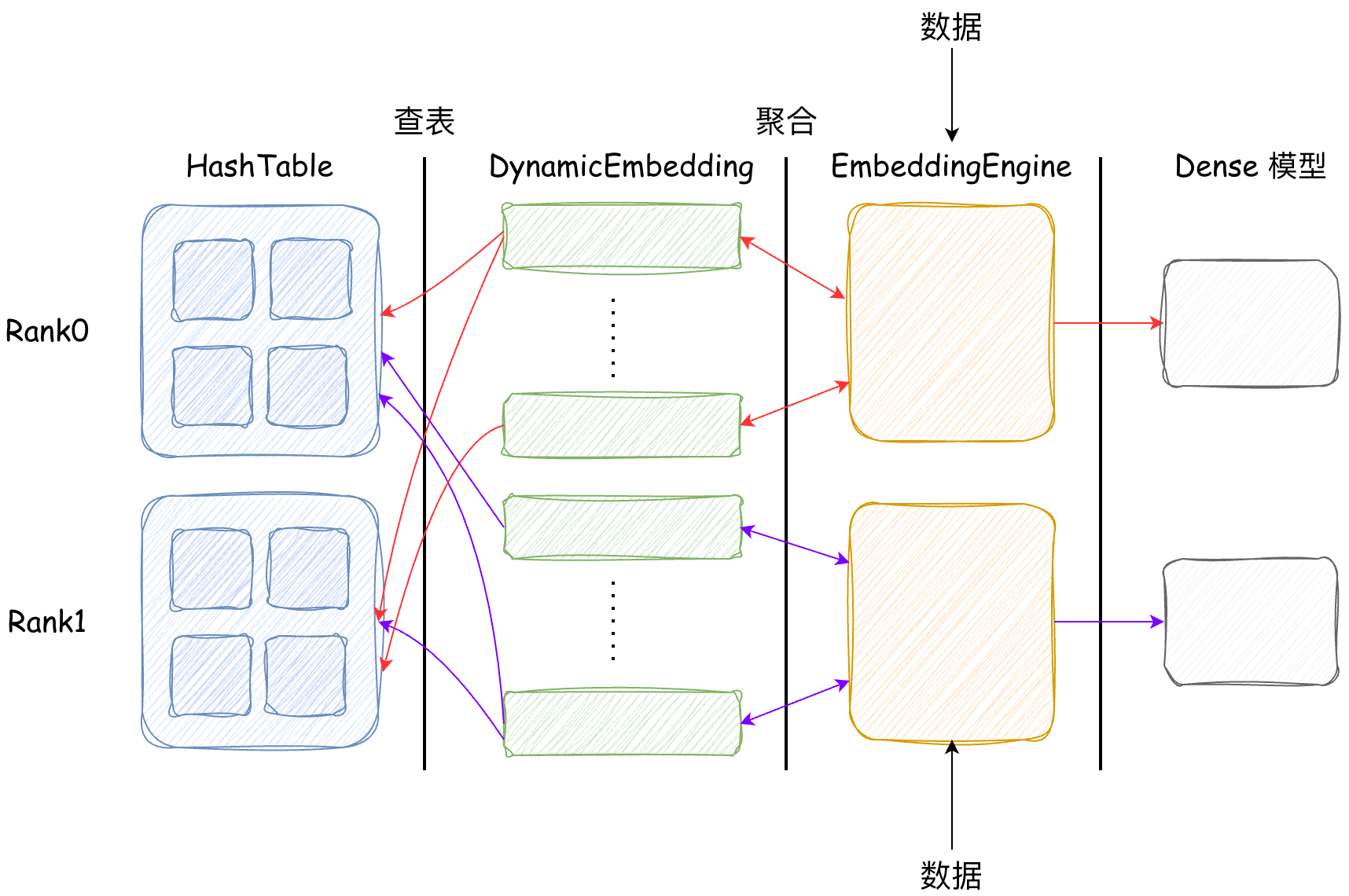
前文介绍的 hashtable 负责数据的存储和检索,排布单卡中的底层数据。而特征处理、多卡通信、Embedding 后处理等功能可以使用 torch 的高层 API 来完成。RecIS 将这些 API 汇总到一起设计了 DynamicEmbedding、EmbeddingEngine 和 FeatureEngine。本文将探索他们的架构与实现,最终可以用 EmbeddingEngine 构建一个完整的稀疏模型:
1 | def Model(nn.Module): |
DynamicEmbedding——多卡通信与 Embedding 聚合
DynamicEmbedding 位于 recis/nn/modules/embedding.py,一个 DynamicEmbedding 维护一个 HashTable。在前向计算时调用 HashTable 的接口返回 id 的查表结果,在反向计算时将上游的梯度传给 HashTable,HashTable 会存储传过来的梯度。DynamicEmbedding 的构造函数比较简单可以略过,最重要的是 forward 阶段的 3 个方法:
1 | def forward(self, ids): |
交换 ids
- exchange_ids:在模型的 forward 阶段,会输入五花八门的 id。在前文 HashTable的设计中,我们知道在分布式环境下不同取值的 id 会被分配到不同的卡上。当输入的 id 可能不在本卡上时,需要将 id 发送到对应的其他卡上。假设 id=1 发送到 1 号卡,id=2 发送到 2 号卡。DynamicEmbedding 通过 torch 提供的多卡通信 API
dist.all_to_all_single实现了 id 分发的功能。
查找与交换 Embeddings
- lookup_exchange_emb:经过 exchange_ids 后,根据当前卡的 id 从 HashTable 查表中获取对应的 Embedding。之后需要将查好的 Embedding 交换回原始 worker,以匹配原始输入顺序。举个例子:
假如每个 worker 都有自己的原始输入:
1 | Worker 0 原始输入: [1, 2, 3] # 原始 IDs |
需要根据 partition 规则分配到不同卡上:
1 | # ID % 3 = 0 → Worker 0 |
调用 exchange_ids 函数完成 id 交换后,每个 worker 收到需要查找的 id:
1 | Worker 0 收到: [1, 4, 7] |
根据交换后的 id 查找 Embedding:
1 | Worker 0 查找 [1, 4, 7] → 得到 emb[1], emb[4], emb[7] |
由于 Worker 0 这个 batchh 输入的 id 是 [1, 2, 3],所以 Worker 0 需要 emb[1], emb[2], emb[3]。但 Worker 0 现在有 emb[1], emb[4], emb[7],和预期不符。所以需要将 embeddings 交换回原始 worker,lookup_exchange_emb 函数最终完成 embedding 的交换功能。
1 | Worker 0 收到: emb[1], emb[2], emb[3] |
聚合 Embeddings
emb_reduce 方法会调用 ragged_embedding_segment_reduce 函数对查找到的 embedding 进行聚合:
1 | emb = ragged_embedding_segment_reduce( |
为什么要聚合呢?在一些场景下输入的样本可能含有多个 id,如用户的兴趣标签、浏览的类别等:
- 用户 1: 喜欢 [科技, 体育, 娱乐] 3 个类别
- 用户 2: 喜欢 [美食, 旅游] 2 个类别
- 用户 3: 喜欢 [音乐, 电影, 游戏, 阅读] 4 个类别
对应到代码中就是:
1 | input_ids = torch.tensor([ |
而 embedding 的输出为:
1 | embeddings = [ |
所以需要对 embedding 按照输入的 id 分组进行聚合,聚合方式支持 sum, mean 和 tile,默认是 sum。当聚合方式 combiner 为 sum 时,会对同一个样本内的 embedding 进行求和:
1 | result = [ |
在具体的聚合计算中,使用 segment_reduce_forward 函数完成前向计算,使用 segment_reduce_backward 函数完成反向计算。值得注意的是,这两个算子函数都是 cuda 实现的。不过本系列文章重点看 RecIS 的架构实现,所以不在介绍算子的实现逻辑。一方面是我 cuda 写的不行,另一方面是算子优化有很多细节,如果只是要了解架构没必要看实现细节。
变长序列
在实际场景中,用户可能在不同的时间点有不同的行为,且不同时间点会有不同的权重:
- 用户 1: 在时间点 [t1, t2, t3] 有行为
- 用户 2: 在时间点 [t4, t5] 有行为
- 用户 3: 在时间点 [t6, t7, t8, t9] 有行为
可以使用 RecIS 提供的 RaggedTensor 管理这类变长序列以及权重:
1 | values = torch.tensor([t1, t2, t3, t4, t5, t6, t7, t8, t9]) |
在聚合计算时,可以通过 RaggedTensor 提供的接口得到 offsets、weights 等参数。
EmbeddingEngine
EmbeddingEngine 初始化
用户使用 EmbeddingOption 创建 Embedding 表的配置字段,来描述 embedding 的数据类型、维度、表名、聚合方式等信息:
1 |
|
EmbeddingEngine 是 DynamicEmbedding 的上游,代码位于 recis/nn/modules/embedding_engine.py。可以负责解析用户传入的多个 EmbeddingOption 并创建 DynamicEmbedding。由于实际业务中会有非常多的特征,用户可以使用 RecIS 提供的 FGParser 解析 json 文件生成多个 EmbeddingOption,这部分代码位于 recis/fg/feature_generator.py,由于代码都是 json 解析相关,就不在细说。假设这里三个 EmbeddingOption:
1 | emb_options = { |
用户创建了 3 个 EmbeddingOption,user_id、item_id 和 category。EmbeddingEngine 会根据 EmbeddingOption 中的属性类型、维度、设备、初始化方式等 coalesced_info 信息创建 fea_group。如上表中 item_embedding 和 user_embedding 的 coalesced_info 信息一致,所以他俩会放到同一个 fea_group 中,而 category_embedding 在其他 fea_group 中:
1 | def coalesced_info(self): |
这样做的优势是把多个逻辑表合并为一个物理表,可以节省通信开销与降低内存分配(后面会介绍)。所以 EmbeddingEngine 只需要为每一个 fea_group 生成一个 DynamicEmbedding 即可,由于 DynamicEmbedding 管理一个存储在内存中的 HasthTable,所以 item_embedding 和 user_embedding 这两个逻辑表共用同一个物理表。可以有效降低内存分配次数和减少内存碎片。
1 | for ht_name, fea_group in self._fea_group.items(): |
EmbeddingEngine 前向计算
在 EmbeddingEngine 的 forward 阶段会依次执行:
- group_features() # 特征分组
- group_exchange_ids() # ID 交换
- group_exchange_embs() # Embedding 交换
- group_reduce() # Embedding 聚合
- split_group_embs() # 结果拆分回原始特征
- format_direct_out() # 格式化透传特征
接下来详细看一下这六个方法。
特征重组
假设我们输入的特征是:
1 | input_features = { |
由于 raw_feature 这个特征不在前面声明的 emb_options 中,所以会被直接透传给下一个网络层,也就是不会对 raw_feature 执行任何查表操作。对于其他特征,会调用 group_features 函数,根据 emb_options 的 runtime_info 信息完成特征分组。
1 | def runtime_info(self): |
最终得到 group_features 结构如下所示:
1 | { |
runtime_info 分组内的特征具有相同的 combiner、user_weight、fp16_enabled、数据精度等信息,所以在运行期间可以对这批数据执行统一的聚合函数,也就是前文提到的 DynamicEmbedding 的 emb_reduce 函数,尽可能减少数据 IO。
特征 id 编码与交换
对 id 进行编码,并调用 DynamicEmbedding 的 exchange_ids 函数交换 id:
1 | group_exchange_ids = defaultdict(dict) |
run_fea.coalesce() 会对特征内的 id 进行编码,ht.exchange_ids() 会交换编码后的 id。交换 id 的原因在前面讲过了,这里详细解释为什么要对 id 进行编码。id 编码的过程可以简化为:
1 | mask = (1 << 52) - 1 // 保留低 52 位 |
当 user_id 和 item_id 都有取值为 100 的 id 时,由于他们的 child_index 不同,会被分别编码为 100 和 4503599627370596。所以不同特征的相同原始 ID 在 hashtable 中不会冲突,且编码后的 id 也会更均匀的分布到各个节点。在保存模型时,会保存解码后的 id 到 ckpt 中。在加载模型时,将加载的 id 编码并插入到 hashtable 中。解码也比较简单:
1 | def decode(encoded_id, offset): |
emb 交换
根据编码且交换好的 id ,调用 DynamicEmbedding 的 lookup_exchange_emb 函数查表。查表过程在 DynamicEmbedding 中介绍过,这里不再重复。
emb 聚合
根据查到的 emb,调用 DynamicEmbedding 的 emb_reduce 函数聚合,由于同一个特征分组内的数据类型、聚合方式都一样,所以会按特征组进行聚合。
1 | for ht_name, exchange_emb in group_exchange_embs.items(): |
emb_reduce 过程在 DynamicEmbedding 中介绍过,这里不再重复。
emb 拆分
split_group_embs 将聚合后的 embeddings 拆分回各个独立特征的 embeddings。对于以下输入特征:
1 | # |
聚合后的特征维度是 [4, 128],user_id 和 item_id 都是 2 个样本,所以拆分后的输出为:
1 | { |
性能分析
在前文我们说过,对特征进行分组处理可以减少通信开销。在不分组的情况下假如有以下输入特征:
1 | features = { |
此时每个特征单独进行通信,Worker 0 需要执行 6 次 all_to_all_single 通信:
1 | 1. user_id.exchange_ids() → all_to_all_single |
而分组后会将有相同的运行时特性放到同一组,即 user_id 和 item_id 会被分到同一组,进行合并处理:
1 | 1. shared_embedding.exchange_ids(coalesced_ids) → all_to_all_single #1 |
由于多个特征合并后只需一次 all_to_all_single 通信,此时只需要 4 次 all_to_all_single 通信,可以大幅减少通信的等待时间和开销等。最终,EmbeddingEngine 的架构图如下: