2022 年 5 月 26 日回来复习。大概涵盖了这么多年写程序过程中遇到的梯度消失、梯度爆炸等基本情况,以及优化器的整理,后面会出一些为什么 train 到的神经网络准确率很低的文章。
有了梯度就要反向传播,而优化器对反向传播有着举足轻重的作用。这种东西之前很少接触,加上常年累月的直接调用,很多理论也忘记了。直到今天自己又去亲自探测了一番,恩,其实也不是不能接受。从统计学中的加权移动平均出发列举经受时间考验的优化器,和时间序列有异曲同工之妙,探求一下优化器的神奇之处。
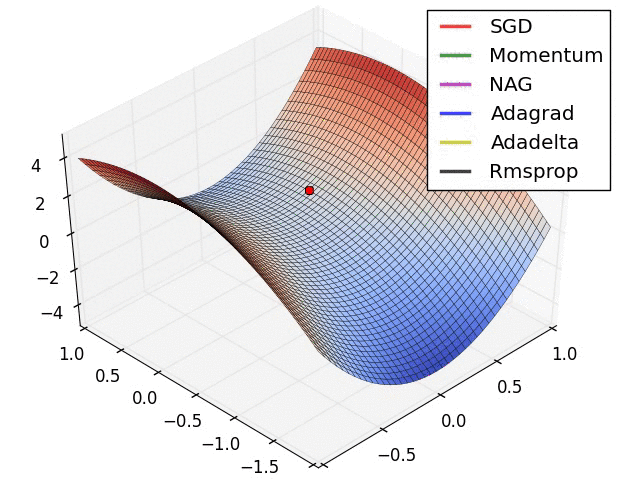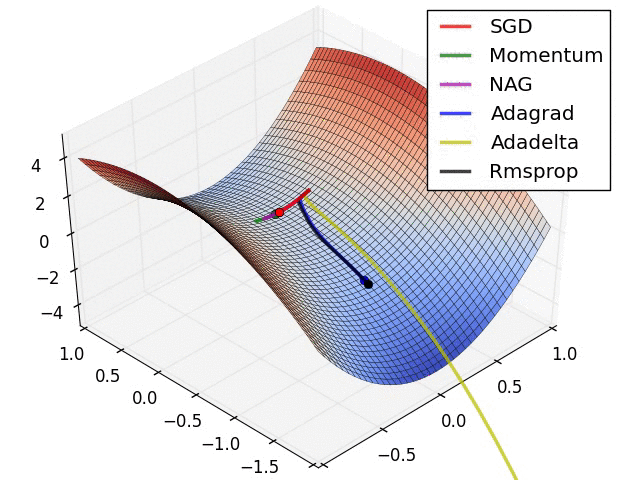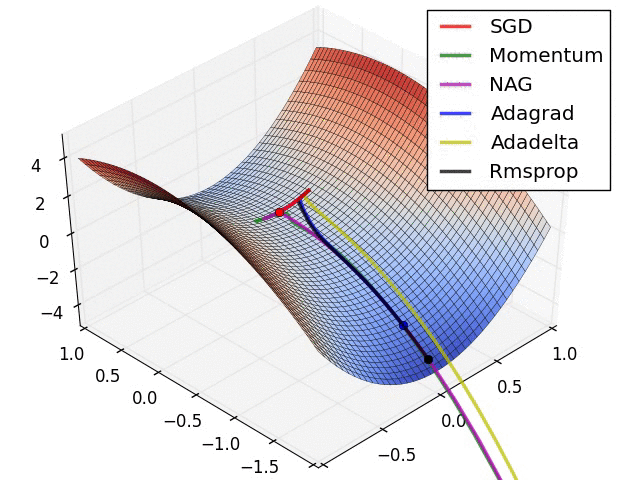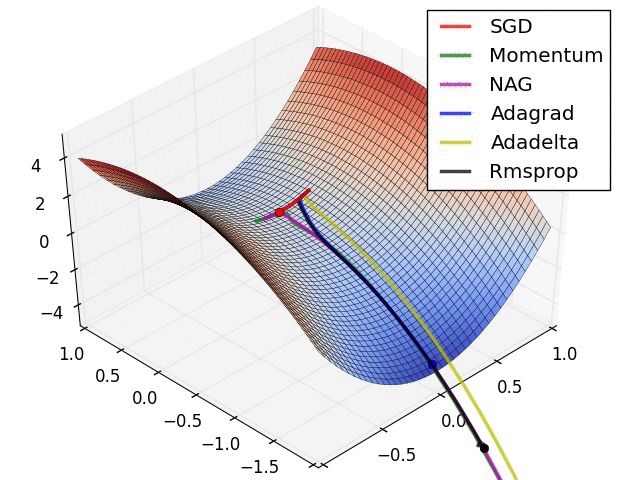
2022 年 5 月 26 日回来复习。大概涵盖了这么多年写程序过程中遇到的梯度消失、梯度爆炸等基本情况,以及优化器的整理,后面会出一些为什么 train 到的神经网络准确率很低的文章。
有了梯度就要反向传播,而优化器对反向传播有着举足轻重的作用。这种东西之前很少接触,加上常年累月的直接调用,很多理论也忘记了。直到今天自己又去亲自探测了一番,恩,其实也不是不能接受。从统计学中的加权移动平均出发列举经受时间考验的优化器,和时间序列有异曲同工之妙,探求一下优化器的神奇之处。
来整理一下在机器学习中常用的优化方法,无非是在容易出问题的地方加入人的调控,包括数据数据,数据处理,反向传播,梯度函数等方面,在各种容易出问题的地方加入调控,使得神经网络更有效,或者说神经网络的运行在你的控制之中,而不是调了一堆参数后网络没有优化,甚至调一些无关紧要的参数。
本文收录内容:
还是在实际的背景下对于这些概念的理解,学会变通和利用已有的知识进行问题转换。
趁寒假看完了DeepLearning的前生今世之后,用了一个下午自己推导了一番,想来还是留下个电子版的整理,供他人交流和日后查阅。(其实是我纸质版整理的太丑了)。
本文收录内容:
重点是对于这些概念的理解,尽力写下人能看懂的公式描述,知道在什么背景下调用和背后的数学观念就可以啦。
感觉一篇博客写太长也不是很好,所以把RNN拆成了两部分,在描述了经典的RNN结构之后,再来看看为了满足实际应用,RNN结构所作出的变化和适应。
本文收录内容:
还是在实际的背景下对于这些概念的理解,或者说是为了满足实际背景而产生了这些观念,学会变通和利用已有的知识进行问题转换。
某天(今天)下午闲的没事干,想起了当初学了一堆的深度学习的数学概念,还看了Keras的官方文档,既然会写(抄)代码和懂了理念,不如自己折腾点东西玩玩。
说干就干.png,本来是想做个OCR系统在写个GUI界面弄个小软件的,因为种种原因放弃(不喜欢那个数据集),猫狗大战的话数据量太大。挑来挑去选择了迁移学习,使用VGG16的结构去识别MNIST手写文字,怎么感觉有一个好的开始却选择了一个low的实现呢?其实也无所谓,重点是实现过程,有了这次过程实现以后的迁移学习就不是问题了。
本文收录内容:
重点是对于这些概念的理解,如果想观看具体概念的实现请往他处。
其实是想把这个的标签设成python的,后来想想设置成keras,后来是改成了deeplearning。如果想看算法或代码请往他处,这里只是记录学习中的收获,或者更多的是理解。就像AI的发展,每次遇到坑都会出现新的解决方案和算法,所以重点不是那些算法,而是如何面对问题,解决问题,什么样的新思路。
本文内容如下:有关读完keras和tensorflow官方文档的收获。