函数调用过程
(1) 函数在调用处暂停执行;
(2) 调用时将实参复制给形参;
(3) 执行被调用的函数;
(4) 调用函数结束, 给出返回值, 函数回到调用前的暂停位置继续执行.
调用栈
调用栈函数调用时产生,描述了函数之间的调用关系。由多个栈帧组成,每个栈帧对应一个没有运行完的函数,栈帧保存了该函数的返回地址和局部变量。所以可以保证在执行完毕后找到返回地址。保证了不同函数的局部变量互不相干,因为不同函数对应了不同的栈帧。
递归
步骤与上述内容相同, 但是调用的函数为自己, 即自身调用自身。(如经典的非波那切数列)
以Cpp为例,编译后的可执行文件存放的内容中主要内容为段,段是指二进制文件内的区域。所有某种特定类型的信息保存在里面,size得到各个段的大小。执行如下指令会:

text:存储代码指令(也叫正文段)
data:存储初始化的全局变量(也叫数据段)
bss:存储未赋值的全局变量所需要的空间
可执行文件并不包括调用函数时的调用栈,而是在运行时创建。调用栈所在的段为堆栈段,也有自己的大小,不能被访问越界,否则会出现段错误(Segmentation Fault)。而每次递归会在调用栈里面添加一个栈帧,栈帧过多会越界,叫做堆栈溢出(Stack Overflow)。调用栈存放了函数的调用关系和局部变量。
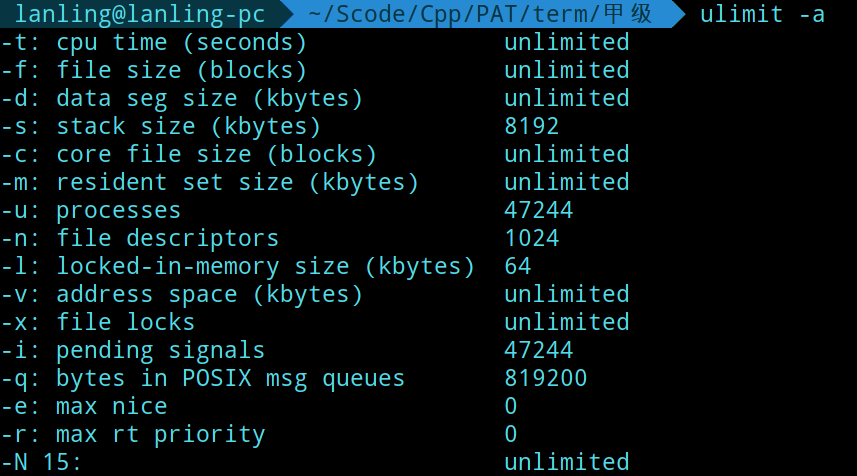
查看堆栈段的大小
linux下,栈大小并没有在可执行文件中,需要通过指令修改。ulimit-a,观察其中的stack size即为所求。
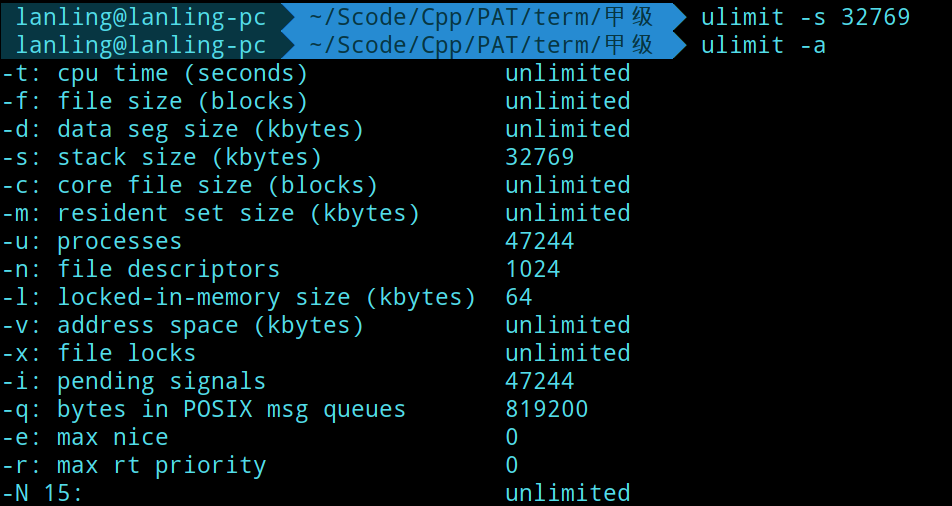
ulimit -s 37629进行修改:
栈溢出不一定是递归太多,也可能是局部变量太大,总大小超出允许的范围,就会产生栈溢出。因此,较大数组存储在main函数之外,因为局部变量存放在堆栈段。(main函数中的变量同样为局部变量)

