又来做小样本问题了,别问,问就是我也不知道,方向换来换去的。我看过 Life long learning,深度学习的聚类,大规模图划分(我只是感觉这几年算法岗很内卷,泡沫化严重。不管什么专业的,都可以来搞计算机或智能,门槛低但要求高,甚至跨专业来的还认为撕代码没用,这个行业一言难尽。
前言
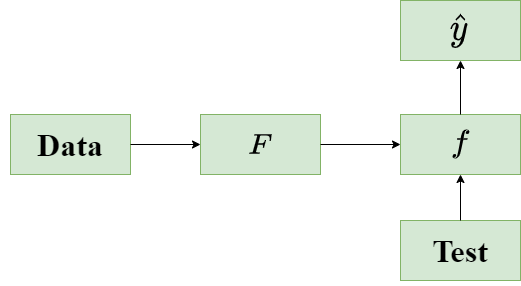
Machine learning 中,我们的目标是定义一个神经网络,训练数据并获取输出,且希望输出的准确率很高,这可以简化为 $f(\text{data})=\hat{y}$,如下图所示:
而在 meta learning 中,则是让机器学会如何学习。假设现在有多个任务,第一个任务是猫狗分类,第二个任务是数字识别,以此类推就不一一举例了。meta learning 的目标就是让网络基于过去的任务获取学习技巧,并能快速应用到其他任务中。比如:分类中,知道猫和狗纹理不一样后,能快速学习出数字 1 和数字 3 不一样。(每一个任务都有一个模型,希望未来基于已有经验能学的更快更好)。在通俗一点,你学过 C++,那么再去学 java 就很快,有经验在那。
meta learning 的目标就是寻找一个 $F$,使得$F(\text{data})=f$,生成的 $f$ 是完成任务,$F$ 就表示其学习能力。
模型结构
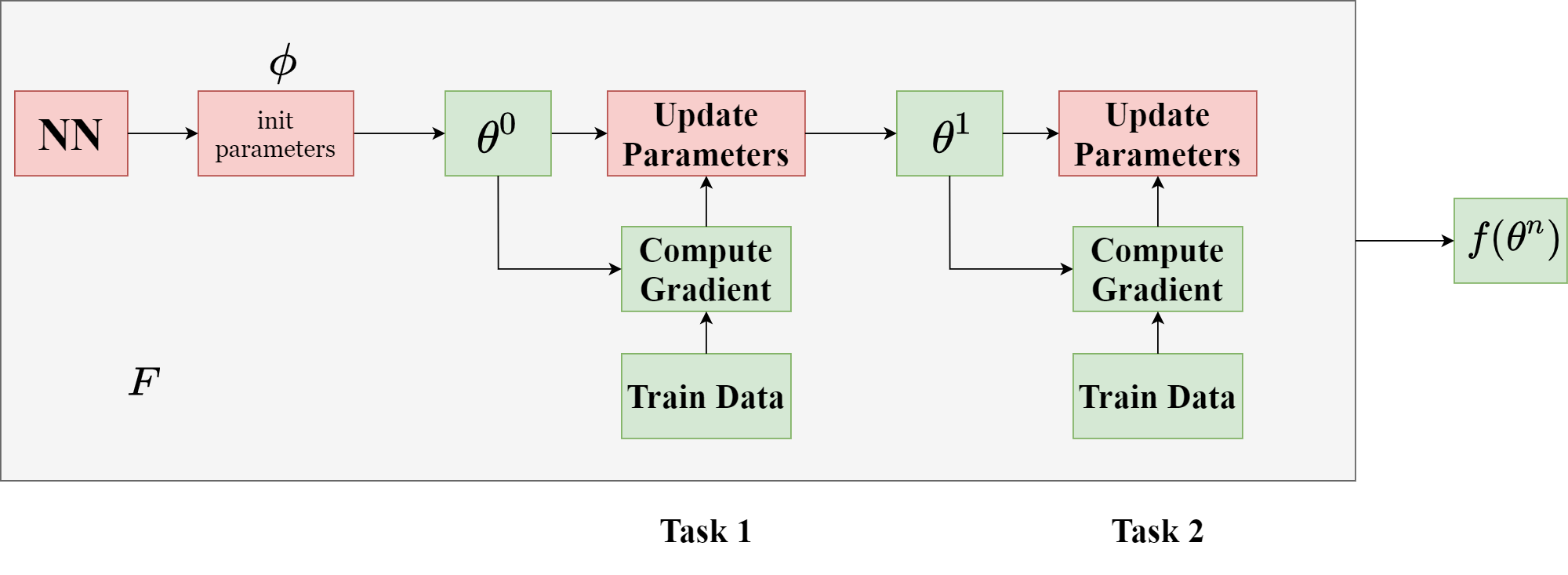
如上图所示,灰白背景为整个 $F$,生成的结果为 $f$。其中:参数初始化、网络结构设计和参数的更新方法是 $F$ 可以学习的。最后得到每个任务的参数 $\theta$。比如 $\theta^1$ 用于第一个任务,$\theta^2$ 用于第二个任务。
评价
那么如何评价 $F$ 的好坏呢?或者说,$F$ 的损失函数该如何写?这里采用简单的任务损失求和的形式来表示:
\begin{equation}
L(F)=\sum_{i=1}^n l^n
\end{equation}
其中 $l^n$ 为第 $n$ 个任务的损失。(你可以自由发挥加点正则什么的),找到一个最好的 $F^{*}$,使得 $F^*=\arg\min_FL(F)$。
训练与测试数据
- 训练期间:在每个训练任务中,也就是上图的 Task 1, Task 2,每个任务都需要准备训练数据和测试数据。训练数据一般称为 Support set, 测试数据为 Query set。
- 测试期间:因为要考察的是 $F$ 的学习能力如何,所以测试的任务和训练的任务不同。
训练过程
MAML 方法
这里仅仅以初始化参数为例,不介绍梯度下降的方法或机器自动调 NN 的结构。为避免混乱,先说明一些符号:
- $l^n$,第 $n$ 个任务的损失;
- $\theta^n$,第 $n$ 个任务的参数;
- $\phi$ 初始化参数;
- $\hat{\theta}$ 所有任务的参数。
首先列出损失函数:
\begin{equation}
L(\phi)=\sum_{i=1}^N l^n (\theta^n)
\end{equation}
初始化参数 $\phi$ 的更新方式为(全局):
\begin{equation}
\phi_t = \phi_{t-1}-\eta \nabla_\phi L(\phi), \; \nabla_\phi L(\phi)=\sum_{i=1}^n\nabla_\phi l^n(\theta^n)
\end{equation}
其中,$\nabla_\phi l^n(\theta^n)$的展开式为:
\begin{bmatrix}
\partial l_1/\partial\phi_1 & \partial l_2/\partial\phi_1 & \ldots & \partial l_n/\partial\phi_1\\
\partial l_1/\partial\phi_2 & \partial l_2/\partial\phi_2 & \ldots & \partial l_n/\partial\phi_2\\
\partial l_1/\partial\phi_3 & \partial l_2/\partial\phi_3 & \ddots & \partial l_n/\partial\phi_3\\
\partial l_1/\partial\phi_n & \partial l_2/\partial\phi_n & \ldots & \partial l_n/\partial\phi_n\\
\end{bmatrix}
因为一个 $\phi$ 对应很多 $\theta$,所以由链式求偏导法则我们可以知道下图的关系式(以上面矩阵中单个元素为例,所以 $l$ 就不带任何角标了):
\begin{equation}
\frac{\partial l}{\partial \phi_i} = \sum_{j}\frac{\partial l \partial \theta_j}{\partial \theta_j \partial \phi_i}
\end{equation}
而在每一个任务中,参数 $\theta$ 的更新方式为(单个任务):
\begin{equation}
\theta_j=\phi_j-\epsilon\nabla_\phi l(\phi_j)=\phi_j-\epsilon\frac{\partial l(\phi_j)}{\partial \phi}
\end{equation}
所以:
\begin{cases}
\frac{\partial \theta_j}{\partial \phi_i}=-\epsilon\frac{\partial l(\phi)}{\partial \phi_i \partial \phi_j} \approx 0 & i \neq j \\
\frac{\partial \theta_j}{\partial \phi_i}=1-\epsilon\frac{\partial l(\phi)}{\partial \phi_i \partial \phi_j} \approx 1 & i = j
\end{cases}
取消第二项的二次微分时:
\begin{equation}
\frac{\partial l}{\partial \phi_i} \approx \frac{\partial l}{\partial \theta_i}
\end{equation}
以上公式是我看懂and抄下来,真佩服能手推公式的。这样,参数如何更新的就讲完了。MAML的主要目标也是更新参数。
但在 MAML 中,每个任务的网络的参数只更新一次,有以下优势:
- 训练速度快;
- 逼迫网络一次达到很好的效果;
- meta learning 的多任务学习常用于小样本,防止过拟合。
来看一下 $\phi$ 的更新趋势:
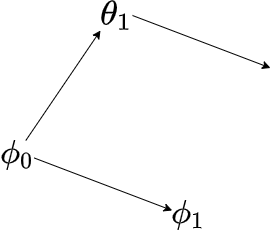
采样 $m$ 个任务,第一次训练完毕得到参数 $\theta_1$,计算 $\theta_1$ 的梯度方向,将 $\phi_0$ 按照梯度方向更新至 $\phi_1$,之后的训练以此类推。
Reptile 方法
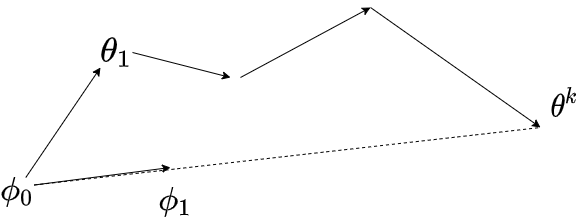
和 MAML 方法类似,但有以下几个点不同:
- 训练任务的网络可以更新多次,以 $k$ 次为例;
- reptile 不再像 MAML 一样计算梯度(因此带来了工程性能的提升),而是直接用一个参数乘以meta网络与训练任务的网络参数的差来更新meta网络参数;(向最终的参数方向去更新)
基于测量的 meta learning 网络结构
这里设想,在之前的 meta learning 中,是 Support Set 先进入网络训练,而后测试集合进入网络并计算误差 $l$。最终多个 $l$ 相加而后反向传播。一个宏观的误差并不能使网络拉开同一组数据中 Support Set 和 Query Set 中不同类的样本的差距,只是用一个总误差更新初始化的参数。看如下的结构图:
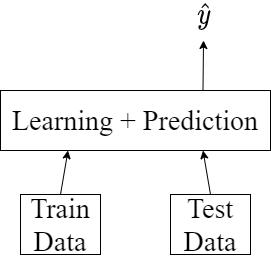
将训练模块和预测模块放到一起,训练数据和测试数据同时进入,以此来达到区分一次训练数据中 Support Set 和 Query Set 的区别,更好的将不同的样本区分开。这里简单介绍两种网络,Siamese Network,Prototypical Network 和 Relatoin Network。
Siamese Network
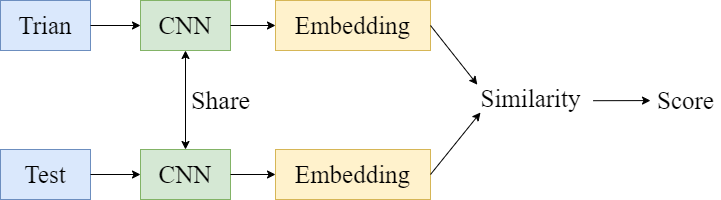
在训练数据中引入一个类,测试数据只有一个类。经过可参数共享的 CNN 后得到嵌入表示,并计算测试数据和训练数据中每个类数据的相似性,以此来计算得分。若测试数据和训练数据中的某个样本属于同一类,则该单元的输出最高。举例说明:
训练数据为类别为1,测试数据的类别为3。那么相似性应该很低,输出的分数也低。如果是同一类,相似度高,输出的分数就高,这就是基于度量的 meta-learning。
其实就是计算的两个样本是否相似,可以看成一个二分类问题。同一类的样本距离近,不同类的样本远。与 AutoEncoder 的区别是,AutoEncoder 是尽可能的复原信息,而不是提取能作为区分的重要信息。
Prototypical Network
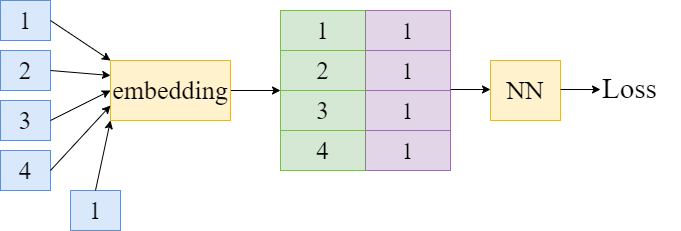
和 Siamese 极为类似,只是输入的训练数据可以有多个类,而不只是限于一个。最后 softmax 一下,测试样本和训练样本属于同一类时,单元输出的值就打。举例说明:
输入数据是1,2,3,4,5这么多个类,每个类一个数据。测试数据的类别是 3。那么,第三个单元的输出最大,其他单元的输出较小。以此来计算相似度,拉开不同类样本在空间中的分布。
当然,这里是可以引入 Triplet loss 的,只需要在训练时加入额外的数据即可。此时训练的数据为:Train data, Untrain data, Test data。其中,Untrain data 就像训练 Word2Vec 时使用的无关词汇一样。这里轻描淡写了,Triplet loss 如何应用到 Siamese 中还请查询具体文章,比如这里。
Relation Network
之前的网络在计算相似度时可能都是使用 $\cos$ 等函数,而 Relation Network 中则使用一个网络来计算相似度。将测试数据的嵌入拼接到训练数据后面,一起进入计算相似性的网络,之后的操作就都一样了。
代码实例
基于梯度
代码实现了 Reptileh和MAML。很简单,只是简单的更新参数的方法,通过小样本采样来学习一个 $y=a\sin(x+b)$ 的函数。强烈建议看代码,看完代码后就知道meta learning 的工作原理了。结果如下(我就训练了几次,次数很少):

基于度量
还没写好,最近课多。
参考与推荐课程
我也不知道我整理的好不好,能不能看懂。不过没关系,我可以推荐一些不错的课程。但恕我直言,看完课程后觉得自己学会了,但自己整理的时候还是发现啥都不会。『一学就会,一练就废』系列。
不错的讲解博客:
https://wei-tianhao.github.io/blog/2019/09/17/meta-learning.html#lstm-meta-learner
有人整理的李宏毅课程的pdf版,MAML后直接讲强化学习调网络结构:
http://www.gwylab.com/pdf/note_meta-learning.pdf
不错的讲解博客:
https://www.tensorinfinity.com/paper_191.html
李宏毅讲解 meta-learning 的课程:
https://www.youtube.com/watch?v=EkAqYbpCYAc&list=PLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index=32

