comm = MPI.COMM_WORLD rank = comm.Get_rank() size = comm.Get_size()
# 主进程 if rank == 0: data = {'x': 1, 'y': 2.0} # 主进程发送字典到所有的子进程 print('Process {} sent data:'.format(rank), data) for i inrange(1, size): comm.send(data, dest=i, tag=i)
# 子进程收到主进程的数据 else: data = comm.recv(source=0, tag=rank) print('Process {} received data:'.format(rank), data)
输出结果:
1 2 3 4 5 6
Process 0 sent data: {'x': 1, 'y': 2.0} Process 0 sent data: {'x': 1, 'y': 2.0} Process 0 sent data: {'x': 1, 'y': 2.0} Process 1 received data: {'x': 1, 'y': 2.0} Process 2 received data: {'x': 1, 'y': 2.0} Process 3 received data: {'x': 1, 'y': 2.0}
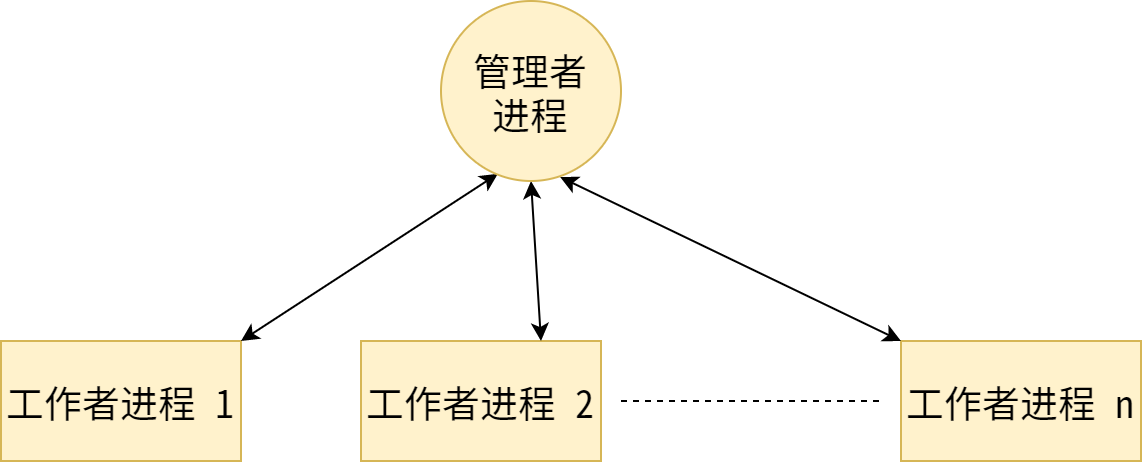
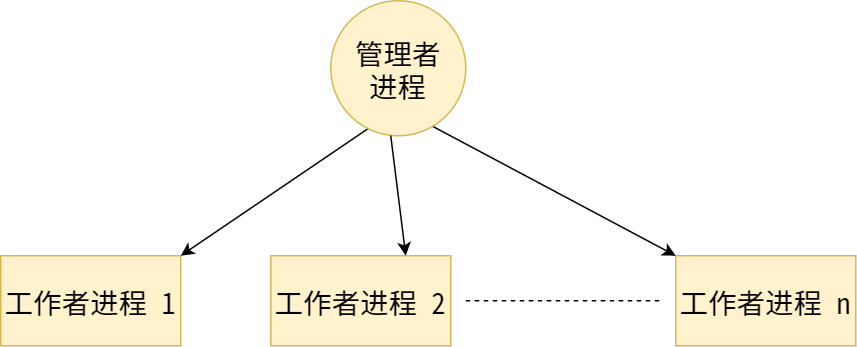
dest表示发送的目标进程的 rank,tag表示消息的 ID,source 表示源头进程的 rank,tag表示信息的 ID。两个 ID 对不上,消息则无法接收。通过 rank 号来设置主进程,在这里,指定的 rank=0 的就是『管理者进程』。然后通过一个 for 循环给其他进程发送数据。当通信的内容很多时,可以使用 tag 来区分不同的消息。
if rank == 0: data = {'x': 1, 'y': 2.0} for i inrange(1, size): req = comm.isend(data, dest=i, tag=i) req.wait() print('Process {} sent data:'.format(rank), data)
comm = MPI.COMM_WORLD rank = comm.Get_rank() size = comm.Get_size()
if rank == 0: data = np.arange(4.0) else: data = None
msg = comm.bcast(data, root=0)
if rank == 0: print('Process {} broadcast data:'.format(rank), msg) else: print('Process {} received data:'.format(rank), msg)
输出为:
1 2 3 4
Process 0 broadcast data: [0. 1. 2. 3.] Process 1 received data: [0. 1. 2. 3.] Process 2 received data: [0. 1. 2. 3.] Process 3 received data: [0. 1. 2. 3.]
comm = MPI.COMM_WORLD rank = comm.Get_rank() nprocs = comm.Get_size()
nsteps = 10000000 dx = 1.0 / nsteps
if rank == 0: ave, res = divmod(nsteps, nprocs) counts = [ave + 1if p < res else ave for p inrange(nprocs)]
starts = [sum(counts[:p]) for p inrange(nprocs)] ends = [sum(counts[:p+1]) for p inrange(nprocs)] data = [(starts[p], ends[p]) for p inrange(nprocs)] else: data = None
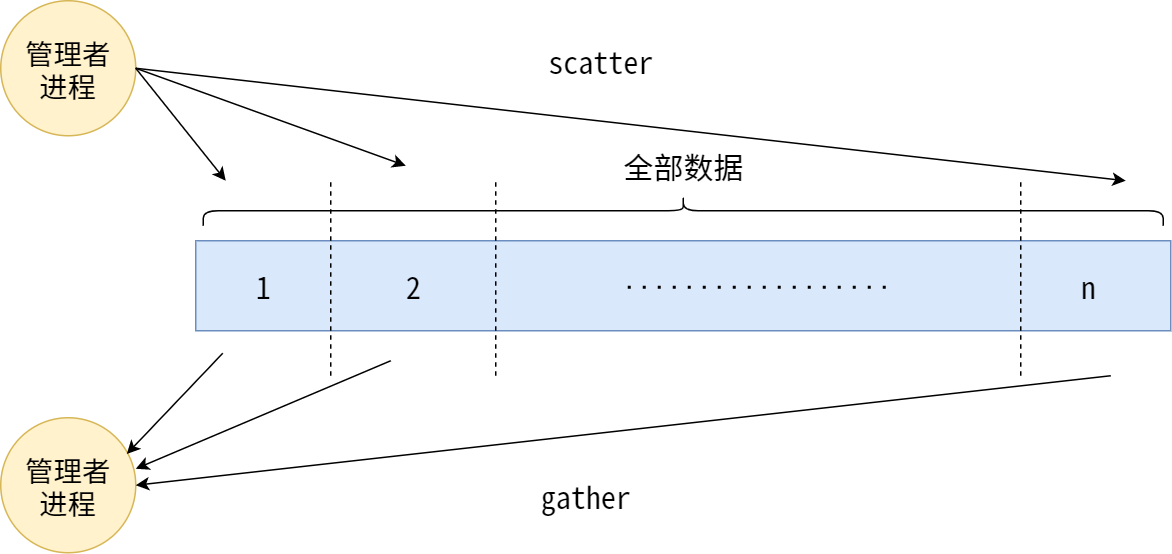
data = comm.scatter(data, root=0)
partial_pi = 0.0 for i inrange(data[0], data[1]): x = (i + 0.5) * dx partial_pi += 4.0 / (1.0 + x * x) partial_pi *= dx
comm = MPI.COMM_WORLD rank = comm.Get_rank() size = comm.Get_size() num = 4
# master process if rank == 0: data = np.arange(float(num)) for i inrange(1, size): comm.Send(data, dest=i, tag=i) print('Process {} sent data:'.format(rank), data)
# worker processes else: # 初始化 data = np.zeros(num) # 接收 comm.Recv(data, source=0, tag=rank) print('Process {} received data:'.format(rank), data)
data作为第一个参数,被写入接收的数据。输出是:
1 2 3 4 5 6
Process 0 sent data: [0. 1. 2. 3.] Process 0 sent data: [0. 1. 2. 3.] Process 2 received data: [0. 1. 2. 3.] Process 0 sent data: [0. 1. 2. 3.] Process 3 received data: [0. 1. 2. 3.] Process 1 received data: [0. 1. 2. 3.]
再使用 Send 和 Recv 的时候需要注意的是发送数据大小和接收的数据大小应该匹配。
如果发送的数据大小大于接收区的缓存大小,将会报错;
缓冲区的数据大小大于发送区的数据大小是没关系的。
1 2 3 4 5 6 7 8 9 10
if rank == 0: data = np.arange(4.) for i inrange(1, size): comm.Send(data, dest=i, tag=i) print('Process {} sent data:'.format(rank), data)
else: data = np.zeros(6) comm.Recv(data, source=0, tag=rank) print('Process {} has data:'.format(rank), data)
上述程序中,发送4个大小的数据,缓冲区用6个大小的数据块去接收,只有前4个数据被覆盖了:
1 2 3 4 5 6
Process 0 sent data: [0. 1. 2. 3.] Process 0 sent data: [0. 1. 2. 3.] Process 0 sent data: [0. 1. 2. 3.] Process 1 has data: [0. 1. 2. 3. 0. 0.] Process 2 has data: [0. 1. 2. 3. 0. 0.] Process 3 has data: [0. 1. 2. 3. 0. 0.]
同样,也有对应的阻塞版本和非阻塞版本。
1 2 3 4 5 6 7 8 9 10 11 12
if rank == 0: data = np.arange(4.) for i inrange(1, size): req = comm.Isend(data, dest=i, tag=i) req.Wait() print('Process {} sent data:'.format(rank), data)
else: data = np.zeros(4) req = comm.Irecv(data, source=0, tag=rank) req.wait() print('Process {} received data:'.format(rank), data)
集体通信
其实这里的内容基本和之前的类似了。
广播
1 2 3 4 5 6 7 8 9 10 11 12 13 14
from mpi4py import MPI import numpy as np
comm = MPI.COMM_WORLD rank = comm.Get_rank()
if rank == 0: data = np.arange(4.0) else: data = np.zeros(4)
comm.Bcast(data, root=0)
print('Process {} has data:'.format(rank), data)
输出是:
1 2 3 4
Process 0 has data: [0.1.2.3.] Process 1 has data: [0.1.2.3.] Process 3 has data: [0.1.2.3.] Process 2 has data: [0.1.2.3.]
After Scatterv, process 0 has data: [0. 1. 2. 3.] After Scatterv, process 1 has data: [4. 5. 6. 7.] After Scatterv, process 2 has data: [8. 9. 10. 11.] After Scatterv, process 3 has data: [12. 13. 14.]
partial_sum = np.zeros(1) partial_sum[0] = sum(recvbuf) print('Partial sum on process {} is:'.format(rank), partial_sum[0])
total_sum = np.zeros(1) comm.Reduce(partial_sum, total_sum, op=MPI.SUM, root=0) if comm.Get_rank() == 0: print('After Reduce, total sum on process 0 is:', total_sum[0])
输出是:
1 2 3 4 5
Partial sum on process 0 is: 6.0 Partial sum on process 1 is: 22.0 Partial sum on process 2 is: 38.0 Partial sum on process 3 is: 39.0 After Reduce, total sum on process 0 is: 105.0