本文以 pytorch 为框架,分别从数据并行训练的方法(DataParallel, DistributedDataParallel)、并行加载数据两个角度,阐述了本次实验中并行算法的设计思想,并对并行实现的原理进行了解析,包括多进程的工作流程和通信方法等。语言这么正规的原因是:这是从大作业里面摘出来的。神经网络那部分我就不写了,跑题,最后直接给代码。
环境
硬件设备
- CPU:2个Intel(R) Xeon(R) Gold 5115 CPU \@ 2.40GHz,10核心20线程。
- GPU:4路Tesla P40,每路显存容量22GB,共88GB。
- 内存:128GB。
- 外存:520TB可用,已用15TB。
软件环境与版本
- 运行程序的系统为 CentOS Linux release 7.3.1611。
- 开发程序的系统为 Arch 5.9.6。
- python:3.8.2:作为开发语言。
- pytorch:1.6.0:作为模型实现的工具,借助其提供的API实现并行。
- ssh:OpenSSH_8.3p1, OpenSSL 1.1.1h,实现远程登录功能,即本地登录到服务器。
- scp:实现文件传输功能,将本地文件传输至服务器,或将服务器文件传输至本地。
并行加载数据
在加载数据时,可以使用多进程来加载数据。不使用多线程的目的是:python 的多线程因为 GIL(Global Interpreter Lock)的存在,只能在单核运行。不能发挥多核处理器的优势,因此只适合 I/O 型任务,不适合密集计算型任务。
首先以 torch.utils.data.Dataset 为父类,创建一个加载数据集的子类:MiniImagenet。在 MiniImagenet中,设置__getitem__方法来支持数据集的切片访问,即批量加载数据。
在训练阶段,实例化加载数据集的类,得到一个实例对象。在 torch.utils.data.DataLoader 中传入实例对象来加载数据,并设置其他参数来提升加载数据的速度和数量。设置 num_workers=8 可以使用 8 进程来加载数据,设置 batch_size=batchsz 对应 MiniImagenet 类的 __getitem__ 切片访问,即一次获取的训练数据的大小。
在创建 num_workers 个进程之后,多个进程共享一份数据集,将指定 batch(一批待加载的目标数据)分配给指定 worker(一个进程),worker 将对应 batch 的数据加载进内存。因此增大 num_workers 的数量,内存的占用率也会增加。在第一个 batch 的数据加载完成后,会等待主进程将该 batch 取走并汇总,而后此 worker 开始加载下一个 batch,不断迭代。
主进程采集完最后一个 worker 的数据后,此时需要返回并采集第一个 worker 加载的第二个 batch。如果第一个 worker 此时没有加载完,主线程将阻塞等待当前 worker 的数据加载完毕。最后所有数据加载完毕后,汇总到一起供用户使用。
当 num_worker 设置的很大时,优点时可以快速的寻找目标 batch;缺点是内存开销大,也加重了 CPU 维护进程的开销,如创建、初始化、通信、分配任务、接受任务反馈和销毁进程等。num_workers 的经验设置值是服务器的 CPU 核心数,如果 CPU 性能强大且内存充足,可以设置为较大的数值。
DataParallel
DataParallel 并行方式实现较为简单。首先将模型放到主 GPU 中,一般是 GPU-0;而后将模型复制得到副本,将模型副本放到另外的$n$张 GPU 中,将输入的batchsz大小的数据平均分为$n$份依次作为每个模型副本的输入。因此要求 batchsz 的大小要大于 GPU 的数量,否则数据无法分配,会导致有的模型副本得不到数据。
每个模型副本独立的进行前向计算,得到各自的 loss值。在$n$个GPU完成计算后,将 loss 汇总到 GPU-0 中,由 GPU-0 中的模型进行反向传播和更新参数。更新好参数后,由 GPU-0 将参数分发至其他$n$个 GPU 卡,开始新一轮的计算。DataParallel 并行结构示意图如图所示:
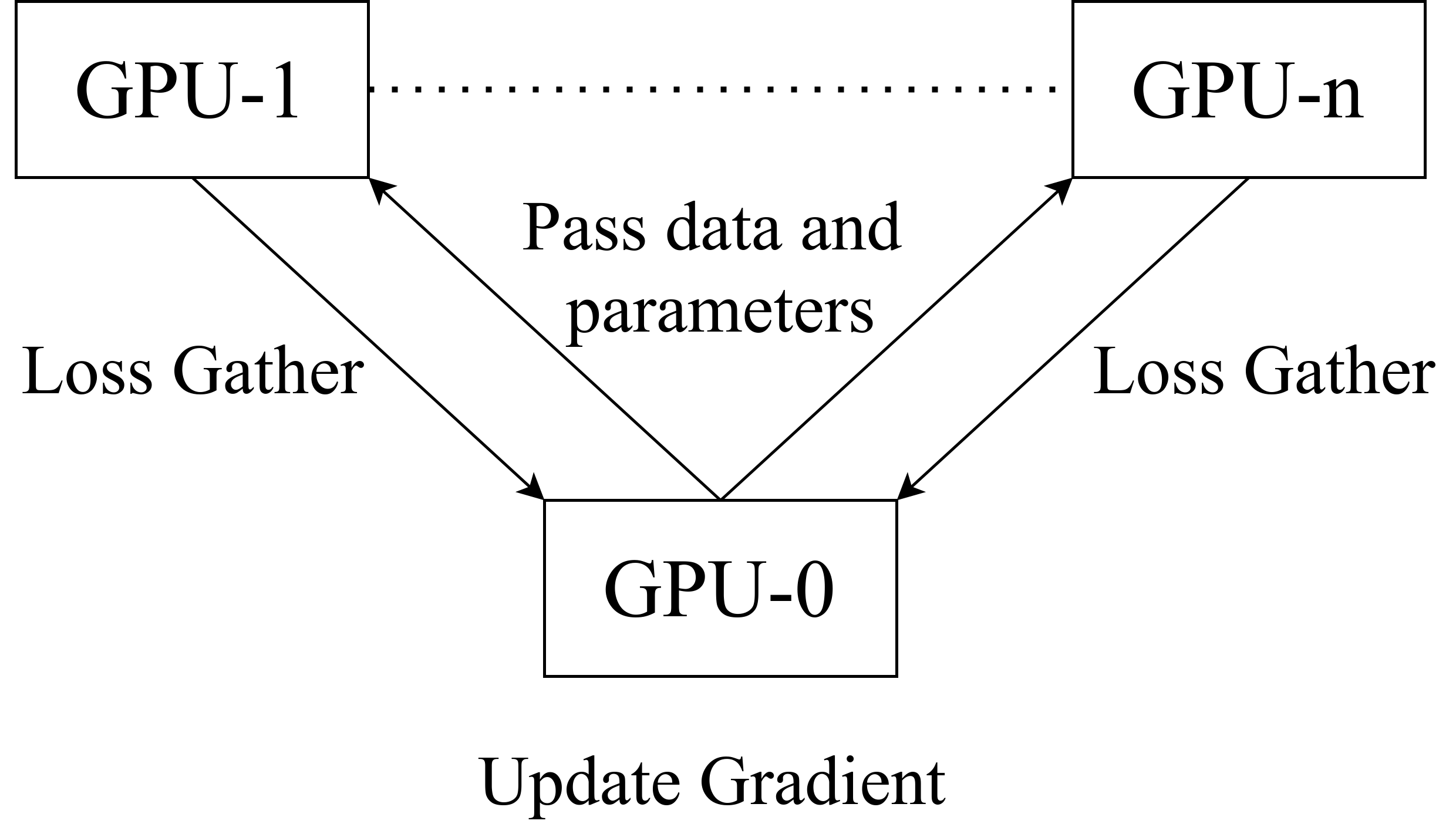
DataParallel基于单进程多线程实现,因为python的多线程无法利用多核处理器,只能在单核上进行任务调度和参数更新的通信,所以此种方式并行效率较低,且0号卡负担较大。
DistributedDataParallel
DistributedDataParallel 并行方式实现较为复杂,且相对于 DataParallel 需要更大的显存空间。DistributedDataParallel 使用的进程数量一般和GPU数量相等,对每个进程创建一个 DistributedDataParallel 实例,通过进程通信来同步梯度,通信方式为 AllReduce 。
在任务初始化阶段,即并行程序执行之前首先要创建通信群组,通信群组中的每一个进程创建一个 DistributedDataParallel 实例。DistributedDataParallel 通过rank0(进程ID)将当前模型的结构和参数等状态通过广播通信的形式发送到进程组的所有进程中,确保其他进程中的模型副本和当前模型保持一致。而后,每个进程创建一个本地的Reducer,用于反向传播阶段同步参数的梯度。因此相比于DataParallel, DistributedDataParallel 需要更大的显存容量。为了提升通信效率,Reducer将参数放到多个桶中,每次以桶为单位进行通信。
模型参数需要额外附加 unready 和 ready 两种状态,默认为 unready 状态。若参数在反向传播阶段计算了梯度,则参数由 unready 状态变为 ready 状态,表示这个参数可以同步到其他模型;否则保持 unready 状态。当模型完成一次训练后,参数由 ready 状态变为 unready 状态,为下一次训练做准备。
因为在反向传播阶段,DistributedDataParallel 只会等待 unready 状态的参数更新,所以在前向计算阶段首先要分析计算图,将不进行梯度更新的参数状态永久设为 ready 状态,防止这些参数影响反向传播。DistributedDataParallel 在获取输入数据后,将输入数据分发到每个 GPU 中,模型副本开始前向计算得到各自的 loss 值,而后开始反向传播。
DistributedDataParallel 在初始化阶段会为每一个可求导的参数申请一个自动求导的钩子,来发射同步梯度的信号。在反向传播阶段,当一个参数计算梯度后会为 ready 状态,对应梯度的钩子就会发射信号,DistributedDataParallel 会标记该参数的状态,表示该参数的梯度可以用于同步。当一个桶内的参数全部由 unready 状态变为 ready 状态后,Reducer通过AllReduce的通信方式来更新桶内的参数,来计算所有模型副本中参数梯度的平均值。
以4个GPU为例,其 AllReduce 通信方式如下图所示。
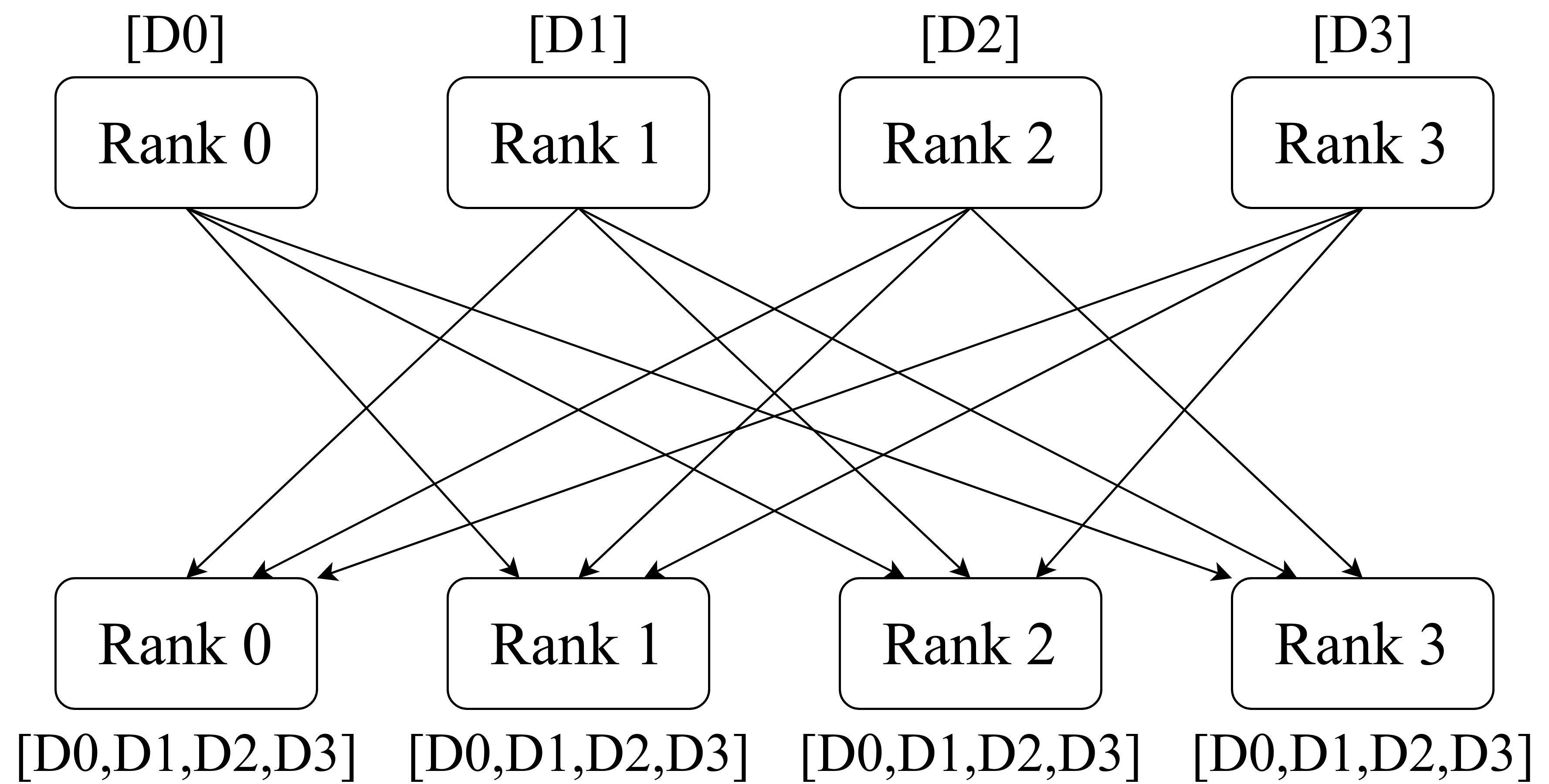
在上图中,rank0 将自己模型副本的梯度 D0 发送给 rank1,rank2和rank3,其他进程同理。因此在 AllReduce 通信后,所有的模型副本的梯度值保持一致。
当所有的桶更新完毕后,Reducer 会阻塞等待 AllReduce 的所有操作结束,如重新将参数设为 unready 状态。因为所有模型副本的梯度值相同,所以在梯度更新阶段,只需更新本卡中的模型参数。因为所有的模型副本来自相同的初始状态,且具有相同的平均梯度值,所以在梯度更新后所的模型副本状态都会保持一致,以此来实现并行。
对比
DataParallel 和 DistributedDataParallel 都属于数据并行的方法,在分析完各自的实现原理后,可以得到二者的对比。对比情况如下表所示:
| 参数 | DataParallel | DistributedParallel |
|---|---|---|
| 机器支持 | 只支持单机 | 可支持多机 |
| 模型支持 | 不支持拆分模型 | 可以将模型放到多张GPU中 |
| 通信方式 | scatter input 和 gather output | scatter input 和 AllReduce |
| 并行支持 | 只支持数据并行 | 支持数据并行和模型并行 |
| 进程与线程 | 单进程、多线程 | 多进程 |
这里需要注意的是,如果将batchsz太小,由此可见,AllReduce在数据量很小的情况下,每一次梯度更新带来的进程通信、任务调度与分配的开销占比会增大,而用于数据通信的开销占比却很小,导致并行效率没有明显提升。因此AllReduce不适合数据量较小情况下的通信。这里我尝试过。
代码
https://github.com/muyuuuu/Algorithm/tree/master/meta-learning/Metric-based/Relation-Netowrk

