前阵子写了个集群计算资源监控程序,我觉得架构设计的还行,于是来整理成一篇博客。内容只有架构,不含代码,因为自己的实验室要用。利益相关,人在美国,刚下飞机,懂的自然懂,匿了匿了。
集群架构
首先来看一下集群的结构,也就是计算节点如何连接,以及每个计算节点配备的计算资源如何,方便编写后续程序。
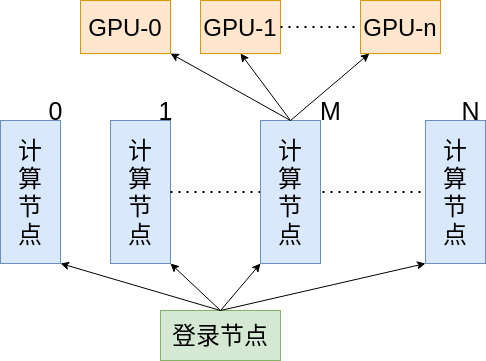
首先 ssh 到登录节点,而后可以由登录节点前往各个计算节点,假设这里一共由 N 个计算节点。其中,第 M 个计算节点配备了 n 个 GPU。这里就假设要监控 GPU 资源了,如果要监控 CPU 资源,一个道理。
多线程工作模式
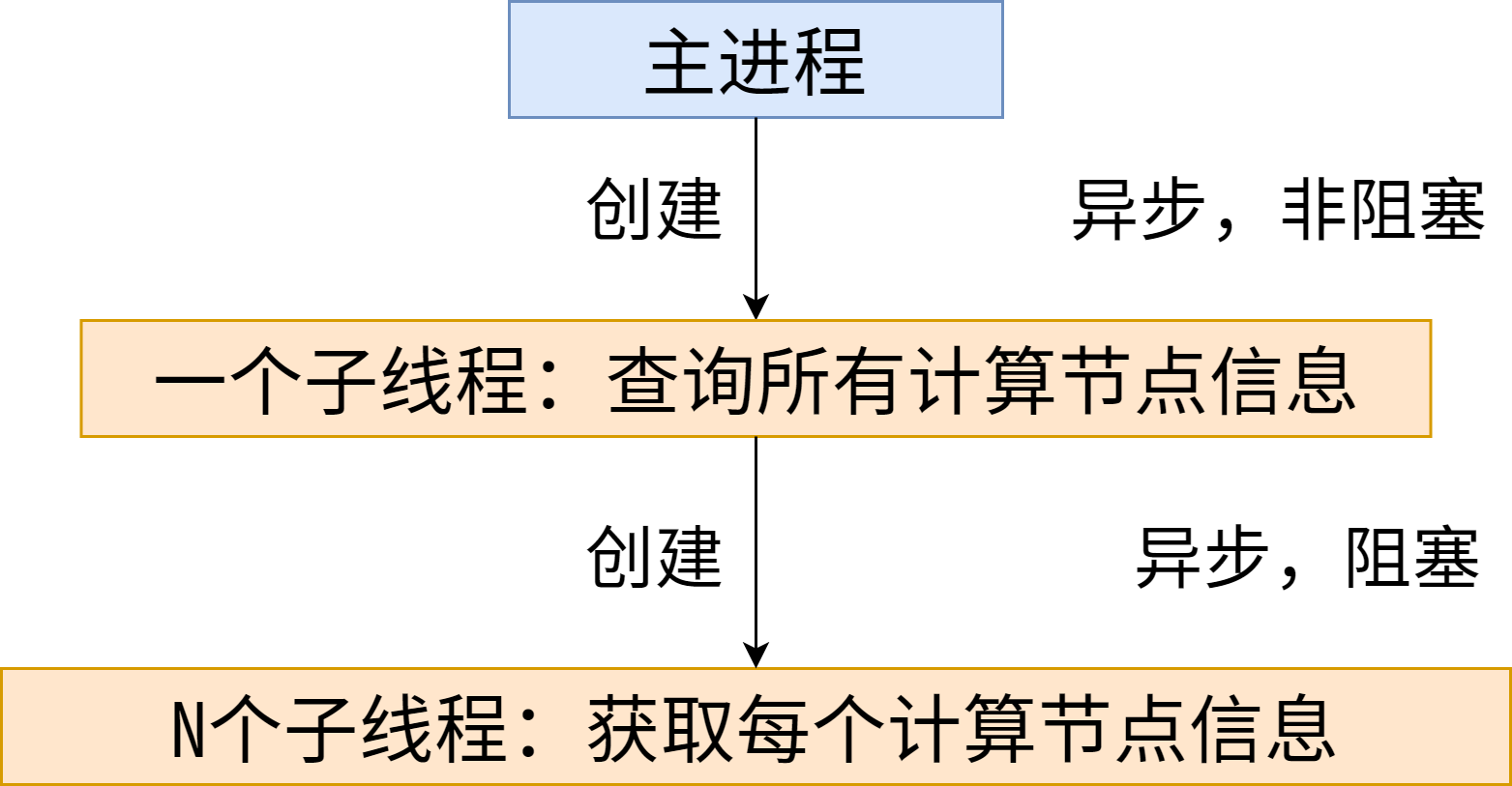
既然要监控这么多 GPU 的占用情况,轮询显然是一种最差的做法,毕竟 ssh 过去有网络延迟,且同步阻塞调用的方式效率很是低下。首先通过多线程的形式,将阻塞调用改为异步非阻塞调用。
这里,我们创建一个子线程去完成 GPU 负载信息的查询任务,使其不影响主进程的执行,这实现了异步;在子线程查询 GPU 负载信息时,再次创建多个子线程并发的完成查询,对于结果的返回选择非阻塞的方式,啥时候结果执行完了反馈回来就行;但多个子线程阻塞了子线程的执行,因为毕竟要等到多个子线程拿到结果才能返回,不然白执行一趟。理论上这里也应该非阻塞,但非阻塞也不需要去执行其他任务,索性让它阻塞在这里。
当然,我这里计算节点很少,可以为每个节点创建一个线程。当面临成百上千个计算节点时,可以分组创建线程,一次性创建这么多线程,维护、切换之类的开销太大了。
此时多线程的调用结构图如下所示:
主进程核心代码如下:1
2
3
4
5
6
7
8
9
10# 主进程创建子线程定期轮询
def monitor(compute_num, shell_path, timeout):
set_gpu_infoes_list(
get_all_gpu_node_info(compute_num, shell_path, timeout))
threading.Timer(interval, monitor, (compute_num, shell_path, timeout)).start()
if __name__ == '__main__':
th = threading.Timer(interval, monitor, (compute_num, shell_path, timeout))
# 子线程去访问GPU信息,主进程干其他的
th.start()
子线程核心代码如下:
1 | # 子线程创建多个子线程去查询 |
log 写出
这个是为了记录计算资源的历史使用信息准备的,每个计算节点一个 log 文件,每个 log 文件限长 1000 行,超过 1000 行后就先入先出处理掉。

