忙完了其它的,还是要回归科研做好整理,相当于论文笔记吧。对抗样本去噪算法算是告以段落,或者说叫对抗样本提纯。本文总结了一些近几年的、思路还行结果也还好的对抗样本去噪算法,就相当于写个类似的综述了,注意,并非详解。优缺点仅是个人分析,其实论文读多了或者看了代码,总会有一些想法。包含以下论文:
- Comdefend: An efficient image compression model to defend adversarial examples, CVPR 2019
- Feature denoising for improving adversarial robustness, CVPR 2019
- Defense against adversarial attacks using high-level representation guided denoiser, CVPR 2018
- A Self-supervised Approach for Adversarial Robustness, CVPR 2020
- Denoised Smoothing: A Provable Defense for Pretrained Classifiers, NIPS 2020
- Stochastic Security: Adversarial Defense Using Long-Run Dynamics of Energy-Based Models, ICLR 2021
- Online Adversarial Purification based on Self-Supervision, ICLR 2021
- Adversarial Purification with Score-based Generative Models, ICML 2021
ComDefend
来自论文:Comdefend: An efficient image compression model to defend adversarial examples, CVPR 2019。
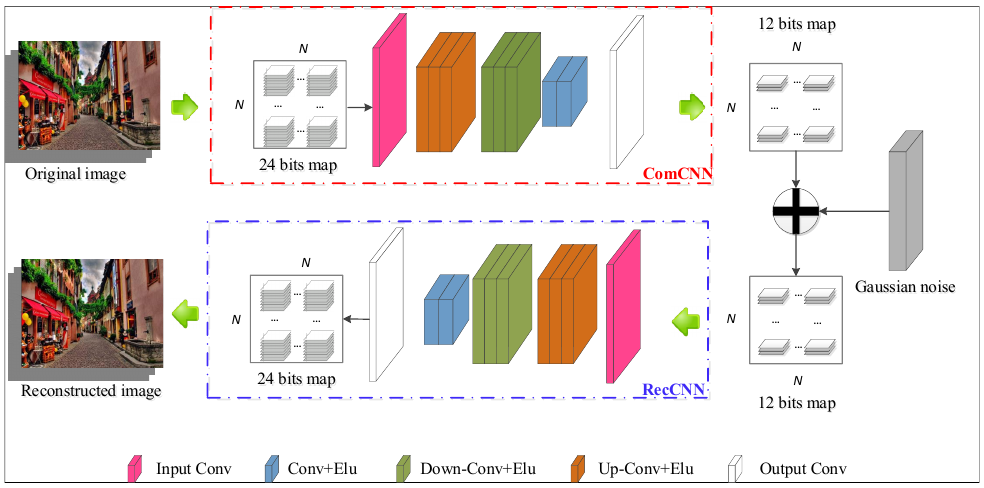
- 核心思想,在目标模型之前训练一个编码器和解码器,编码器的目标是提取图像的结构信息,移除冗余信息;解码器的目标是重构输入的图像,移除扰动信息。
- 损失函数,对于编码器,使用更多的 0 来编码图像,因此损失为 $\lambda \Vert Com(\theta_1, x) \Vert^2$,使其尽可能的小;对于解码器要尽可能的重构原始图像,因此损失为 $\Vert Rec(\theta_2, Com(\theta_1, x)+\phi) -x \Vert^2$,$\phi$ 是高斯噪音。最终的损失是两者相加,两个模型的参数是同时训练和更新的。但是我在复现的时候,发现 $\lambda = 0.0001$,也能猜出这篇论文的大概效果。
对抗样本在输入层的扰动其实只是很小的一部分,微小的扰动会在模型隐层无限放大。这篇论文只是在输入层去除对抗样本的扰动信息,没有考虑在模型隐层去除扰动信息。
Feature Denoising
来自论文 Feature denoising for improving adversarial robustness, CVPR 2019。如下图所示,论文注意到了对抗样本在模型高层的巨大差异信息,所以,选择了在模型的高层对数据进行去噪,而不是输入层。
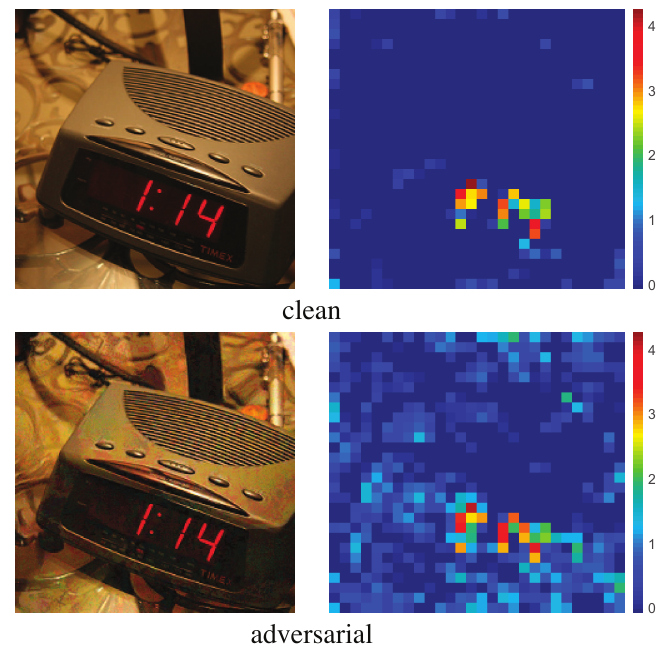
论文选择的去噪方式也很简单,对于特征图 $y$,对于一个区域 $L$,重新计算其表示:
\begin{equation}
y_i=\frac{1}{C(x)}\sum_{j \in L} f(x_i, x_j) \cdot x_j
\end{equation}
其中,$f(x)$ 有多种选择,论文中给出了:高斯函数、内积、和一些滤波器。
HGD
来自论文:Defense against adversarial attacks using high-level representation guided denoiser, CVPR 2018。
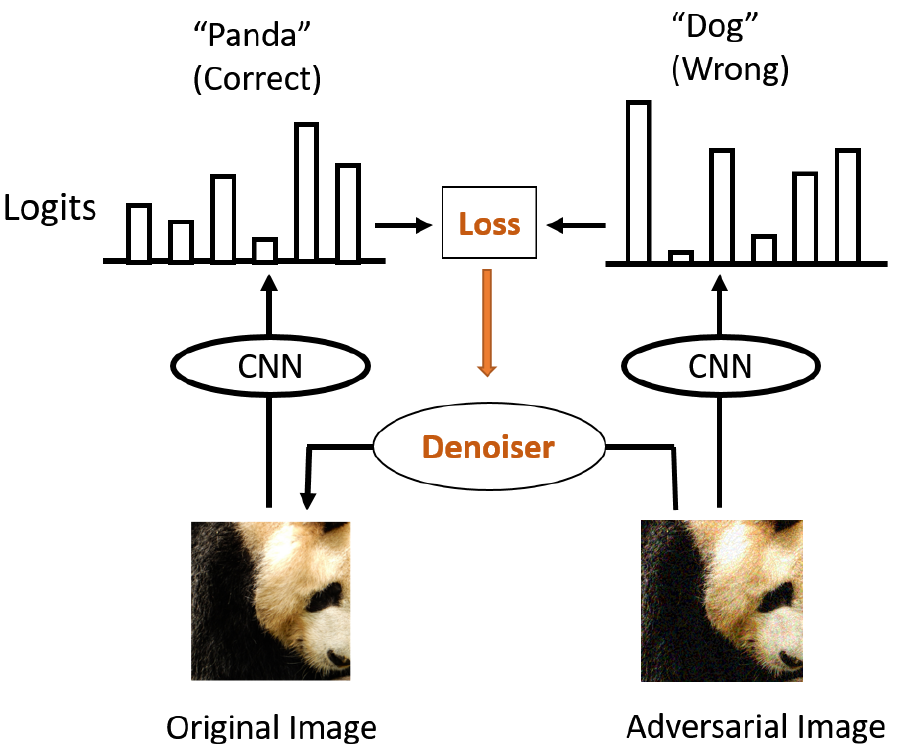
核心思想:基于干净样本和对抗样本在模型高维的差异来指导去噪器的训练。设 $x$ 为干净样本,$x^\star$ 为对抗样本,$\hat{x}$ 为对抗样本去噪后的样本。论文选择 U-Net 结构对样本进行去噪,输入为 $x^\star$,输出为同等大小的 $-d\hat{x}$,那么 $\hat{x}=x^\star - d\hat{x}$,使用 $L_1$ 范数作为 $\hat{x}$ 和 $x$ 的损失。第二个损为 $f_l(x)$ 与 $f_l(\hat{x})$ 的 $L_1$ 范数,即去噪样本和干净样本在模型第 $l$ 层的差异应尽可能接近。
我觉得这篇论文的思想是不错的,所以在我的工作中也借鉴了这篇论文的思想。分别在模型的输入层和隐层对对抗样本进行去噪,不过其他内容则不一样了。
NRP
来自论文:A Self-supervised Approach for Adversarial Robustness, CVPR 2020。这篇论文我也复现了,讲真复现结果很差。一方面是论文中给出的参数不合理,一方面是论文并没有对一些东西解释清楚,最重要的是不仅没给代码,还没说怎么实现他的代码,也没有说某些实验参数,所以我只能按照论文描述来实现代码了。那为什么还要写呢?因为这篇论文借鉴 GAN 的思想来去除扰动,还是感觉有一点点新意的。
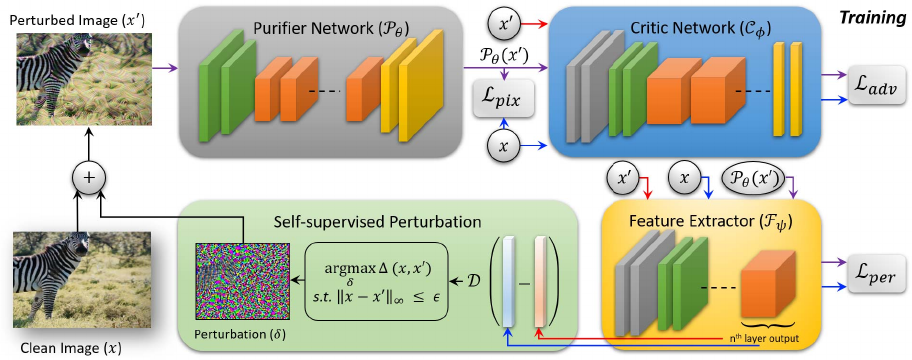
作者定义一个提纯网络 $P$ 用于去除噪音,定义判别网络 $C$ 来判断当前样本是对抗样本还是干净样本,定义 backbone $F$ 来提取对抗样本和干净样本的特征差异生成自监督扰动,将扰动叠加至干净样本生成对抗样本,作为 $P$ 的训练数据。$P$ 去噪后传送给 $C$,以此来定义 $P$ 去除扰动的好坏。损失函数由三个部分组成,最终带权相加组成最终的损失函数:
- 对抗损失是 $P(\hat{x})$ 和 $x$ 在判别网络 $C$ 上的相似度
- 特征损失为 $F(x)$ 和 $F(\hat{x})$ 的欧式距离
- 像素损失为 $P(\hat{x})$ 和 $x$ 的欧氏距离
Denoised smoothing
这篇论文来自 Denoised Smoothing: A Provable Defense for Pretrained Classifiers, NIPS 2020。
写这篇论文并不是因为这个论文发表的等级高、时间新。而是因为,我发现一些对抗去噪采纳了集成的思想,这篇论文就是其一。借助多个分类器的投票结果指导去噪器的训练,三个臭皮匠,赛过诸葛亮,何况分类器呢?如果你对集成感兴趣,可以考虑沿着这个方向做下去。这个论文还算是集成思想中比较保守的了。
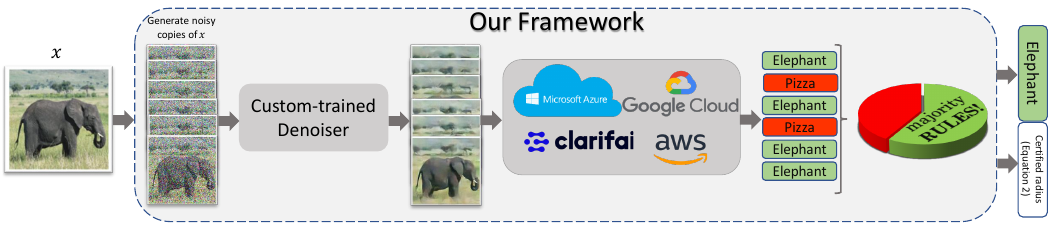
但是呢,我是比较反感堆叠模型这样的方案的,这就相当于应该花 3 年去准备高考,而你花了 21 年去准备,效果虽然好,但是成本太大了。应该设计算法去提高一个模型的准确度,而不是多个模型投机取巧,另外我也没这样大规模的算力。
这篇论文写了一个单独的博客,也给出了程序,思路还是比较清晰的,在损失函数上,先用去噪后的图像和原始图像的 MSE 作为损失,再用去噪后的图像和原始图像在高维的差异作为损失微调。
EBM-defense
论文来自 Stochastic Security: Adversarial Defense Using Long-Run Dynamics of Energy-Based Models, ICLR 2021。模型啥的也比较简单,但是我比较反感堆叠模型的操作,丑拒这样的 idea。
SOAP
来自论文 Online Adversarial Purification based on Self-Supervision, ICLR 2021。这篇论文在模型、算法还是有一定创新度的,也是我重点复现的论文之一。不过这篇论文虽然有对抗样本提纯的概念,但严格意义来说,属于对抗训练的论文,应为这个算法会修改目标模型的参数。
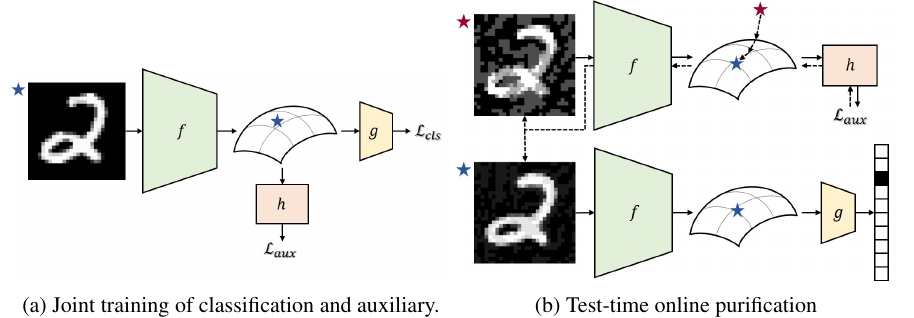
- 在训练阶段,设计两个损失,第一个损失是目标模型的分类损失,第二个损失是子监督扰动的损失,企图网络能够去除自监督扰动,以此抵御对抗样本的攻击。
- 在推理阶段,通过子监督扰动损失的指导,去除对抗样本的扰动信息,之后再进行推理。(具体可以看代码)
论文的目标损失是:
\begin{equation}
\min_\theta L_{\text{cls}}((g\circ f)(x;\theta_{\text{enc}}, \theta_{\text{cls}}), y) + \alpha L_{\text{aux}}((h\circ f)(x;\theta_{\text{enc}}, \theta_{\text{aux}}))
\end{equation}
$g$ 是分类器的前部分,$h$是辅助分支的模型,不过实际代码中这俩被合二为一了,也就是,一个神经网络有两个损失。
对于 $L_{\text{aux}}$ 损失,论文给出了三种选择,在实现时选择其中的一种即可。
- 叠加噪音,即图像叠加噪音后,还是之前的图像。这里的损失使用了叠加噪音前后的 MSE 差异。
- 图像旋转,即图像旋转后,还是之前的图像。这里的损失使用了旋转后图像与真实标签的交叉熵作为损失。
- 标签持续性,即图像经过两种数据增强后,这两组图像的标签一致。这里的损失是两种数据增强后的 MSE 差异。
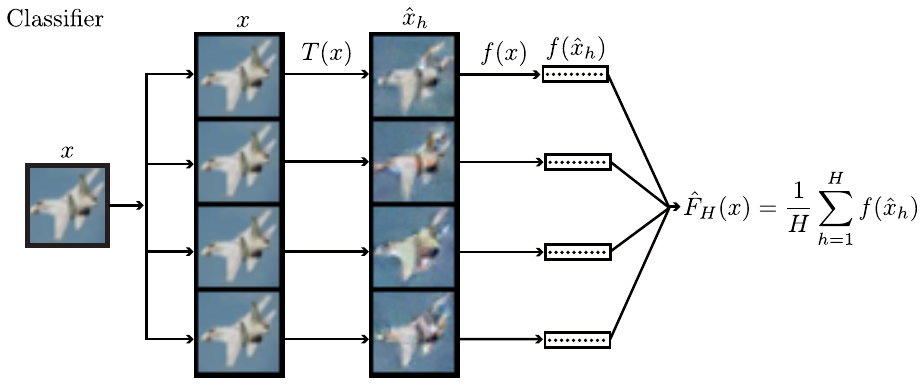
在去噪阶段,论文提出了多部去噪,一定程度弥补了之前单步去噪的缺陷:

ADP
来自论文 Adversarial Purification with Score-based Generative Models, ICML 2021。我复现了这篇论文,训练缓慢、预测缓慢,且不提供训练代码只提供预测代码,预测代码和论文算法描述不一致。前面的模型是别人的,如果没看到这一点,我都不知道怎么复现论文。如果一定有评价的话,那就是:呵,tui。
模型来自「Improved techniques for training score-based generative models」这篇发表在 NIPS 2020 的论文,所以网络结构直接看这篇论文的代码即可。损失函数的设计如下(前面那堆推导没啥用):
\begin{equation}
L(\theta, \sigma) = \mathbb{E}_{q(\tilde{x}|x)p_{\text{data}}(x)}[\frac{1}{2\sigma^2} \Vert \tilde{x} + \sigma^2 s_\theta(\tilde{x}) -x \Vert^2]
\end{equation}
$q(\tilde{x}|x)$ 是以 $x$ 为中心,以 $\sigma$ 为均方差生成的噪音样本。这个损失的意思是,期望 $s_{\theta}$ 能够有效去除 $\tilde{x}$ 上含有的噪音信息,并且和原始图像差不多,以此来抵御对抗样本的攻击。
预测阶段极度风骚,来看伪码:

一步去噪不到位,居然用多步去噪……这样与其他算法对比并不公平,这就像之前举的参加高考的例子。当然这不是最离谱的,最离谱的是,代码和这个算法毫不相关。
1 | for i in range(max_iter): |
结语
当然,还有一系列的其他算法,如 Feature squeezing, JPEG Compressionm,TVM 等算法,我感觉不如之前的论文有意思,所以没有详细的写,读者有兴趣的话可以自己去看一看。
接下来,会看一些攻击方向的经典论文而后复现,大概一周吧,之后会转入全新的领域:对抗训练,偏数据分布的处理,如果有兴趣欢迎联系(是妹子就更好了(误。

