去年寒假接到了一个遥感图像语义分割的任务,存在着严重的类别不平衡问题。当时想着使用经典的类别不平衡损失 focal loss 和 dice loss 解决一下,但是效果不升反降,甚至不如传统的交叉熵损失函数。
而且我在 github 上搜类似的项目,也都不推荐使用这些 loss。但是在 mmseg 的文档中,我们又发现 dice loss 有明显的提升,来冷静分析一下这是为什么。本文默认读者了解 focal loss 和 dice loss,因此不会对损失函数进行讲解。
其实我也不是第一次遇到这种经典损失函数失效的现象,之前 triplet loss 也频频失效,一度上了我的黑名单。关于 trilet loss 何时失效以及为什么 and 如何解决,可以参考之前的文章,如何更好的提取文本表示。但是我们需要知道的是,失效分两种情况,一种是实现错误,一种是不适用于当前场景。
focal loss
focal loss 是目标检测领域中很经典的存在,focal loss 和 retinanet 发在同一篇论文,我看源程序,发现在实现上有一些小细节是网上常见博客不曾提及的。我们知道基于 anchor 生成检测框时,会有大量的无效检测框,这些框和真实目标毫不相交,这就导致了样本不平衡的问题。而 focal loss 的解决方案也是简单粗暴,使用 $\alpha$ 控制正负样本不平衡问题,使用 $\gamma$ 控制难易样本的区分。
在实现中,作者将与真实目标框 IoU 大于 0.5 的视为正样本,IoU 小于 0.4 的视为负样本,还有介于两者之间模棱两可的模糊样本。将所有的预测结果和真实标签计算损失,我们希望正样本的分类结果接近 1,其余样本接近 0,因此有严重的类别不平衡问题,于是使用了 focal loss 进行缓解。但是在反向传播的时候,并不是所有预测结果都要反向传播,而是对损失进行筛选,只回传正样本部分的损失,其余损失不考虑。
不然那么多负样本在那里,假设有 10000 个预测结果,只有 10 个真实目标,我就算输出 10000 个 0 损失也不会低,但是检测不到目标,俗称模型坍塌。因此源程序中做了这样的处理。
那么为什么语义分割的时候失效了呢?看完程序我大概给出我的猜测(目前实在没有精力做消融实验),我看了一些语义分割经典仓库中 focal loss 的实现,发现了一个问题。假设分割时的图像大小是 $512\times 512$,那么这就有将近 27 万个预测结果,遗憾的是,这些全部参与了反向传播。尤其是遥感领域的图像分割,目标区域小,背景占据大部分面积,前景目标的面积占比很小时,这就导致了模型坍塌的问题:模型把所有像素点预测为背景,损失不低,但结果无效。
因此,一个简单的解决方案就是:像 retinanet 一样,并不是所有的预测结果都参与反向传播。只需按照真实标签,只选择前景区域所在位置的损失,而忽略掉大部分背景区域的损失。而我遇到的原因也是这样,smp 的实现是全部反向传播,提交个 PR 吧。而 mmseg 的实现则是取消其他类别的影响。
focal 程序实现
dice loss
dice loss 很神奇,可以说是为语义分割而诞生的。因为交叉熵定义的是分类损失,评估衡量结果时却用 mIoU,也就是优化目标和期望目标不一致,所以 dice loss 以类似 IoU 损失的想法优化目标。dice loss 的一个形式如下:
\begin{equation}
L=1-\frac{2I+\epsilon}{U+\epsilon}
\end{equation}
$I$ 表示预测结果和真实标签的交集,$U$ 表示两者的并集。而程序实现也非常简单,交集两者求乘积,并集两者求和即可。
我们以二分类为例,假设模型最后的逻辑输出为 $x$,预测输出 $\hat{y}=\text{sigmoid}(x)$。于是:
\begin{equation}
\hat{y}=\frac{1}{1+e^{-x}} \quad \frac{d\hat{y}}{dx}=\hat{y}(1-\hat{y})
\end{equation}
我们设真实标签为 $t$,那么 dice loss 为:
\begin{equation}\label{dice}
L=1-\frac{2t\hat{y}+\epsilon}{t+\hat{y}+\epsilon}
\end{equation}
对 $\hat{y}$ 求一个偏导:
\begin{equation}\label{grad}
\frac{dL}{d\hat{y}}=-\frac{2t(t+\hat{y}+\epsilon)-2t\hat{y}-\epsilon}{(t+\hat{y}+\epsilon)^2}
\end{equation}
画出这个损失和梯度的图像:
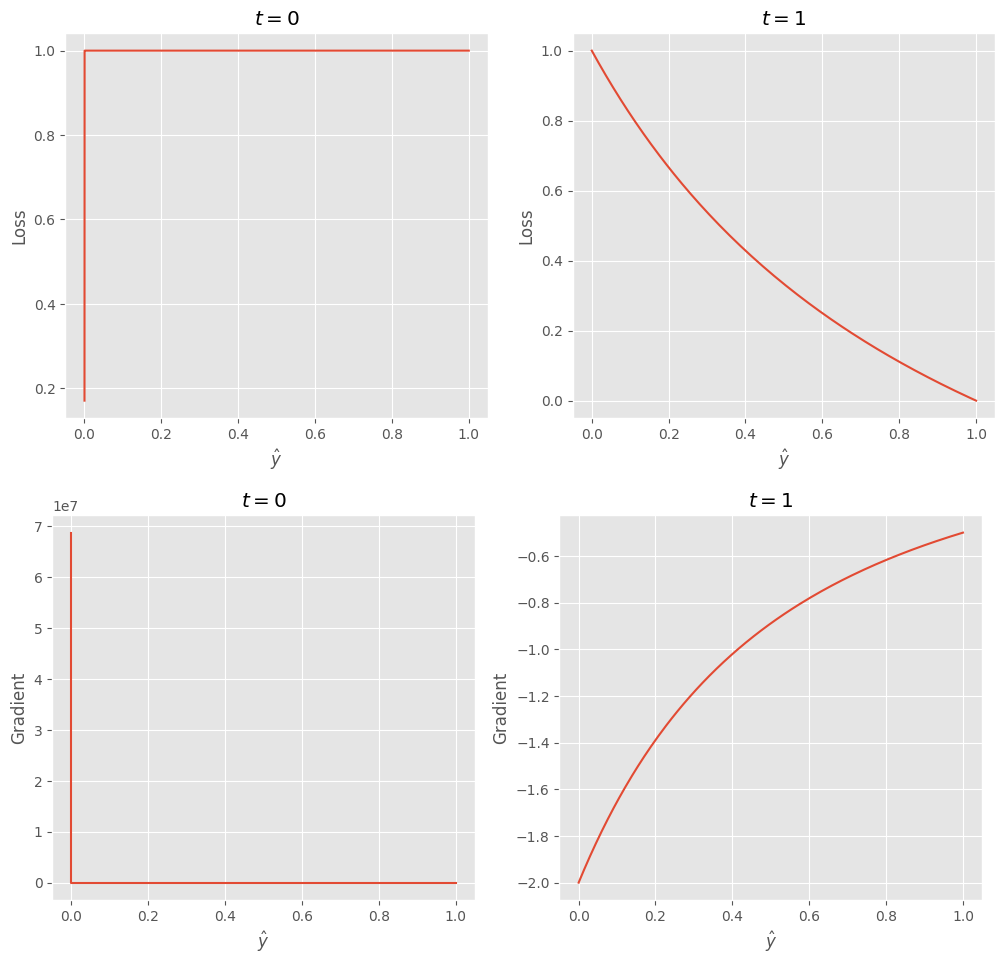
这也就解释了为什么 dice 训练损失不稳定的原因,当 $t=0$ 的时候,虽然损失很大,但更新网络时对应的梯度为 0。损失值不稳定还可以理解,但是如果 $\hat{y}$ 预测结果也很小时,梯度会飞升。那为什么推荐和 CE 一起使用呢?看上图就可以知道,$t=0$ 的部分没有梯度。那为什么还是结果十分不好呢?继续往下看。
dice loss 与不平衡问题
我们可以观察到 dice loss 不管图片有多大,固定大小的正样本的区域计算的 loss 是一样的,对网络起到的监督贡献不会随着图片的大小而变化。而 ce loss 会公平处理正负样本,当出现正样本占比较小时,就会被更多的负样本淹没。
而 mmseg 给出这两个损失的比例是 1(CE):3(dice),我也天真的用了这个比例。通过上面的分析,为了平衡样本,这个比例应该是目标面积和背景面积的比值。但是,我的数据集有多个类,每个类的面积占比跨度很大,也就是正负样本的梯度难以平衡,我十分不建议使用这个 loss,真的。
dice loss 画图程序
1 | import matplotlib.pyplot as plt |
结语
我使用 mmseg 的 focal loss,结果要比 smp 的 focal loss 好很多,验证了我的猜想。此外需要注意的是,focal loss 能处理类别不平衡和正负样本不平衡,而 dice loss 只能处理正负样本不平衡。

