不出意外的话,这应该是 python 复习的最后一部分了,之前写 python 的时候,一般是在实践中积累一些常见的用法而后系统的学习,比如生成器装饰器、高级数据结构、各种工具库乃至 __init__.py 等细节。但 python 帮开发者自动进行了垃圾回收,所以一直没涉足这个领域,今天来了解一下 python 中垃圾回收的三种机制:引用计数、标记清除和分代回收。
引用计数
引用计数是 python 中默认使用的垃圾回收方法,思想也比较简单,每个对象有一个字段来记录对象被引用的次数,如果对象引用次数是 0,那么这个对象就会被回收并释放空间。优势是想法简单容易实现,能够处理对象创建、引用、传参、被存储至容器等引用计数增加的场景,以及 del 显式删除、对象别名被赋予新对象、离开作用域、容器被销毁等计数器减少的场景。
1 | import sys |
这里的引用次数为 4 是因为创建、函数调用堆栈帧、参数、sys 调用累积得到的,小缺点就是需要开辟额外的空间来维护这仿佛是废话,主要的缺点是不能处理循环引用问题。
1 | import sys |
上述的程序存在循环引用问题,如果去掉循环引用的部分,我们会发现每个循环创建对象的地址都是一样的,说明之前的对象经过 del 之后会被回收。而如果增加循环引用的语句,每个循环都会创建新的对象,也就是垃圾没有被回收。
标记清除
标记清除顾名思义,首先给所有的活动对象打上标记,然后清除没有被标记的非活动对象。所以问题转移为:如何判断对象是活动的?
python 中的对象通过引用连接在一起构成一个有向图,对象是图中的节点,引用关系就是有向边。从根对象出发,沿着有向边遍历对象,如果能到达这个节点,那么这个节点就是活动对象,否则就是非活动对象。如下图所示。
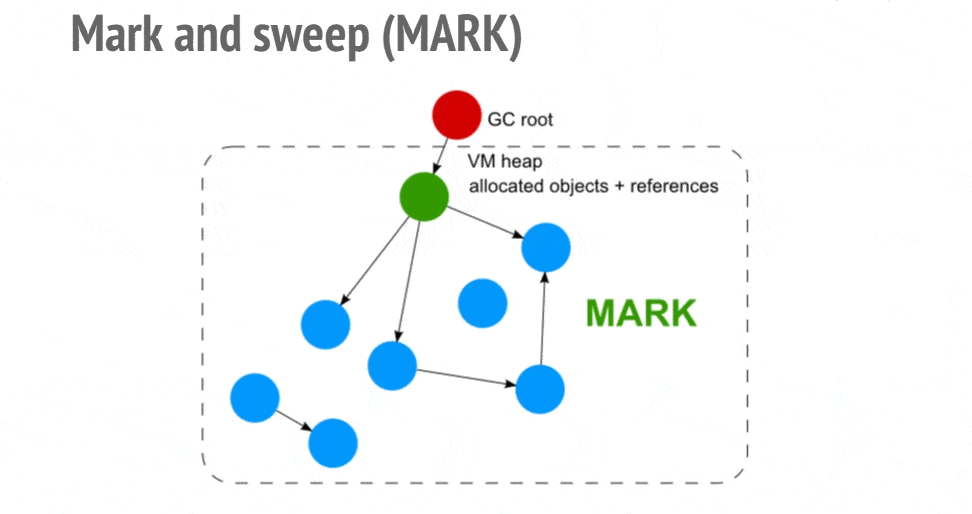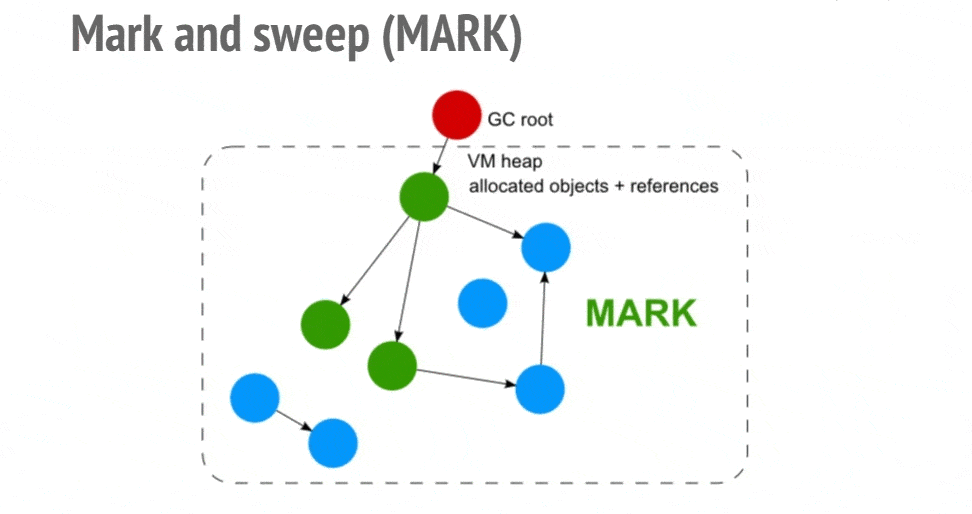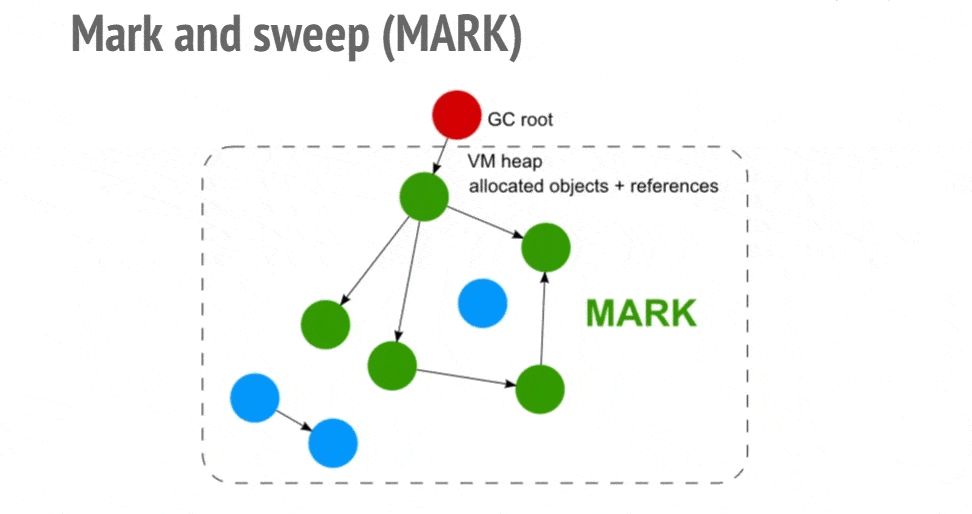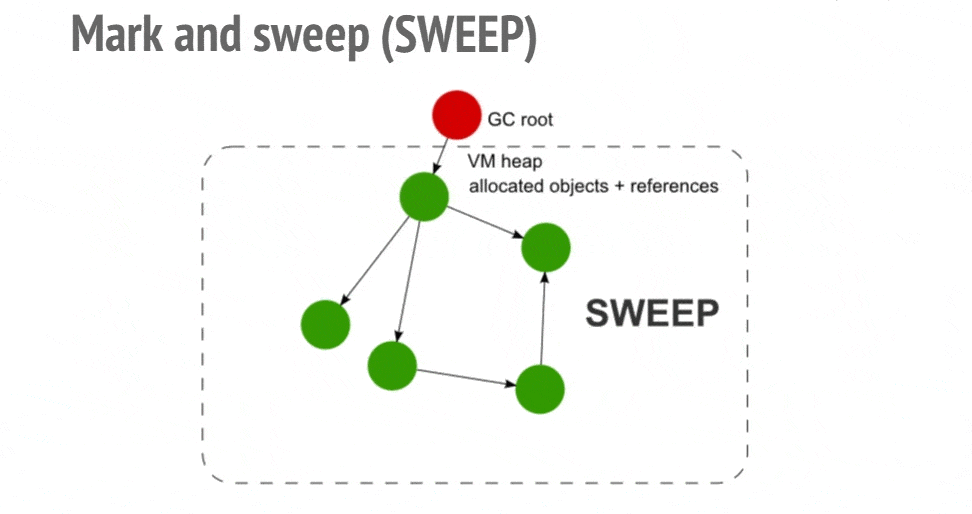
这个方法主要来解决前文提到的循环引用问题,也可以扩展到 list、dict 和 tuple 等容器对象,因为数值、字符串等字面常量不会被循环引用。
虽然能清除循环引用的对象,但是需要扫描整个堆内存,这可能只有一小部分非活动对象。而且当这个算法启动去清除垃圾时,程序会挂起运行,因为这两者显然不能同时执行。
标记清除与操作系统
标记清除容易导致内存碎片化。非活动对象可能位于内存的不同位置,当执行这个算法后,这些对象被释放,就导致了内存的不同位置空缺出现外碎片问题,但没有大单位的可用内存。而内存碎片化也是操作系统中的常见问题,导致内存利用率不高。
既然说到了内存碎片问题,就来回顾一下大三学过的操作系统,一般解决方法有连续分配方案和离散分配方案,对于连续分配方案:
- 固定分区,内存划分为固定大小的分区,会面临内碎片问题
- 动态分区,包括分区匹配和分区释放,分区匹配一般有最先匹配算法(找到合适分区立刻划分,不容易保留大分区)、最佳适应算法(找到大小最合适的分区,容易形成外碎片)和最差适应算法(避免外碎片,分配最大的分区,不容易保留大分区),分区释放阶段将两个空闲分区合并为一个空闲分区。
连续分配中内存碎片是不可避免的,为了解决这个问题,一般会进行紧缩:将小的内存碎片调整位置,组合成大的可用空间去装载新的进程。因为紧缩会移动内存改变进程的地址,因此这种带有额外开销的操作一般会在特定时期进行,如释放分区后或者新的进程不被满足时。
离散分配方案,允许进程所在的物理地址空间非连续:
- 页式管理,将一个进程的逻辑地址空间分成若干个大小相等的片,称为页面或页,并为各页加以编号,也把内存空间分成与页面相同大小的若干个存储块,称为页框,也同样为它们加以编号。在为进程分配内存时,以块为单位将进程中的若干个页分别装入到多个可以不相邻接的页框中。这种方式消减外部碎片,由于进程的最后一页经常装不满一块而形成了不可利用的碎片,称为页内碎片。虽然仍然有内碎片,但控制了内碎片的大小范围。优势是程序不必连续存放,所需的空间可以动态改变。但是程序需要一次性放入内存;几个子函数位于同一页面时,不利于程序和数据的共享和动态链接。
- 段式管理,为了解决共享数据和动态链接的问题,将程序的地址空间按内容或函数关系划分为若干段,每个段是逻辑上完整的程序或数据。将不同的段装入内存的不同位置,就可以支持逻辑共享了。所以通常段长不固定,决定于用户所编写的程序,所以这部分内存可以进行动态分区的管理。
- 段页式系统的基本原理是分段和分页原理的结合,即先将用户程序分成若干个段,再把每个段分成若干个页。
分代回收
python 根据对象的存活时间划分为三个的集合:年轻、中年和老年,新创建的对象位于年轻代,当年轻代的数量到达上限就会触发回收机制,不会被回收的对象会放在中年代中,依次类推,因此老年代是存活最久的对象。
清除过程是基于前文提到的标记清除算法实现的,这也是上文没写代码举例的原因,也能解释引用计数中,标记清除算法为什么没有清除循环引用的对象。
1 | import gc |
最后的输出为 4,表示被清除了。强行使用被删除对象的地址很危险,不建议这么写。
1 | This Obj Address: 1968923570128 |

