当时为了增长业余知识,在MOOC上听完了中国农业大学的计算机图形学这门课,后面几章的方程没有听,仅仅听到了三维变换。这是当时的电子版笔记,后来发现电子版笔记是真的累人,累倒有的笔记都不想放上来了。这是第一次,也是最后一次。
当然感觉这些东西还是挺有意思的,就准备放上来。如果你是华北理工大学的学生选了这门课,把这个网页里的内容看完85+也没问题了(缺少二维变换的例题,主要是太长了,真懒的写了。还有一些基础概念靠自己的悟性了)。
Chapter-01 计算机图形学概述
什么是计算机图形学
- 计算机图形:由计算机产生的图像。
- 计算机图形学是研究如何利用计算机显示、生成和处理图形的原理、方法和技术的一门学科。
- 是真实世界或者虚拟世界的数字模拟。
计算机图形学的研究内容
- 包括计算机图形学中定义的内容;
- 图形硬件,显示器,图形加速卡,图形输出设备(不重要)
- 基本图形元素的生成算法
- 图形的变换和裁剪
- 自由曲线、曲面的生成算法
- 几何造型技术
- 真实感图形的生成算法
- 计算机动画、虚拟现实、交互式三维图形处理
计算机生成物体的三个步骤:
- 几何造型:规则物体应该建立生成图像的物理模型,即对应的几何数据和拓扑关系;非规则的工具表示不规则物体;几何造型技术:用简单的体素(圆柱、圆锥等)构建复杂的模型。
- 光照模型:表示颜色,表示光源;使用简单的数学模型表示、近似为实际中的物理学中的光学模型。
- 绘制(渲染)技术:选择恰当的算法渲染将场景渲染出来,将模型真实的显示在屏幕上。
计算机屏幕由像素构成,像素是构成图形的基本单位。为了显示图形,需要研究哪些像素显示图形,显示哪些颜色,也就有了光栅显示器(70年代)中的一套算法。
计算机图形学的应用领域
- 人机交互GUI(Windows, Icon, Mouse, Pointer)
- 计算机辅助制造(CAD, 电路设计)
- 真实感图形绘制(计算机重现自然界真实场景)与自然景物仿真
- 计算机游戏、动画、电影
- 计算机艺术:钢笔画、油画
- 计算机仿真:二维、三维结果的表示
- 科学计算与可视化
- 虚拟现实
- 地理信息系统(geographic information system),如三维地图重建
- 农业种植模拟
计算机图形系统的组成
输入、输出、计算、交互、存储是五个最基本的功能。
图形系统由图形软件和图形硬件组成。
- 图形软件:
- 图形应用数据结构: 对应图形的数据文件,存放欲生成的图形的全部描述信息。
- 图形应用软件:核心部分,解决某个问题的软件,包含图形生成处理等个重技术,如Photoshop。
- 图形支撑软件:是图形应用软件的底层,有规范的接口。
- 图形硬件:包括图形计算机平台和图形设备(如显示器)。
实现图形软件的放歌方法:用子程序写包(如OpenGL),扩充计算机语言,设计专用的图形系统。
交互式计算机图形处理系统
图形系统中重要的为:图形处理器、图形输入、输出设备。
- 图形输入设备:穿孔纸$\rightarrow$键盘,光笔$\rightarrow$鼠标,触摸屏$\rightarrow$三维输入设备$\rightarrow$智能人机接口:用户语音、手势等。
- 图形输出设备:图形的输出包括图形的显示和绘制,显示是指在屏幕上输出图形,图形的绘制是指将图形画在纸上,如打印机。
- CRT显示器:阴极射线管,加热电子轰击荧光屏,荧光屏有三种颜色。
- LCD液晶显示器:液晶粒子每一面的颜色为红绿蓝,按照收到的数据控制每个粒子转向对应的面,以此来显示颜色。(用于电脑显示)
- LED显示器:发光二极管。(光源器件用于照明,如广告牌)
- 等离子显示器:厚度薄,分辨率好。显示屏排列小低压气体室,电流激发紫外光,紫外光撞击三原色的屏幕,发出可见光。
- 3D显示器:不用戴眼镜即可看到,用的时差栅栏技术。
帧缓冲器与屏幕像素
帧缓冲器每一点可以存储颜色、强度信息,在计算机上画图形,需要计算每个像素的RGB值,因此帧缓存写RGB等价于屏幕画图像。帧缓冲器的单元个数和像素总数相同,存储单元一一对应可寻址的屏幕像素位置。
- 分辨率:一行有几个点,一共多少行。
- 屏幕分辨率:屏幕上显示的像素的个数。
- 显示分辨率:对于文本的显示方式,水平和垂直方向上能显示的字符总数的乘积表示;对于图形显示方式,水平和垂直能显示的像素点数的乘积表示。
- 显卡分辨率:显卡输出给显示器,并能在显示器上扫描的像素点的数量。电脑的最高分辨率取决于显卡和显示器的最低分辨率。
- 帧缓冲器的存储单元的位长决定了一副画面能显示的颜色的种类。(256色需要8bit, $2^8=256$)
- 显存的大小:2MB显存,分辨率$1204\times 768$,每个帧缓冲器的存储单元的位长:$x = 2\times 1204\times 1024 \div 1024 \div 768$,则$2\leq x \leq 3$,最多需要两个字节表示,故支持64K色彩数。
显示器的点距
相邻像素点的距离,距离越小越好。028mm足够,小于则更好。
显卡的作用与性能指标
基本作用是显示图文,显示卡与显示器构成了计算机的显示系统。除了CPU与内存外,显卡对计算机的显示性能起了决定性作用。(也可以处理数据)
图形与图像的区别
- 图形:计算机绘制,矢量图。
- 图像:认为用外部设备拍摄捕捉,点阵图。
图形图像的构成属性
- 几何属性:几何要素,轮廓,形状,点线面。(如圆心、半径)
- 非几何属性:视觉属性,颜色,材质,明暗,透明度,纹理。
图形分类
- 几何属性很重要:基于线条信息表示,如等高图、工程图。
- 非几何属性很重要:明暗图,通常的真实感图形。
矢量图与位图的区分
两者可以相互转换,矢量扫描转换到点阵,点阵图像处理到矢量。
- 概念区分:
- 位图:点阵图,图由屏幕上的像素构成,每个点用二进制表述颜色与明暗。
- 矢量图:数学描述曲线及曲线围成的色块制作的图形。矢量图中的图形元素也成为对象。每个对象自成一个实体,具有颜色、形状、大小和位置等属性。
- 存储方式的区别:
- 点阵文件存储每个像素点的位置、颜色和灰度信息(存储空间大)
- 矢量文件用数学方程对图形进行描述,用图形的形状参数和属性参数表示图形
- 缩放的区别:
- 位图与分辨率有关,在一定面积上含有固定数量的元素,所以放大后失真
- 不会影响清晰度,无失真的放大缩小。
- 存储格式的区别:
- 位图:png, bmp, gif, jpeg
- 矢量图:eps, svg(scalable vector graphics), DXF(data exchange file), WMF, EMF.
位图更容易模仿真实感图形效果,矢量图不失真,用于文字设计、标志设计、插图等。
Chapter-02 光栅图形学算法
出现了光栅显示器,为了在计算机上处理和显示图形,需要一套算法。属于计算机图形的底层算法,设计了计算机图形学的基本概念和思想。
直线段的扫描转换算法(1)
直线无限,而像素有限,所以要用有限的像素逼近无限的直线,所以可能存在锯齿情况,不够理想。
问题:求每个像素点的$x, y$坐标。
求解:
过$P_0(x_0, y_0), P_1(x_1, y_1)$的直线$y=kx+b$ 得到 $k=\frac{y_1-y_0}{x_1-x_0}(x_1\neq x_0)$
假设$x$已知,从$x$的起点$x_0$开始,沿$x$前进一个像素,则步长为1。
计算相应的$y$值,因为像素坐标是整数,$y$需要+0.5,向下取整。
真实感图形往往调用成千上万次的画线程序,因此这个算法影响了图形的质量和显示速度。在函数$y=kx+b$中,存在$kx$的乘法运算,而计算机最快的运算是加法,所以接下来要取消乘法的运算。
直线段的扫描转换算法(2)
一共有三个比较出名的算法
- 数值微分法(DDA)
- 中点画线法
- Bresenham算法
DDA算法
重要的思想为增量思想。设单位步长为一个像素。
即:$y_{i+1}=y_i+k$,$k$是增量。$y_i$加$k$得到$y_{i+1}$,取消了乘法。当$|k|\leq 1$时,一切正常。参考下列例题。
例题
DDA算法扫描转换连接两点$P_0(0, 0)$,$P_1(5, 3)$的直线段。
$k=\frac{3-0}{5-0}=0.6$
| $x$ | $y$ | int($y$+0.5) |
|---|---|---|
0 | 0 | 0
1 | 0.6 | 1
2 | 0.6+0.6 | 1
3 | 1.2 + 0.6 | 2
4 | 1.8 + 0.6 | 2
5 | 2.4 + 0.6 | 3
思考
在DDA算法的$|k|>1$时,如$(0, 0)$到$(2, 100)$画点,光栅点会很系数,点很少,没有办法表达直线(只是每个点亮)。此时不能$x+1$作为基本单位。
$y_{i+1}=y_i+k$,一般情况下,$y$和$k$都是小数,而且每一步都需要取整,唯一的改进方法是,将浮点数计算改为整数计算。
如果换一种直线方程的表达形式,是否可以改进效率。
中点画线法
直线的一般式:$F(x, y)=0$ 即 $Ax + By + C = 0$。
- 直线上的点:$F(x, y) = 0$
- 直线上方的点:$F(x, y) > 0$
- 直线下方的点:$F(x, y) < 0$
每次在最大位移方向走一步,另一个方向是否移动取决于中点误差项的判断。
对于$0\leq|k|\leq 1$,$x$在方向上加1, $y$方向是否加1需要判断。如下图所示:
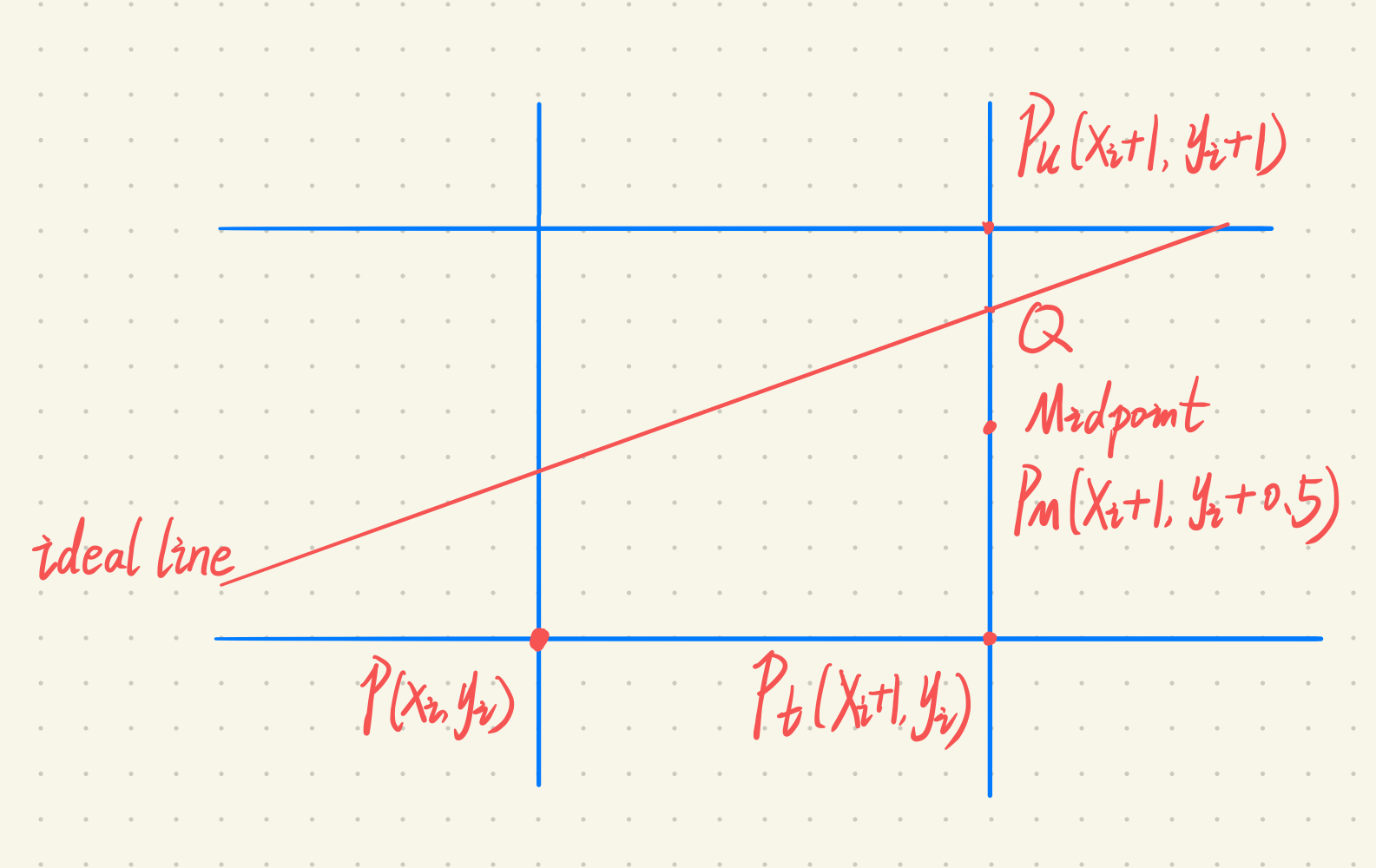
- 交点$Q$在Midpoint上方时,$Q$距离$P_u$近;
- 交点$Q$在Midpoint下方时,$Q$距离$P_t$近;
将$M$带入理想的只想方程,$F(x_m, y_m) = Ax_m + By_m + C$,记为距离$d$。
- 当$d < 0$时,$M$在$Q$下方,选择$P_u$
- 当$d > 0$时,$M$在$Q$上方,选择$P_t$
- 当$d = 0$时, 选择$P_t$或者$P_u$都可以
得到:
上面的公式两个乘法,四个加法,所以要提升效率。
- 在$d<0$时
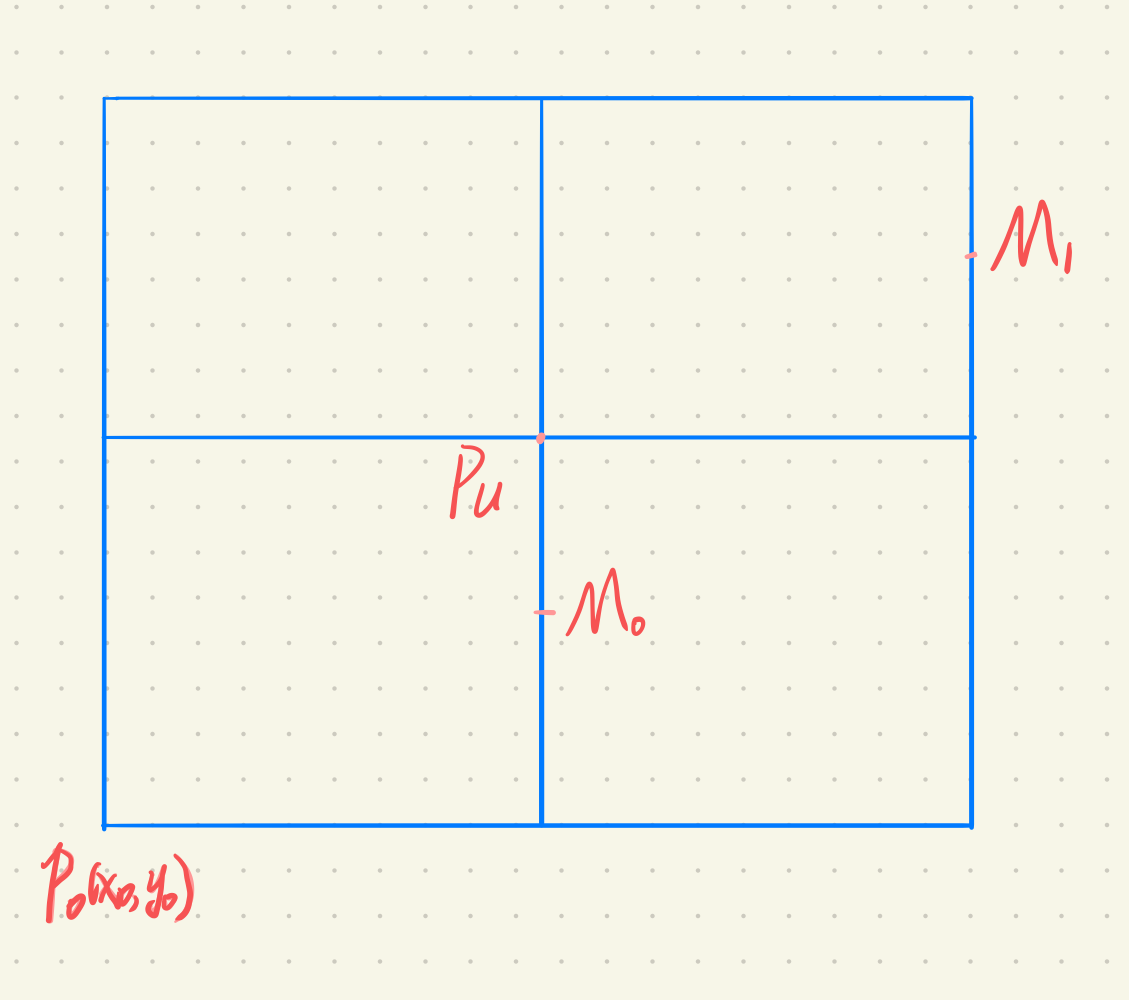
- 在点$M_0$处,$d_0=F(x_{m0}, y_{m0})=A(x_i+1)+B(y_i+0.5)+C$
- 在点$M_1$处,$d_1=A(x_i+2) + B(y_i+1.5) + C=d_0+A+B$
- 在$d\geq 0$时
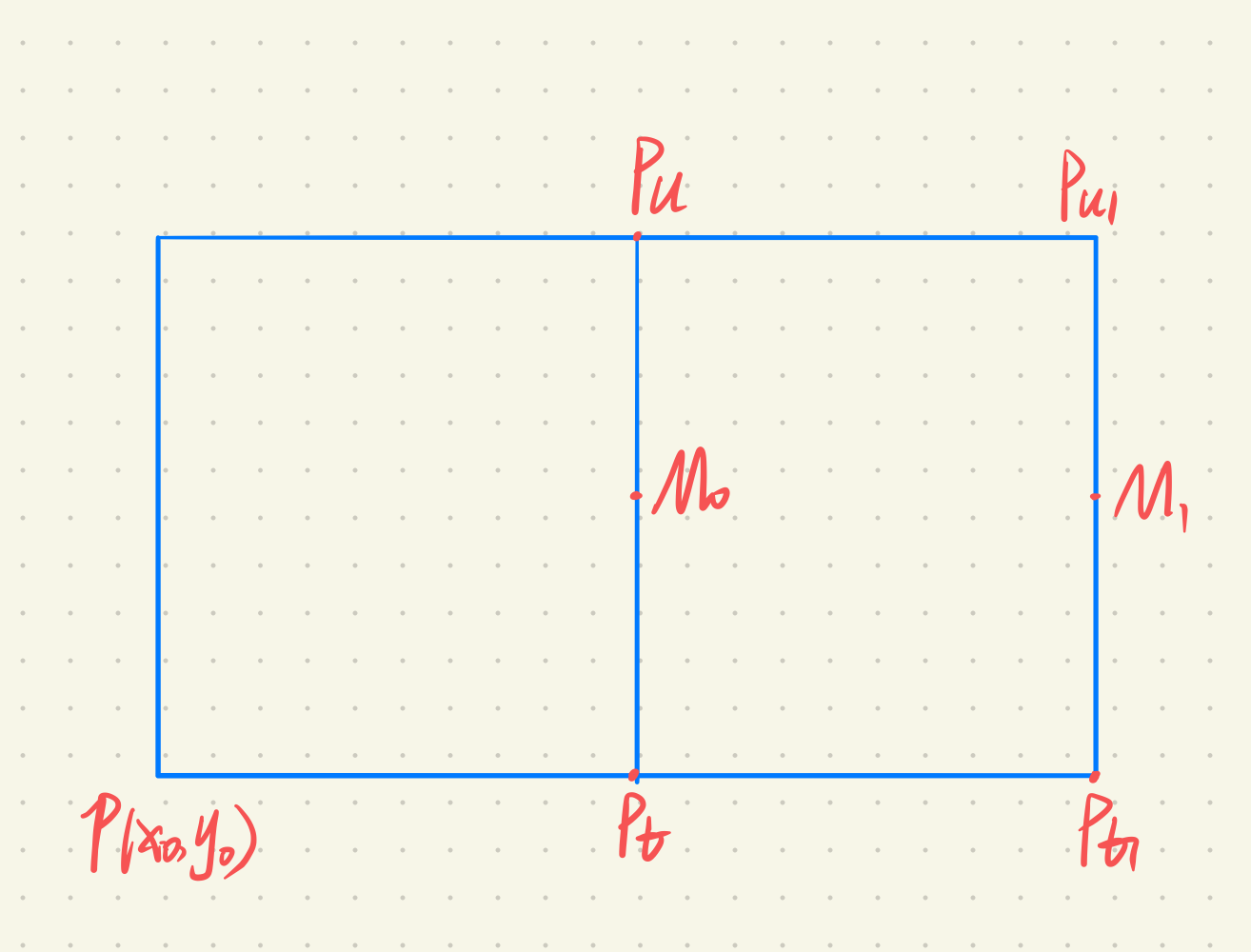
- 在点$M_0$处,$d_0=F(x_{m0}, y_{m0})=A(x_i+1)+B(y_i+0.5)+C$
- 在点$M_1$处,$d_1=A(x_i+2) + B(y_i+0.5) + C=d_0+A$
于是得到$d$的递推公式:
但是在$d_0$中有小数,且只判断$d$的符号,所以可以使用$2d$代替$d$,即$d_0=2A+B$,摆脱浮点运算,提高到整数加法,优于DDA算法。
Bresenham算法
效率没办法提升,所以算法要解决其它问题,如是否可以画圆,不限于直线的方程形式。
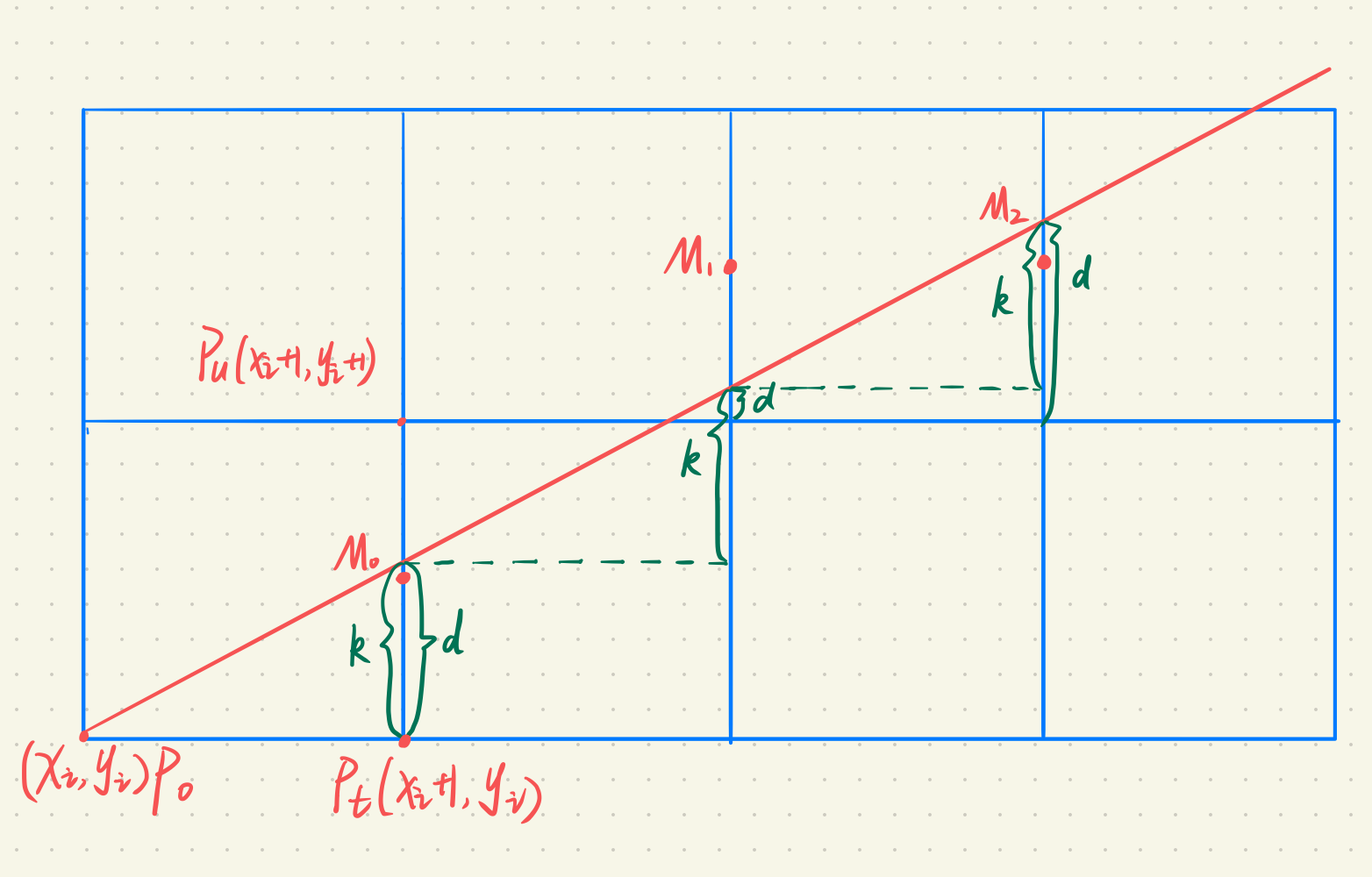
此时不再依赖直线的方程形式,更加一般化。
计算直线的起点到终点与垂直网格线的交点,根据误差项判断与交点最近的像素点。
每次$x+1$,$y$的增量为0或者1, 取决于最近光栅网格点的距离。最开始是,$d_0=0$,递增公式为$d=d+k$。一旦$d>1$,则$d=d-1$,使得$d$在$[0, 1]$区间内。所以:
但是需要将浮点计算提升到整数运算。
Step1: $e=d-0.5$
Step2: $e_0=-0.5$,$e=e+k$,$e>0.5$时,$e=e-1$。
Step3:$e_0=-0.5$,$k=\frac{dy}{dx}$。用$2e\Delta x$代替$e$(计算过程为两边同时乘以$2\Delta x$,并将$2e\Delta x$写为$e$),于是
最终的算法步骤:
- 输入起点$P(x_0, y_0)$和终点$P_n(x_n, m_n)$
- 计算初始值$e_0$
- 绘制点$(x_0,y_0)$
- $e$更新为$e+2\Delta y$。若$e>0.5$,更新$e$为$e - 2\Delta x$,$(x_i,y_i)$更新为$(x_i+1,y_i+1)$;否则$e$不更新,坐标更新为$(x_i+1,y_i)$。
- 如果没有画完,持续三四步骤,如果画完了就结束。
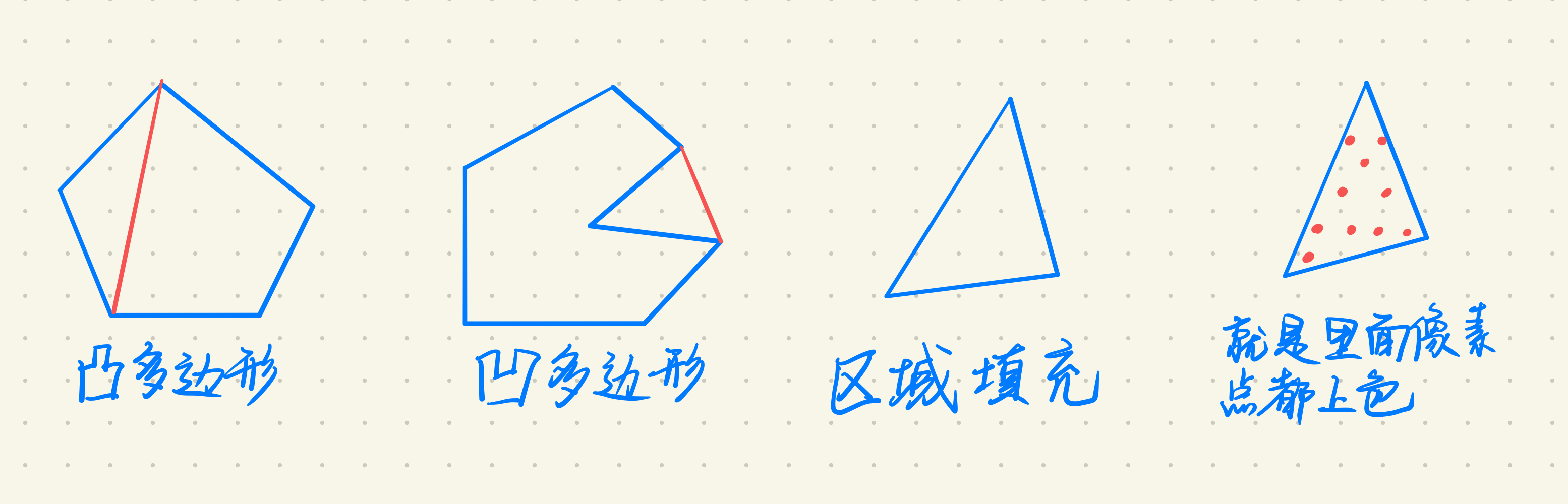
多边形的扫描转换与区域填充
实际上为离散的像素点到连续的二维图形之间的转换。
多边形的两种表现形式:
- 顶点表示:描述为顶点的序列,侧重几何意义,没有指明哪些点在多边形的内部。
- 点阵表示:多边形内部的像素点集合,丢失了边界信息和顶点信息,常用于光栅显示器的显示。
进一步,导出两个问题:
- 知道边界,就知道了哪些像素在多边形内,就可以转换为点阵表示,也叫多边形的扫描转换。即将顶点表示转换为点阵表示,寻找内部的像素点并填充颜色。
- 知道多边形内部的像素,但不可以确定多边形的边界。(属于图像处理课程的东西)
X扫描线算法
以数值扫描为例,按照扫描的顺序,求与多边形相交的区间,对区间内部的像素点进行颜色填充。同样,坐标点需要四舍五入为整数。
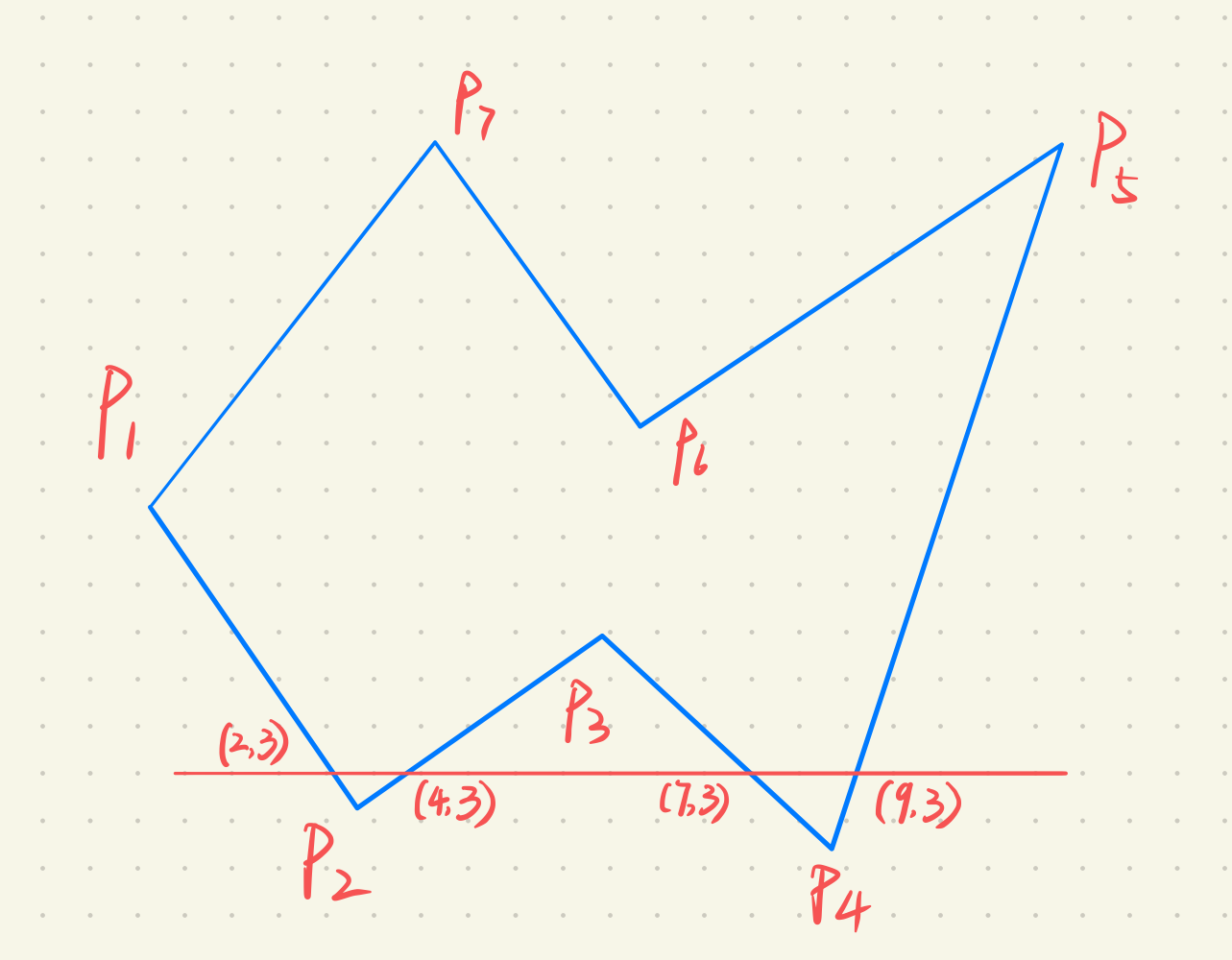
需要以$x$递增的排列顺序得到$x$的坐标,也就是要在$[2,4],[7,9]$两个区间内填充。
如果图形中,$y_{\mathrm{min}}$值为$1$,$y_{\mathrm{max}}$值为$12$,一共需要$12$条扫描线从下向上扫描,其他线不考虑。在$y\in [y_{\mathrm{min}},y_{\mathrm{max}}]$中,对每一条扫面线的扫描结果进行填充,步骤为:
- 求交点
- 升序对$x$的坐标进行排序
- 保证交点为偶数个,配对
- 填充
为了保证交点为偶数个,需要对交点的取舍问题进行解决。
- 共享顶点的两条边在扫描线的两侧,算一个交点
- 共享顶点的两条边在扫面线的一侧,需要检查共享顶点的另外两个端点的$y$值,按照大于$y$值的个数决定交点的个数。
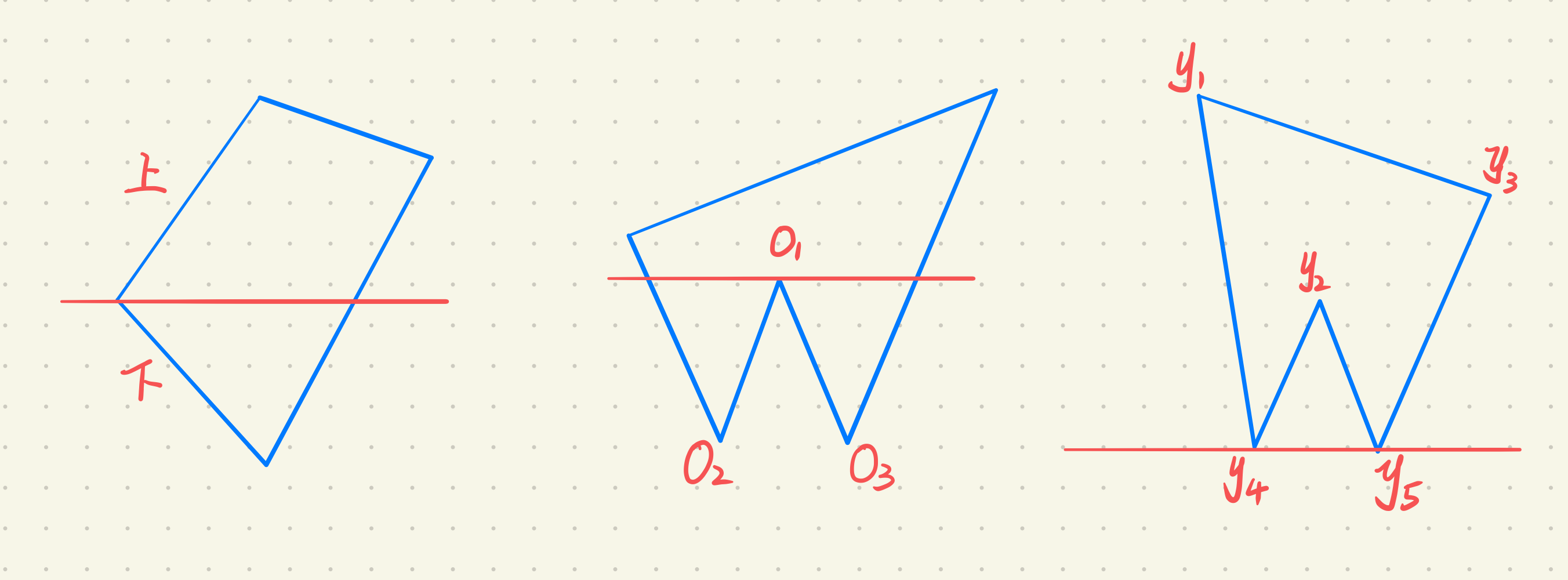
如上图所示
- 左图:共享顶点的两条边在扫描线的两侧,算一个交点
- 中间图:$O_2 < O_1, O_3 < O_1$,零个交点
- 右图:$y_1>y_4,y_3>y_5$,共四个交点,每个交点有两个
例题:
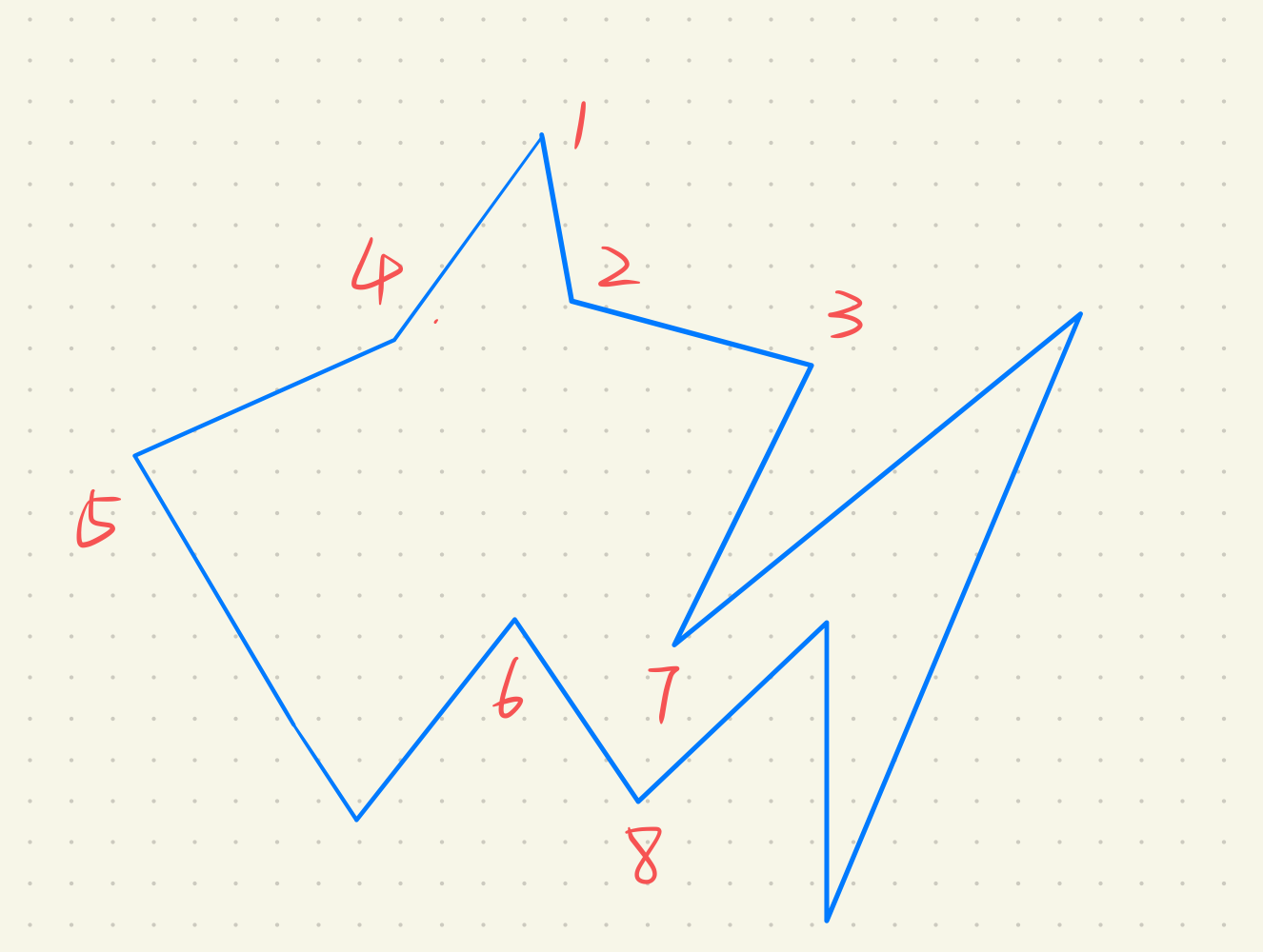
| 编号 | 个数 | 编号 | 个数 | 编号 | 个数 | 编号 | 个数 |
|---|---|---|---|---|---|---|---|
1 | 0 | 2 | 1 | 3 | 1 | 4 | 1
5 | 1 | 6 | 0 | 7 | 2 | 8 | 2
同理可知,最右下脚的交点个数为2。但是,每次都需要求交点,暴力循环会导致计算量过大,应该采取某种方法避免求交。
改进的多边形扫面转换算法
解决每次的扫面线和边求交点的问题。
- 有效边饥溺羞赧感相交运算,而暂时用不到的边则不计算
- 当前扫描线与下条扫描线与当前边或下一条边的交点顺序可能相似,即扫描线的连贯性
- 多边形的连贯线,某边与扫描线相交,还可能与下条扫描线继续相交
如$P_1,P_2,P_3$三条扫描线连贯性,多边形的边也有连贯性。
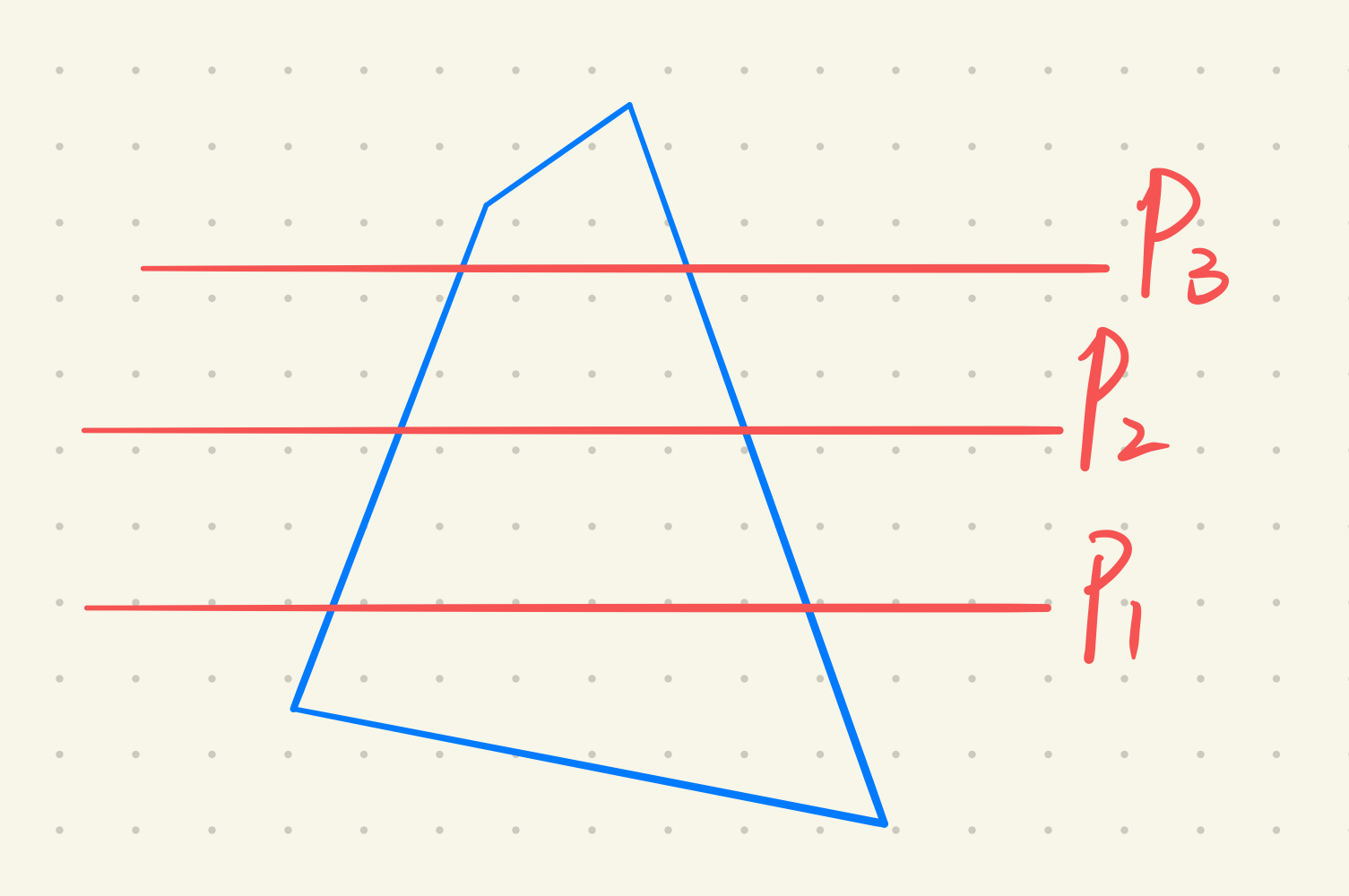
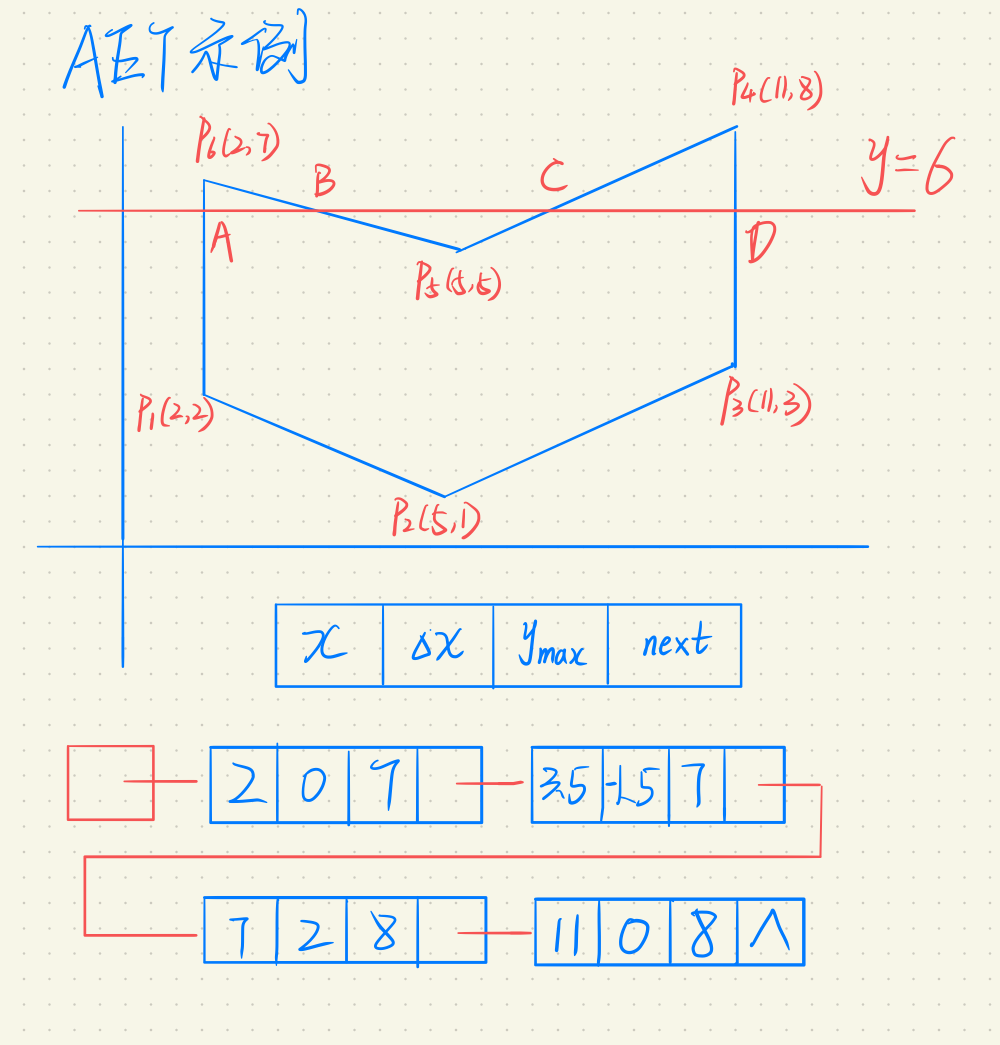
此时需要引入特殊的数据结构,活性边表AET(Active Edge Table),活性边是指与扫描线相交的边,同样以$x$递增的顺序放入一个表内。这个表的节点内容为:
| $x$ | $\Delta x$ | $y_{\mathrm{max}}$ | $\mathrm{next}$ |
|---|---|---|---|
- $x$是当前交点的值
- $\Delta x$是$x$的增量,用于计算下一个$x$。扫面线移动,和多边形的交点与上一个交点是有关的。
- $y_{\mathrm{max}}$表示当前活性边的最高点,即扫描线何时此笔边相交,及时删除。
- next指向下一条边
$\Delta x$的计算过程:
得到:
例题
为了方便存放多边形的边,AET的建立与更新,需要建立新边表NET(New Edge Table)。是一种纵向链表,长度为最大扫描线的数量,每个节点是一个吊桶,对应一条扫描线,节点的结构为:
| $y_{\mathrm{max}}$ | $x_{\mathrm{min}}$ | $\frac{1}{k}$ | $\mathrm{next}$ |
|---|---|---|---|
例题
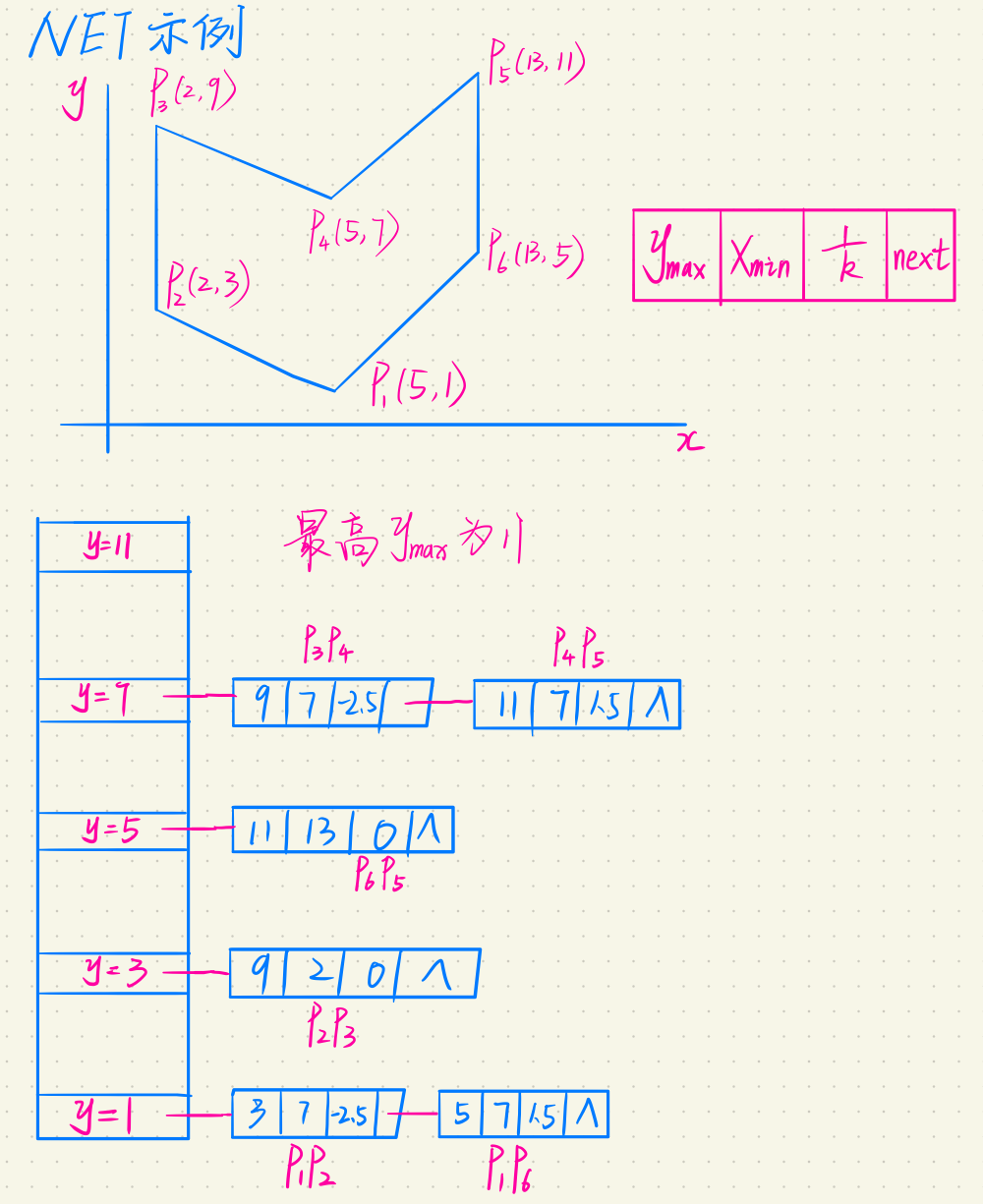
$1,3,5,7$处需要更新,读入新的边,所以存入NET表,从最低点的$y=1$开始做,引入两条边放入AET处理。
总结
每次扫描线要经过三个处理
- 判断是否需要取出(读$y_{\mathrm{max}}$即可)
- 不取出的话以$x=x+\frac{1}{k}$对$x$更新
- 判断有无新边的进入,新边在NET中,插入排序插入即可。(读$y_{\mathrm{max}}$和next判断)
1 | # Python code for algorithm flow |
这样就可以完成对任意多边形的填充,利用了扫描线增量的思想,多边形的连贯性和一种新的数据结构。但是要求待填充区域必须已知,无法对位置边界的区域进行填充。
此外还有其他多种算法可以完成对多边形的填充,如边缘填充算法,随机则一条边和边的遍历顺序,对每条边的右侧像素取补运算,即可完成对多边形区域额填充。
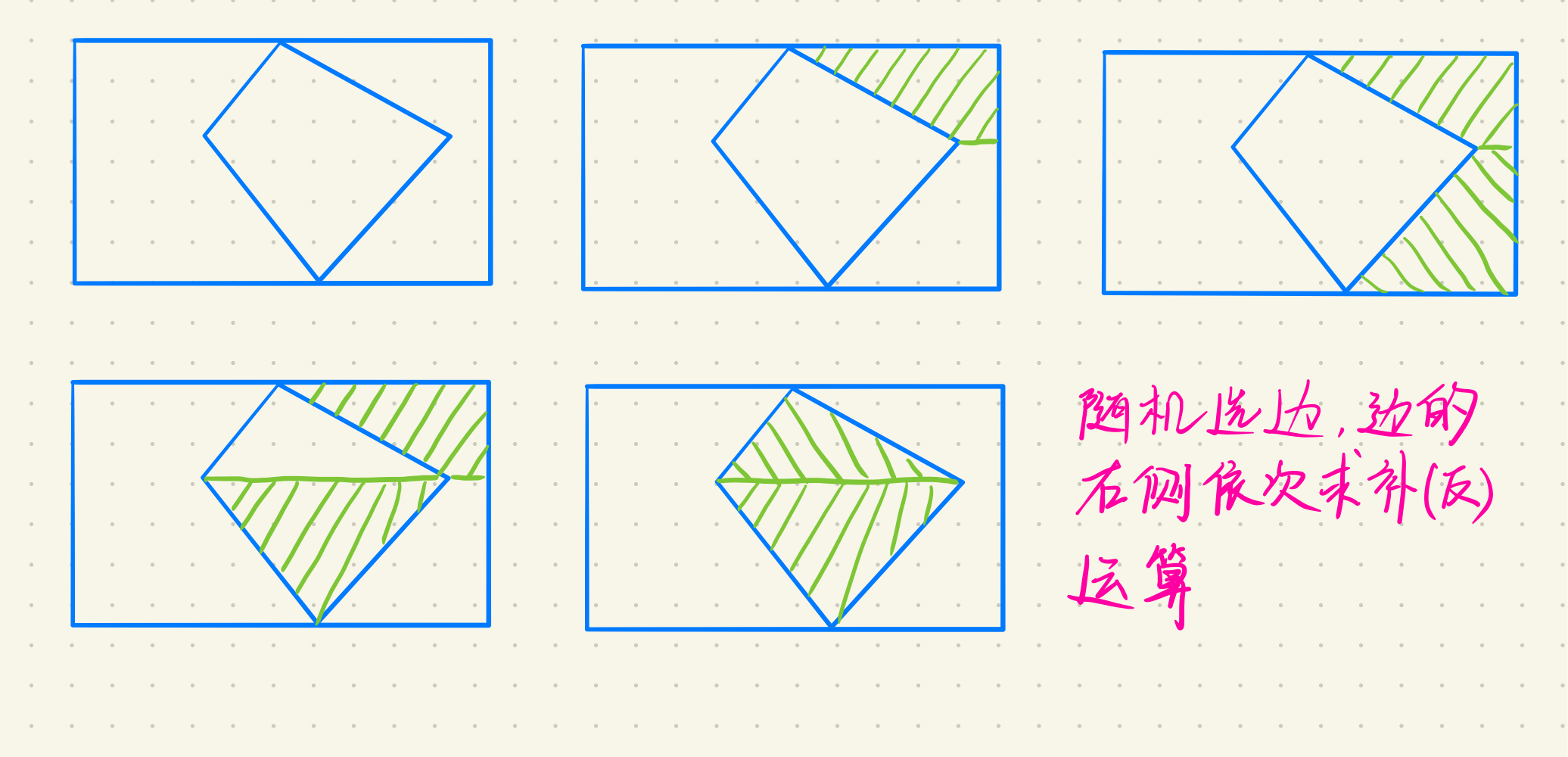
区域填充算法
将区域内的某个点赋予颜色(种子点),并将此颜色扩展到整个区域,其中的区域是指:已经点阵表示的填充图形的像素的集合。
区域表示的两种方法:
- 内点表示:枚举所有像素,着同一颜色
- 边界表示:枚举边界的所有像素,内部点着同一颜色
这个算法要求区域是连通的,进行四向连通和八向连通。
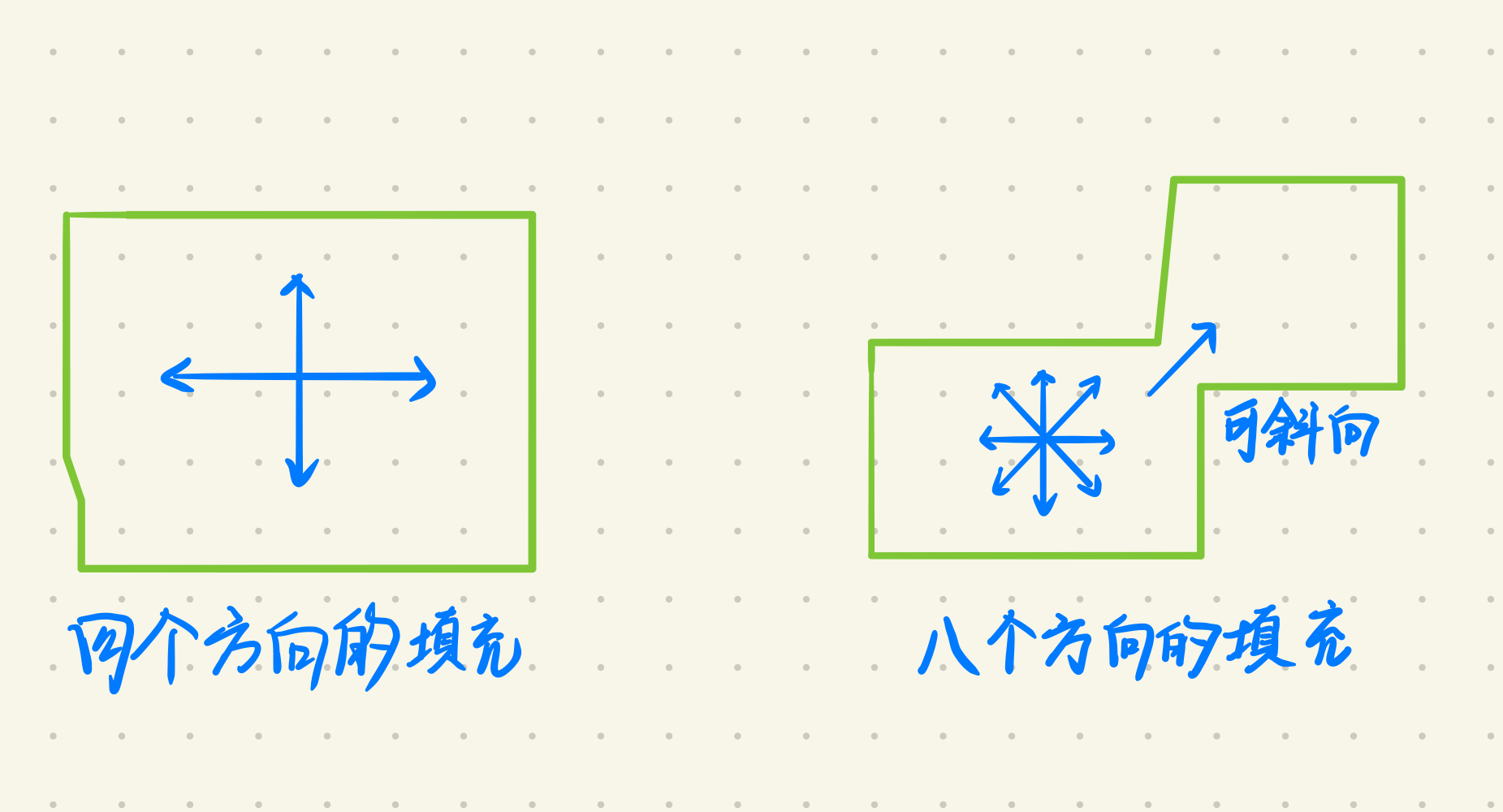
以四连通填充为例,边界的像素与内部的像素颜色不同,找到内部的种子像素,并填充到内部的其他像素。使用栈结构实现(和栈结构的米够求解问题类似)
算法伪代码如下:
1 | push seed |
可以脑补栈结构的迷宫求解问题理解上述代码。有些像素需要入栈多次,浪费时间,多次循环浪费时间,效率低下。
总结
扫描线算法与区域填充算法的对比:
- 扫描算法只将顶点转换为点阵表示,从顶点出发,利用连贯性填充和全新的数据结构。
- 区域填充没有改变区域的表示方法,依赖连通性,需要知道多边形边界与内部的像素差异,要求的条件更多。
反走样算法
走样是理想世界数字化的必然产物,发生走样的原因是像素本身是离散的,可能会导致锯齿状、微小物体丢失的现象。
走样可以总结为:原始信号变化快,采样频率低而导致,最终的结果会取决于低频的采样信号(低频的采样信号可以理解为很少的像素点,分辨率低,分辨率高则采样频率也会高)
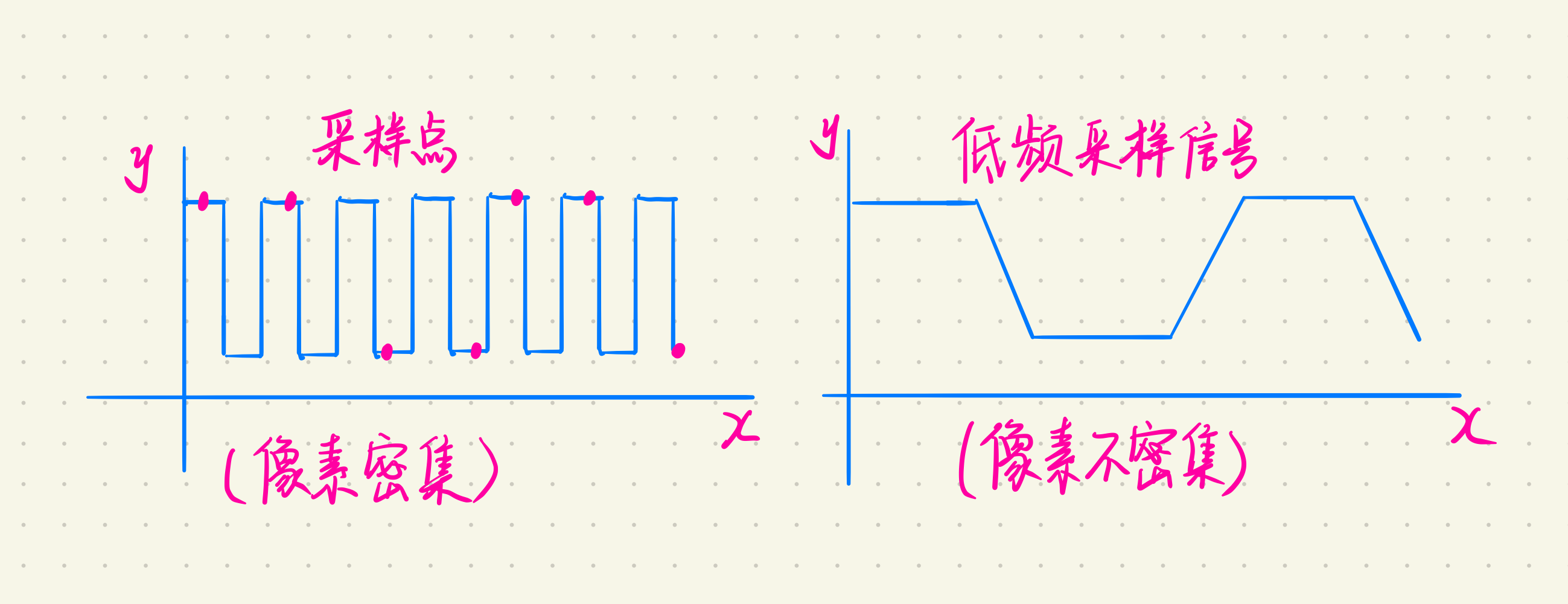
反走样:减少或消除走样的效果。所有的图像处理系统都会对基本图形进行反走样处理。
- 提高分辨率:像素更密集,但是付出的存储代价和扫描转换时间都要提升,还要提高电子枪的射击速度,并不可取。
- 以一种模糊的形式去平滑,如白纸黑字下,黑子旁边增加灰色像素柔滑尖锐的效果。
两种反走样算法
非加权采样方法
以物体的覆盖率计算像素的颜色,即某个像素区域被物体覆盖的比例,覆盖率越大,颜色越亮。
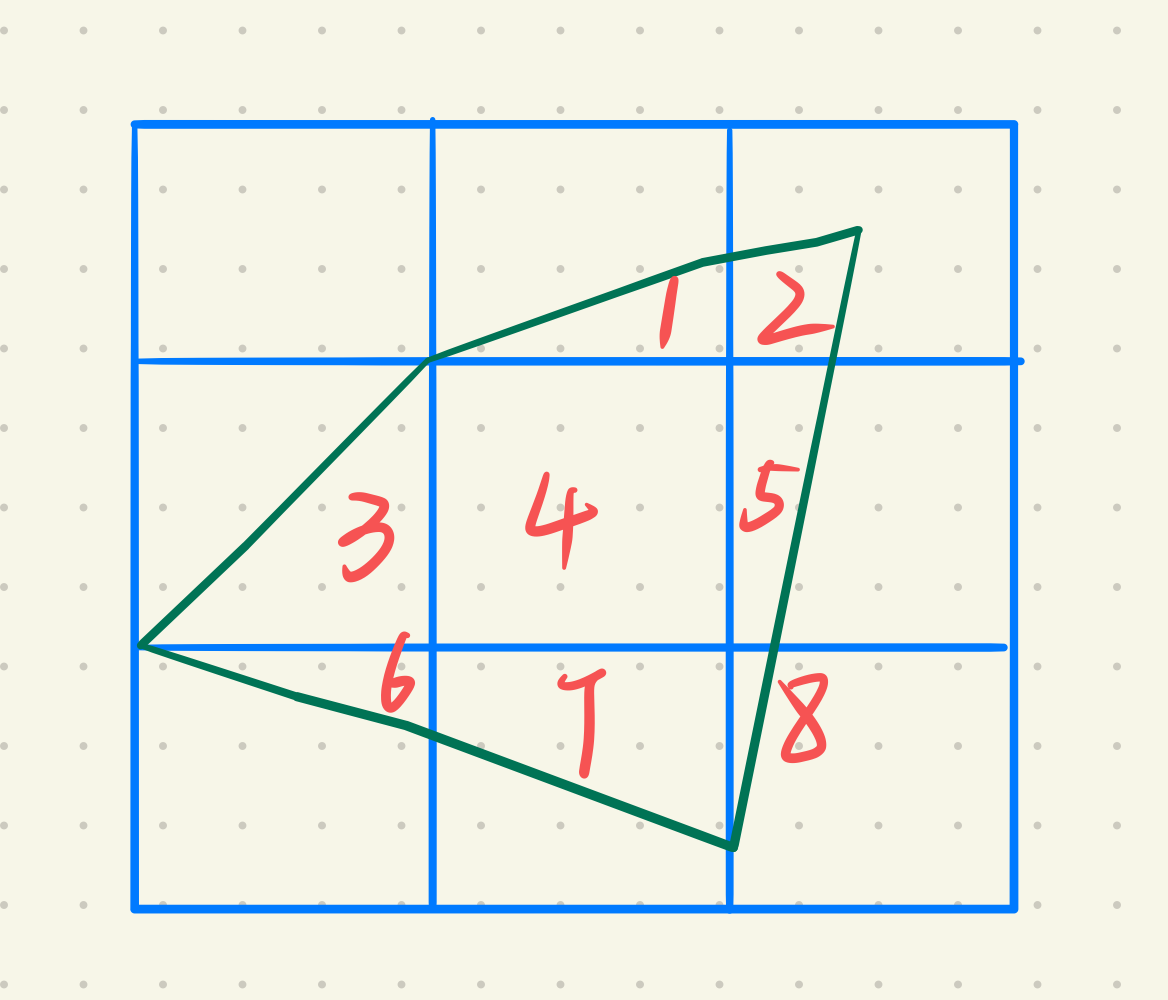
如上图所示的第$3$号区域,覆盖了一个像素的一般的区域,所以颜色取原来的二分之一。如果为小数则进行四舍五入的取整。
缺点
- 与相交的区域成正比,与区域块的位置无关,仍然可能会存在锯齿的现象,因为没有良好的区分边界位置与中心位置。
- 相邻的像素点会有较大的灰度差,因为每个像素的权重一样,亮度完全取决于覆盖面积。
加权采样方法
亮度取决于距离像素中心的远近,区域与像素中心的距离决定了对像素亮度的贡献。将一个像素分为$3\times 3$的矩阵,矩阵的每个值被赋予权重,乘以颜色求平均,得到最后的亮度值。(和图像处理中的高斯模糊过程一致)
裁剪算法
内部存储的比实际显示的要大,所以要对不分区域进行裁剪,确定哪些像素落在显示区域内。(基于点阵的判断)
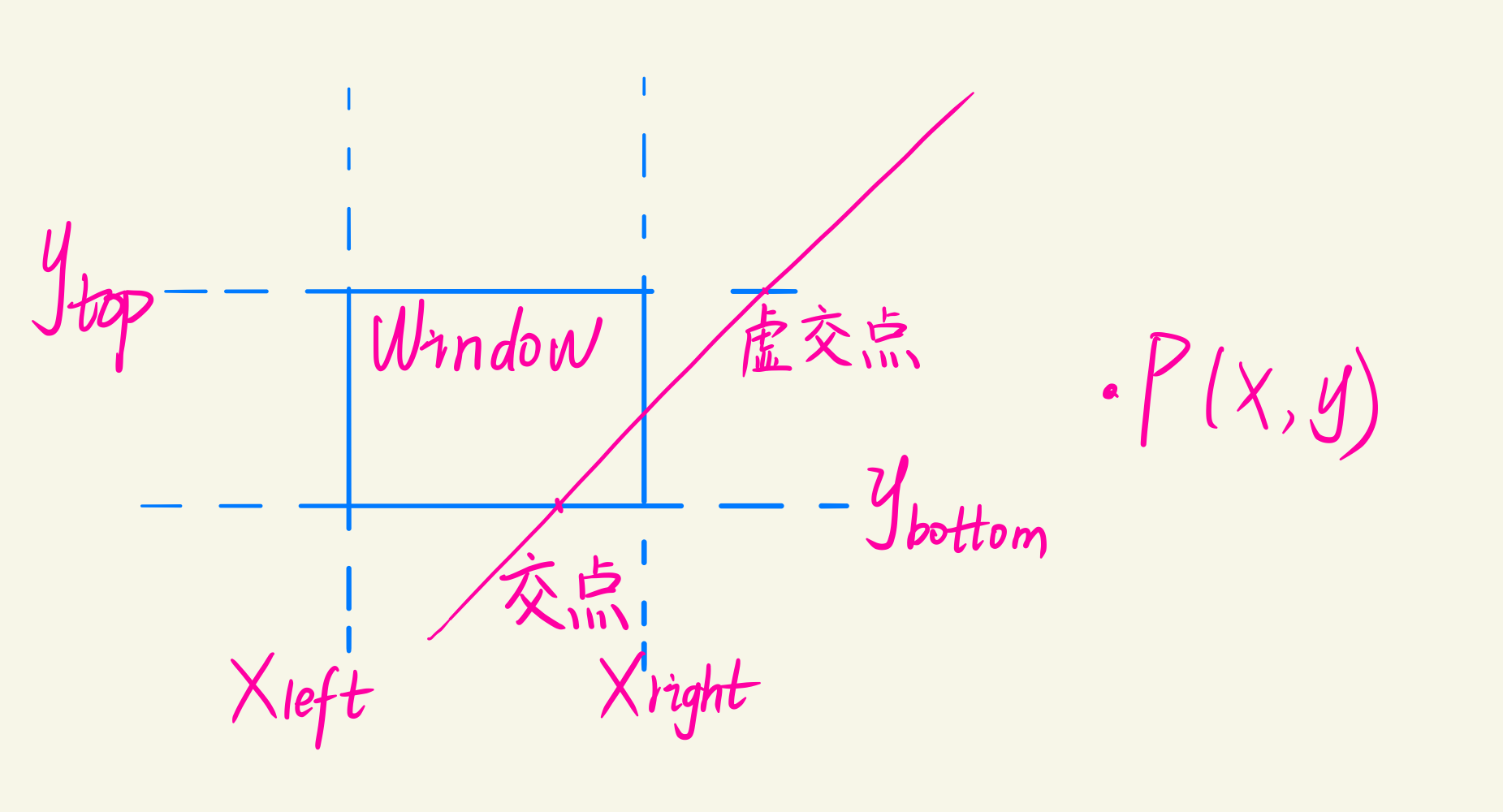
判断一个点$P(x,y)$是否在区域内部的方法:
而直线段的裁剪,是复杂图形裁剪的基础,分为以下三种情况。
- 完全在window内
- 完全在window外
- 与window的边界相交
有常用的三种算法
- Cohen-Sutherland算法
- 中点分割算法
- Liang-Barsky算法
Cohen-Sutherland
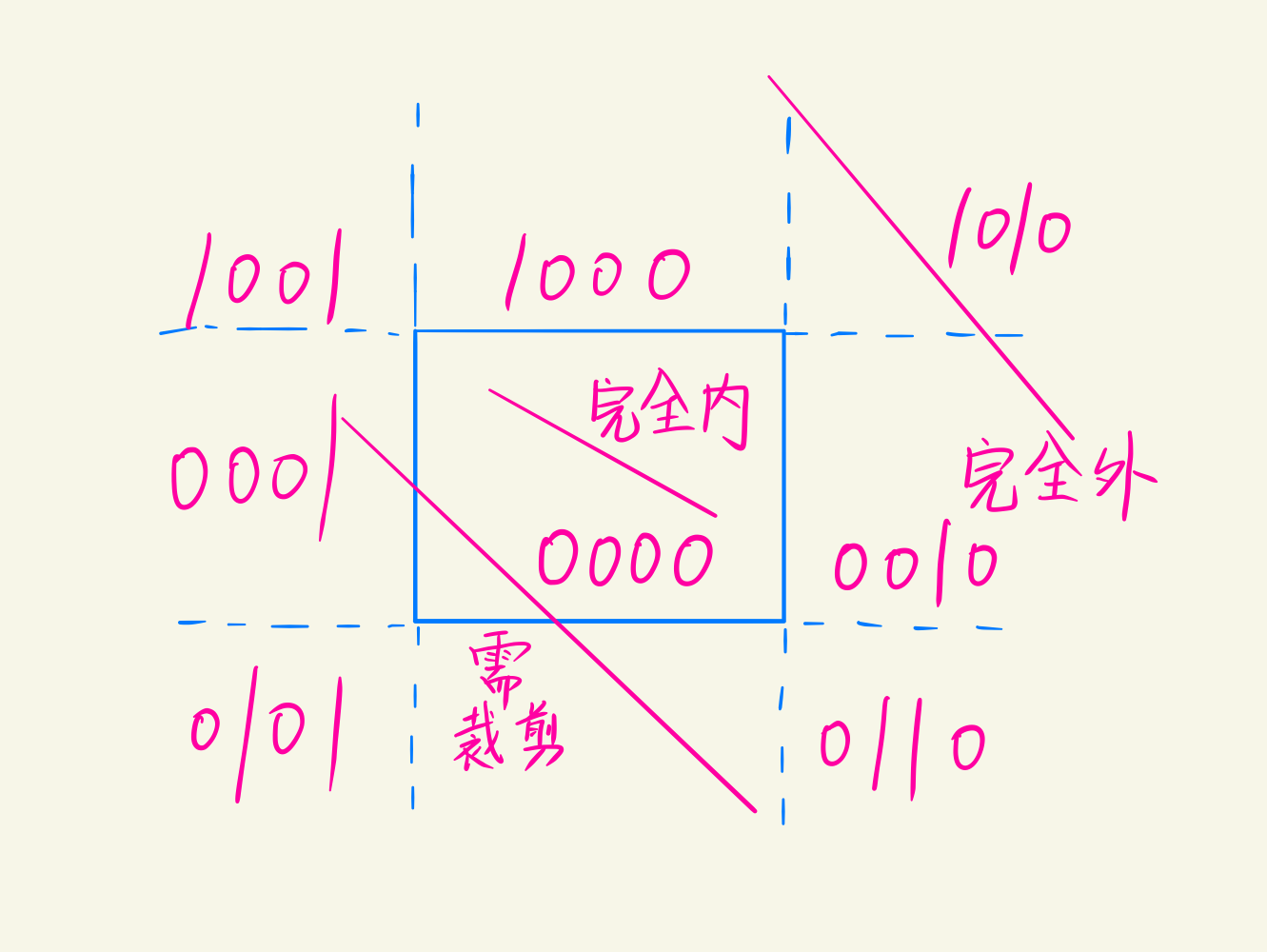
设直线的两个端点$p_1,p_2$
- $p_1,p_2$全部在窗口内,保留直线
- 完全在窗口外,抛弃
- $x_1\leq x_{\text{left}} \& x_2\leq x_{\text{left}}$
- $x_1\geq x_{\text{right}} \& x_2\geq x_{\text{right}}$
- $y_1\geq y_{\text{top}} \& y_2\geq y_{\text{top}}$
- $y_1\geq y_{\text{bottom}} \& y_2\geq y_{\text{bottom}}$
- 与窗口相交,则按照交点分段,抛弃一部分,保留窗口内的线段。
以窗口的延长线将区域分为9部分,编码四位数$D_0D_1D_2D_3$,编码规则为
- $x\leq x_{\text{left}}, D_0=1 \text{ else } D_0=0$
- $x\geq x_{\text{right}}, D_1=1 \text{ else } D_1=0$
- $y\leq y_{\text{bottom}}, D_2=1 \text{ else } D_2=0$
- $y\geq y_{\text{top}}, D_3=1 \text{ else } D_3=0$
通过二进制的运算来判断是否保留线段
- 两个交点的与运算后,$\neq0$,在窗口外,抛弃
- 两个交点的或运算后,$=0$,在窗口内,保留
- 如果以上均不成立,则需要求交点,划分线段,然后继续
例题
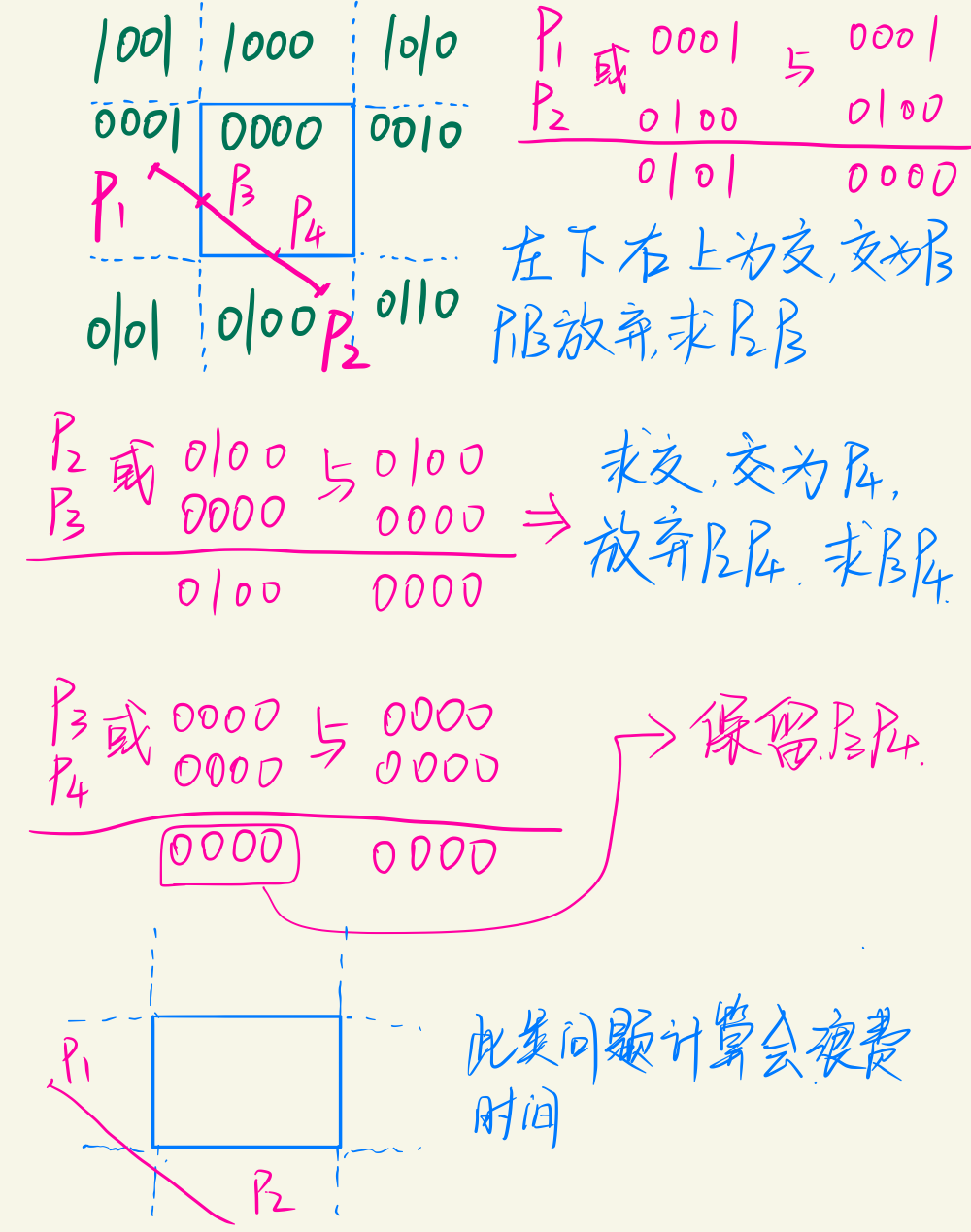
编码的思想值得学习,二进制计算速度快,适用于直线的大部分在区域内可见或者大部分在区域外不可见的情况。
Liang-Barsky算法
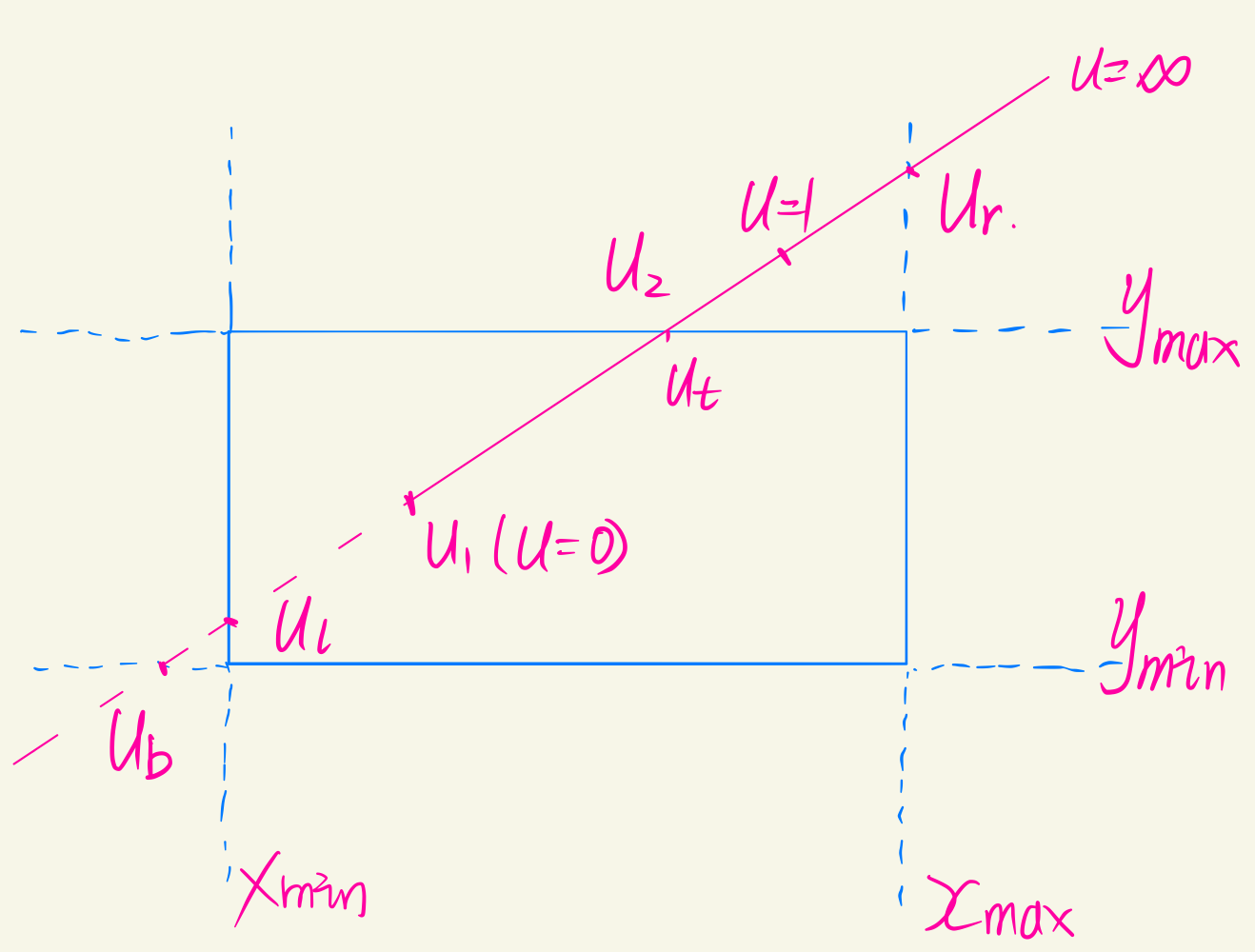
核心思想:
- 将直线以参数方程进行表示
- 将线段视为有方向的线段
- 入边:直线由窗口外向窗口内移动时会与边界有交点(左侧与下侧),出边:直线由窗口内向窗口外移动时会与边界有交点(上侧与下侧)。
- 最后只需要求解裁剪后的起点与终点,即参数方程中的参数是,求解得到裁剪后的方程。
- $u_1$窗口内可见的起点,$u_1=max(0, u_l, u_b)$(入边)
- $u_2$窗口内可见的终点,$u_2=min(1, u_t, u_r)$(出边)

所以现在的问题是:
- 如何判断入边与出边
- $u_l, u_b, u_t, u_r$如何去求
判断线段的某各部分是否在窗口内,可以判断线段上的一个点$P$是否在窗口内,于是转换为裁剪不等式:
$u$为直线与四条边交点的参数,求出四个交点。通过$p_k$的符号来判断入边与出边。
- $\Delta x > 0 \Longrightarrow u(-\Delta x) < 0$, 外到内,左侧,入边。
- $\Delta x > 0 \Longrightarrow u(\Delta x) > 0$, 内到外,右侧,出边。
- $\Delta y > 0 \Longrightarrow u(-\Delta y) < 0$, 外到内,下侧,入边。
- $\Delta y > 0 \Longrightarrow u(\Delta y) > 0$, 内到外,上侧,出边。
如此,求得了出边与入边,以及相关的$u$值,求解即可。
例题

可以看到,Liang-barsky算法一般情况下会更好,但只适用于矩形的裁剪窗口。更改的底层算法效率更高,可以固化到计算机底层硬件中,加速显示与执行效率,且图形软件则不用研究此类算法(如photoshop)
多边形裁剪
裁剪后的多边形边界的顶点序列。保留封闭区域,可能一个,也可能多个。Sutherland-hodgemen算法针对裁剪过程中出现的四种情况,作出了分类求解:
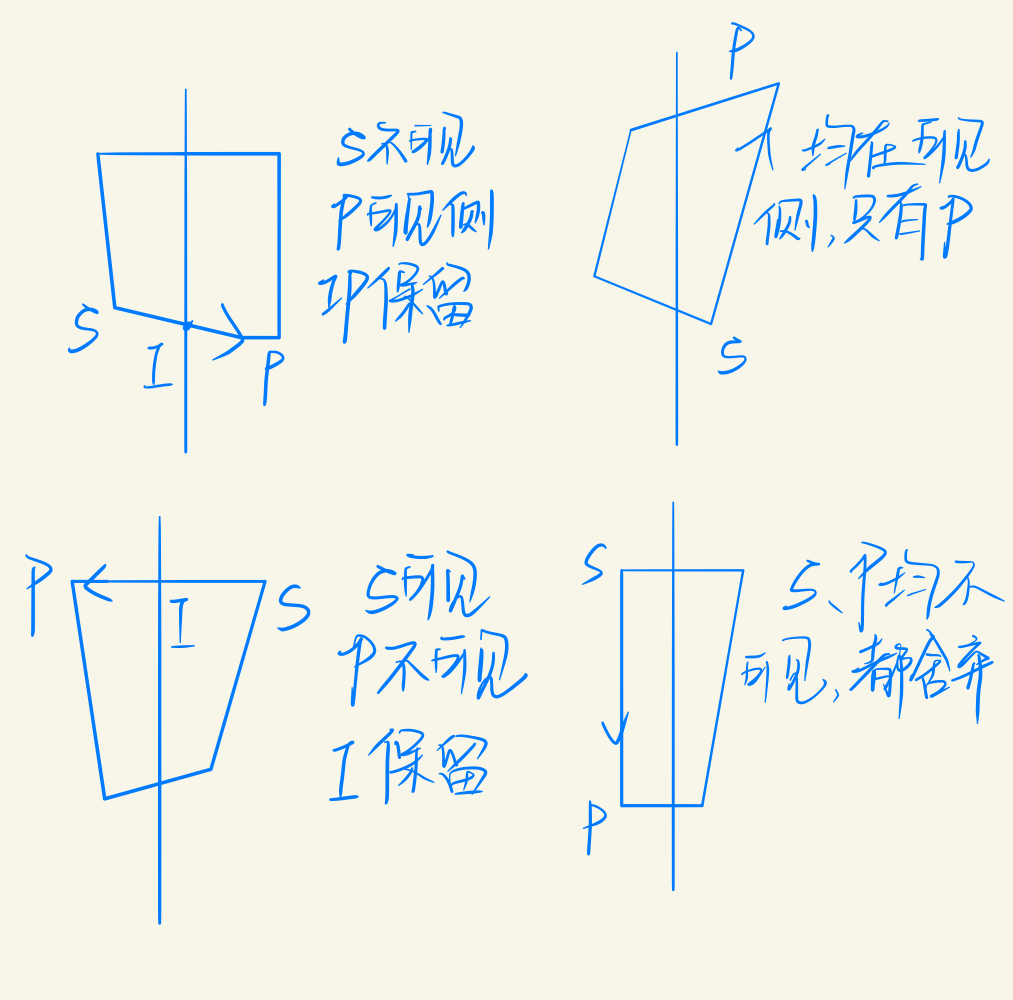
例题
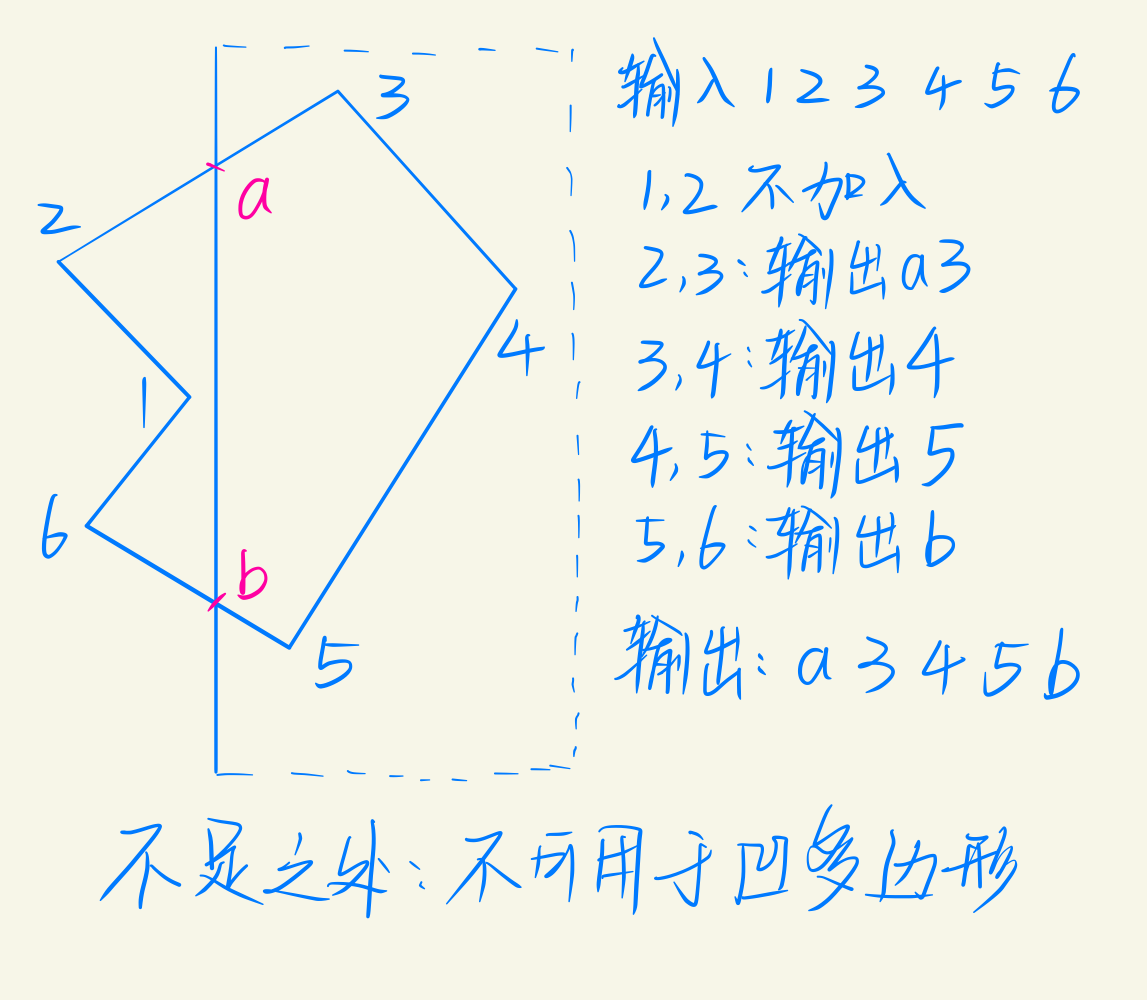
文字裁剪算法
- 串精度的裁剪:字符串全部在窗口内部,保留;一个字符不在,全部舍弃。
- 字符精度裁剪:一个字符位于边界没完全在窗口内,舍弃这个字符,字符串的其他字符保留。
- 笔划、像素精度的裁剪:哪些像素在窗口内,保留,即但个字符会切为两部分。
消隐算法
消隐:当物体不透明时,物体的背面时看不到的,于是不可见一侧的面不用绘制。消除不可见的线与面。消隐的过程与对象有关,与观察者的位置有关。
按消隐对象分类:
- 线消隐:消除的是线
- 面消隐:消除的是面
按消隐空间分类:
- 物体空间:$k$个物体与$k-1$个物体的对比遮挡。
- 图像空间:像素位置距离观察者的远近(主流研究)
消隐的基础算法:画家算法。先画远的,再画近的,近的遮盖远处的物体,实现最简单的消隐。三维中,随观察者视野的变化,不同物体的近远可能会发生变化,此时可能会随视野变化相互遮挡。
消隐算法:
- Z-buffer算法
- 扫描线算法
- Warnock算法
Z-buffer算法
可用于生成复杂图形,首先设立帧缓冲器:
- 帧缓冲器(像素点)存储每个可见像素的光强与颜色
- 深度数组(与像素点等量)存储可见像素的$z$坐标,近的$z$大,远的$z$小
$z$的求法:空间中的平面方程为:$Ax+By+Cz+d=0\Longrightarrow z=\frac{Ax+By+d}{-C}$
在同一条视野线上:$P_1$在$P_2$前面,则只显示$P_1$的颜色。同一组$(x,y)$,通过判断$z$的大小来决定显示哪个像素,与在屏幕中的出现顺序无关。
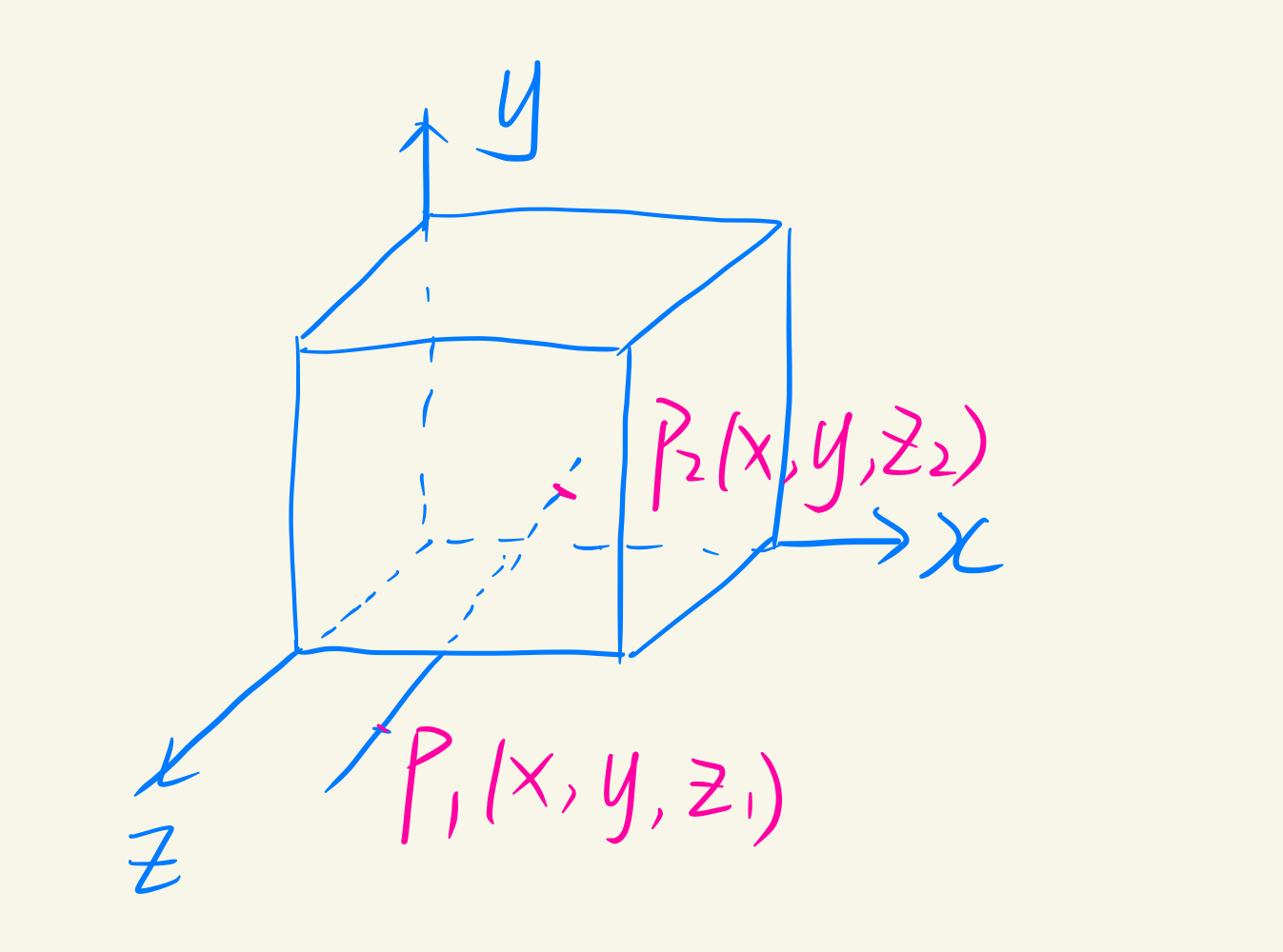
特点:
- 占用空间大
- 没有利用到图形的相关性与连续性
- 像素级的消隐,复杂度高
只用一个帧缓冲器
以$i,j$表示像素的在多边形内的某个点。
1 | depth = minValue |
如何判断像素$(i,j)$是多边形内部的点:
- 射线法
- 弧长法
- 弧长判断法
射线法
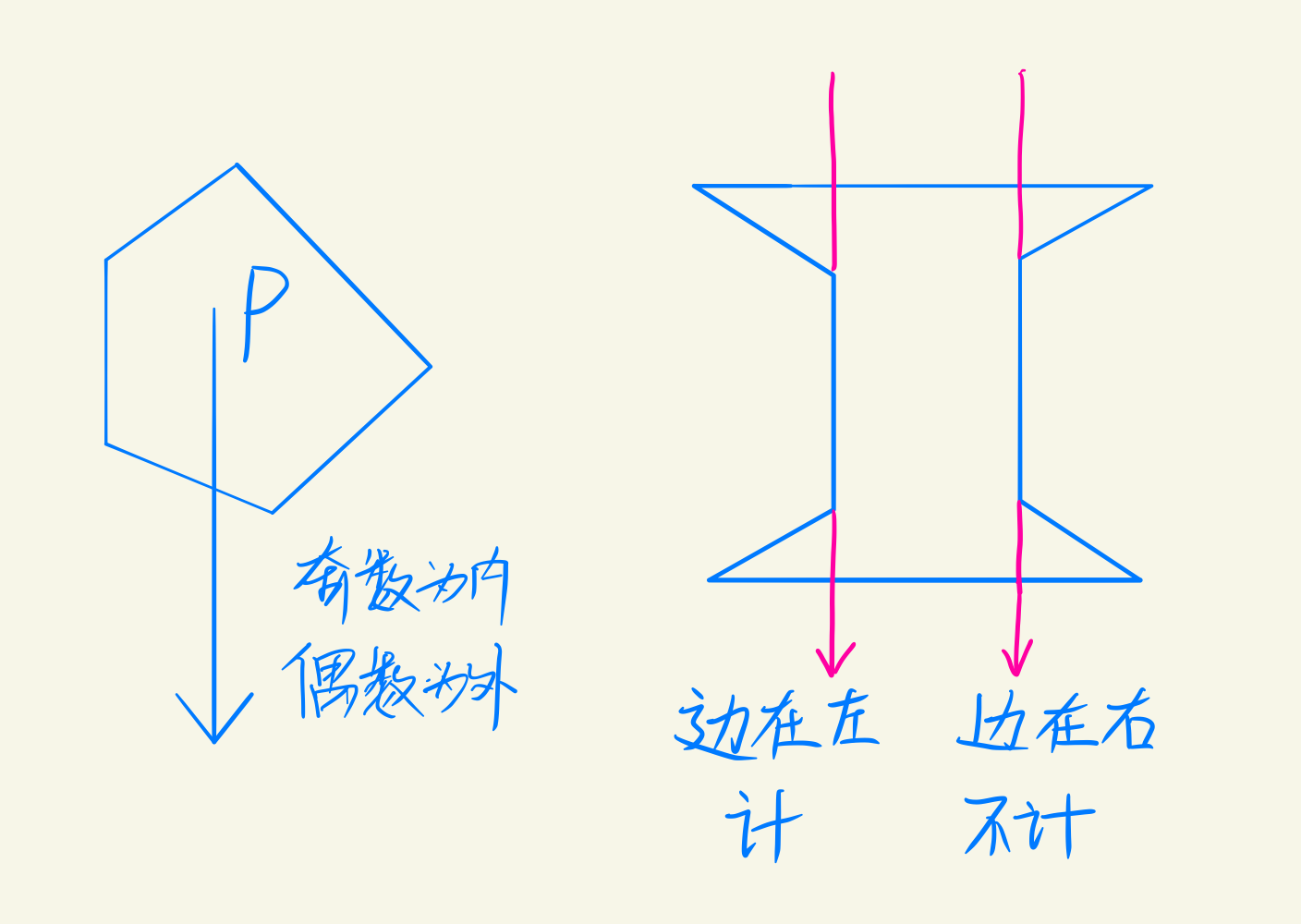
弧长法
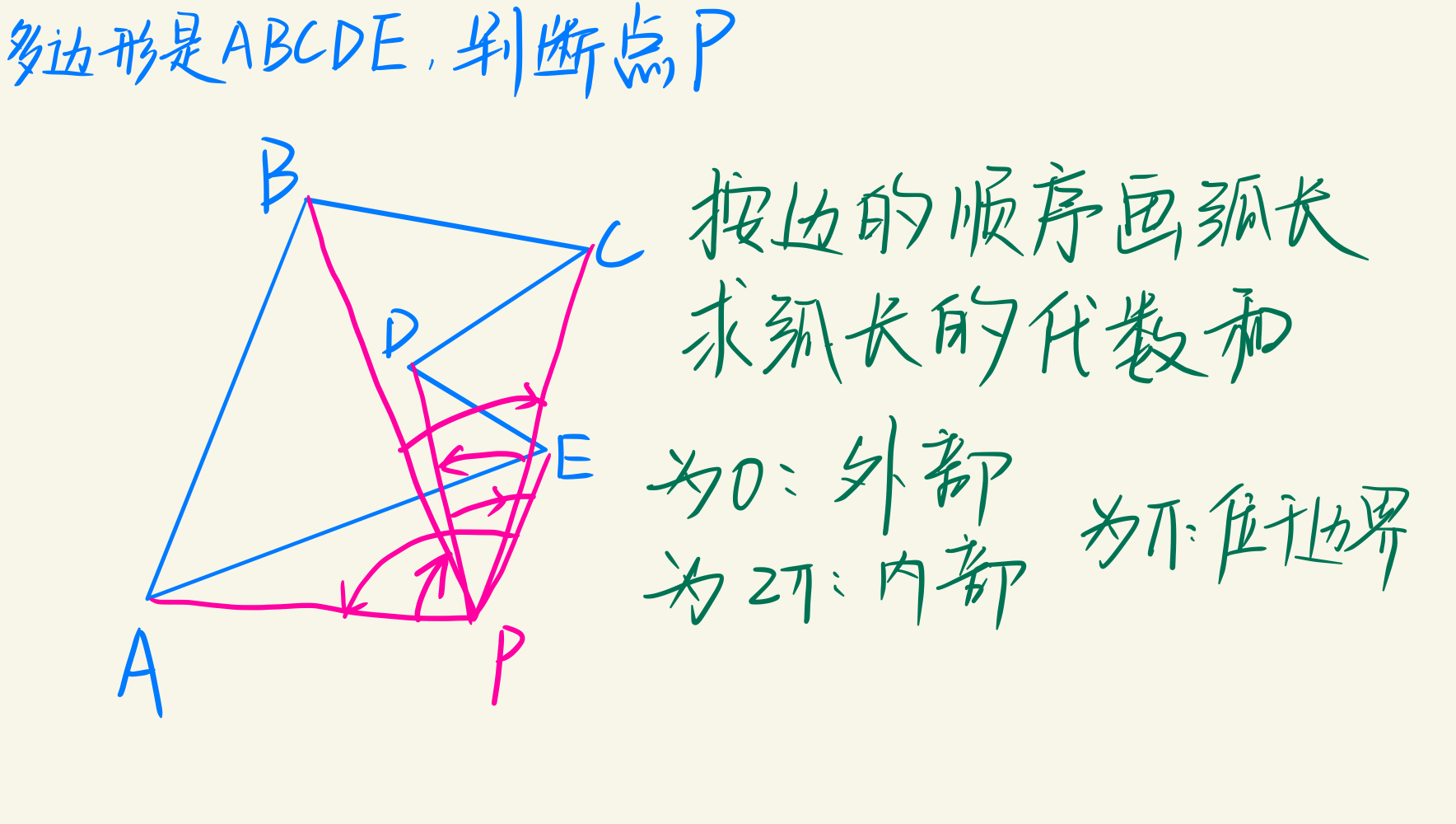
但是弧长的计算比较不容易,还需要考虑精度问题。需要加以改进。
弧长判断法
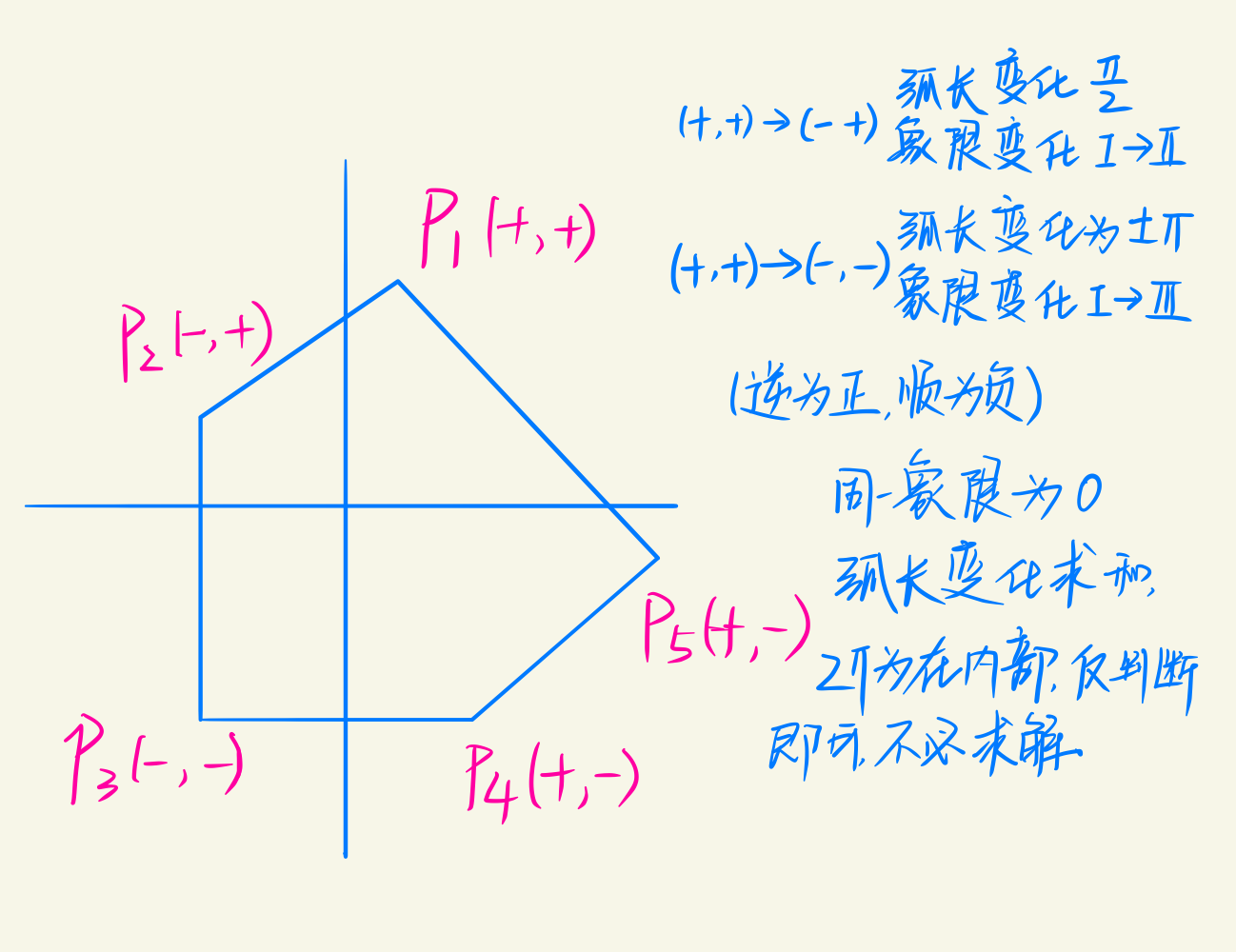
虽然加以改进,仍是基于像素级别的消隐,时间效率不高。
区间扫描线算法
不再基于像素级别的消隐,加快了执行速度。
按照扫描线的思想,同款区间设置同款颜色,而相交的区间取决于谁在前。而在染色时,一个像素决定了一个区间的颜色,以逐段染色的方式对区间进行染色。
同样,借助图形的连贯性和连续性,以增量的形式避免求交,排序$x$点,染色。
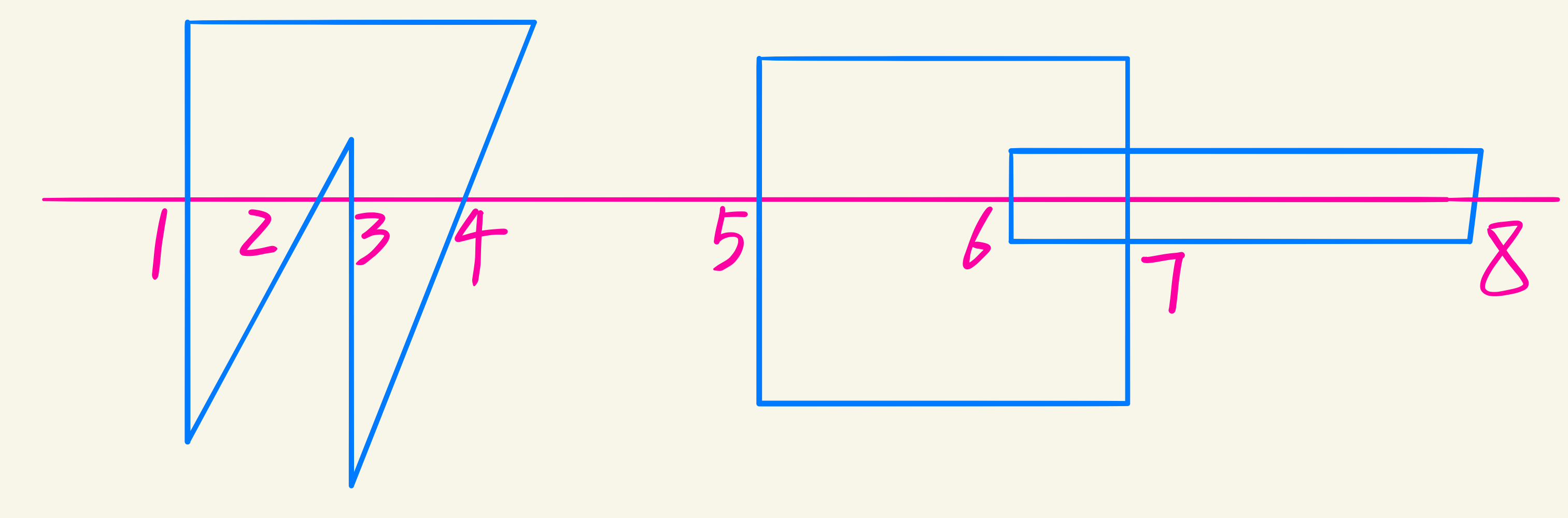
- 无多边形,$[a_4,a_5]$染背景颜色
- 一个多边形内,$[a_1,a_2]$染对应的颜色
- 多个多边形相交,$[a_6,a_7]$取决于$z$值
Warnock算法
效率不是很高,而是一种全新的思想。
将区域递归分割,直到窗口内的目标足够简单到可以显示为止。
足够简单的定义(足够简单则直接显示):
- 只有一个多边形
- 窗口内无其他多边形
- 窗口被一个多边形包围
- 窗口与一个多边形分离
判断一个多边形在窗口内:
判断多边形与窗口相交:用直线方程(规定定义域内)求交点判断即可。
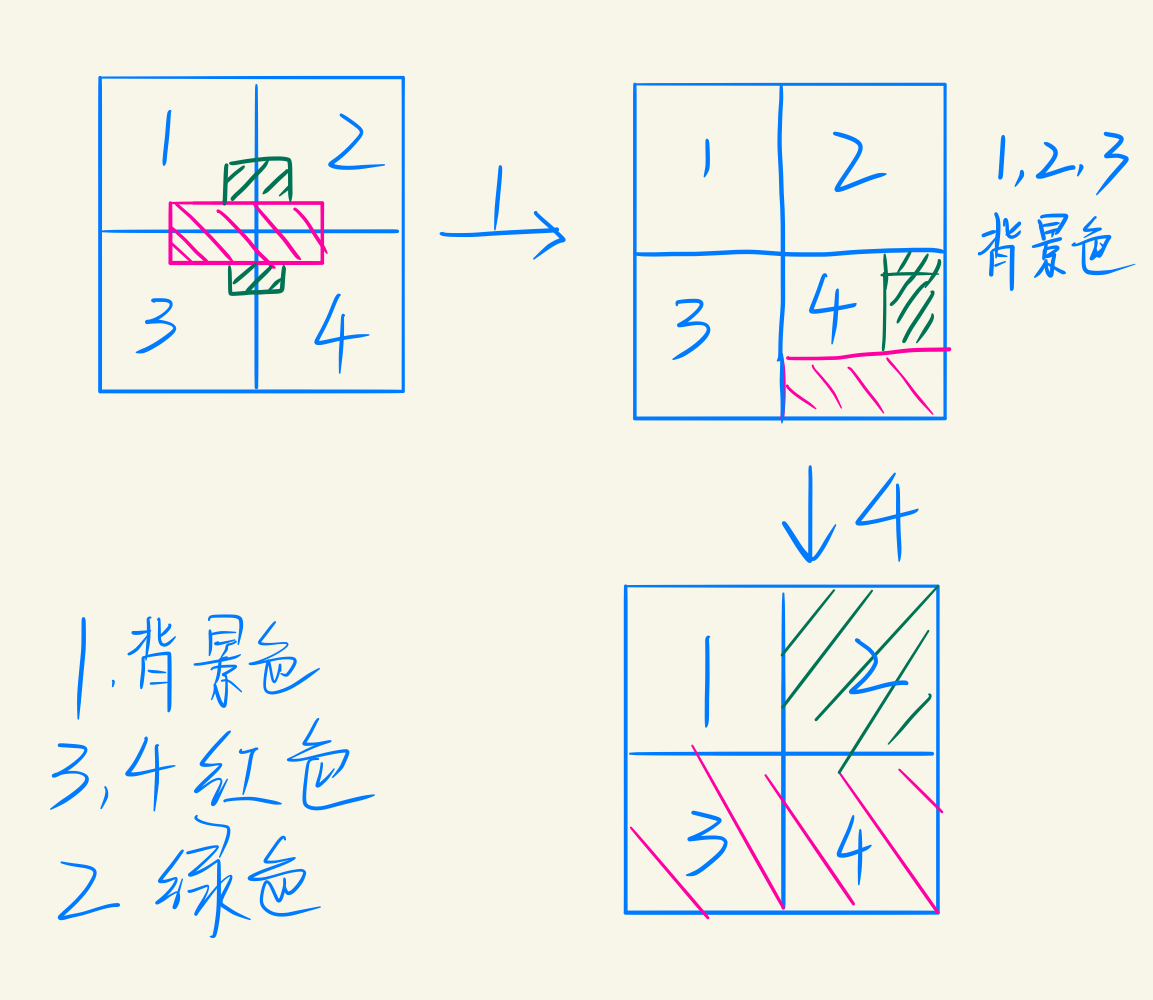
当窗口内有多个多边形无法直接显示时:
- 没有物体染背景色
- 一个面则直接显示
- 窗口有两个面及其以上,等分为四个窗口,递归执行。
二维图形变换
向量的基础
对对象的变换:形状、位置、方向,最后计算每个点的像素值。变换的基础是向量,有长度方向,无位置;对于单纯的点,有位置,无长度与方向。且可以上升到$n$维向量,便于处理问题。
向量的线性组合:$\vec{w}=a_1\vec{v}_1+a_2\vec{v}_2+a_3\vec{v}_3+\dots+a_n\vec{v}_n$
仿射组合:$a_1+a_2+a_3+\dots+a_n=1$
基本运算:
- $|w|=\sqrt{a_1^2+a_2^2+a_3^2+\dots+a_n^2}$, $\hat{w}=\frac{\vec{w}}{|w|}$
- $a\cdot b=a_1b_1+a_2b_2$
- $\mathrm{cos}\theta = \frac{a\cdot b}{|a||b|}$
- $a\times b=|a||b|\mathrm{sin}\theta$(求法向量)
图形坐标系
坐标分为一维、二维、三维等,联系了图形与数。(当然也有直角座标,极座标,球坐标等)。用于描述对象的几何信息,应用于建模;表述对象的大小与位置,用于观察。(像素点坐标下没有小数)
- 世界座标系:一个参考的标准,公共座标系,统一参考系。
- 建模座标系:物体内部的座标系。
- 观察座标系:不同观察角度对象的重新定位与描述,用于指定输出范围,在世界座标系中指定坐标,选定方向和位置进行裁剪。
- 设备座标系:(整数),针对一个具体设备的坐标系。
- 规范化座标系:不依赖于设备,但容易转化为不同设备的座标系(打印机、手机),范围在$[0,1]$。
二维图形转换
基本的变换包括比例、旋转和镜像等。
变换的原理:
- 图形在变化,但是连边规则不变
- 图形变化因为顶点位置在变
- 坐标变换,拓扑关系没变
上述的变换符合二维到二维的线性变换(也符合仿射变换),具有以下性质
- 平直性:直线经过变换仍然是直线
- 平行性:平行的直线变换后依然平行,直线上点的顺序不变
齐次坐标
$(x,y)$ ,表示一个点 $(x*, y*)=(x,y) \cdot M$,$M$表示变换矩阵。
$n+1$维表示$n$维:称为齐次坐标表示法,$(p_1,p_2,p_3,\dots,p_n)$推到$(hp_1,hp_2,hp_3,\dots,hp_n)$,$h$称为哑坐标,$h=1$是规格化坐标,前$n$个坐标是普通坐标下的$n$维坐标。
也可以这样考虑,$(x,y)$是$z=0$上的点,$(x,y,1)$是$z=1$上的点。会加速计算的方便性。
平移变换
$P$点沿直线到另一个点重定位的过程,平移变换是不产生形变的物体的刚体变换。
疑问
- bresenham算法的 $e$ 到底大于几
- 加权采样法如何计算
- X扫描线算法(3)
- NET的放入AET的标准
- Z-buffer算法的帧缓冲器存储光强还是像素存储光强
结语
以上内容和图片都参考了MOOC上中国农业大学计算机图形学的课程,如有雷同,雷同就雷同吧,反正是我抄的他的PPT。

