承接上文,实现多任务的方法一般有三种,今日来实现其中的一种:多进程爬虫。而剩余的多线程并发和协程暂时没时间搞了,一方面是要先学习下Python的yield和send如何使用,其次要准备毕设的中期答辩和被老师安排了去读源代码,日后会补上的。但仅仅是多进程,就将IO密集的任务从1153秒提升到了105秒 ,且极高的提升了资源利用率。
还有一点,本文的代码可能只适用于Next主题,但方法思路是通解,只要改改参数适应你的主题,代码同样能用。结果展示:本站热门
爬虫 如果对爬虫不太了解,可以参考我之前的几篇文章。如果你计算机功底还不错,那么实现爬虫入门,完成简单的爬虫任务还是可以的:
这次的爬取任务很简单,之前看到了别人博客有『热榜』 这个东西,很是眼馋,查询了一下发现实现热榜这个东西得经过很多的配置,但是我懒不想配置。于是准备自己动手爬虫,爬取每篇博客的访问量,以此作为博客每排文章的热度,说干就干,开工。
爬虫思路
本次爬虫需要request、BeautiulSoup和selenium联合使用,只有其中的一方完不成任务。
因为每篇博客的访问量并不在外部显示,必须点击到文章内部才难加载,所以,这次爬虫必须使用selenium控制浏览器模拟点击,之后进入对应网页,以此来获取不蒜子统计的浏览数量。
首先打开网页的根域名,按F12发现每篇文章的链接的类是post-title-link,以此来获取第一篇文章的名称,点击,进入第一篇博客。部分代码如下所示:
1 2 3 4 5 6 7 8 first_page = body.find('a' , {'class' , 'post-title-link' }) first = "" for i in first_page: first = i driver.find_element_by_xpath("//a[contains(text(),'{}')]" .format (first)).click()
本来想的是,进入网页后,使用requests库直接请求,然后解析出不蒜子统计那个标签的数量。但是,requests网页后发现不蒜子标签下数量根本不显示。意思是,仅仅依靠requests和beautifulsoup的爬虫是爬取不到不蒜子统计的。
所以,还得靠selenium。再次按一下F12,发现不蒜子统计的id是busuanzi_value_page_pv。利用selenium的id定位法,定位到不蒜子统计元素,然后输出定位元素里的文本。部分代码如下所示:
1 2 3 view = driver.find_element_by_id("busuanzi_value_page_pv" ) num = int (view.text)
而后,在每篇博客的末尾,都有指向下一篇博客的链接,点击既能进入下一篇博客。如下图所示:
而selenium定位到链接的文字又很费劲,不如用selenium获取当前网页的URL,然后使用requests和beautifulsoup库跟去获取的URL,进一步解析出指向下一篇博客链接的文字。而后把解析出的文字传给selenium的链接定位法,让selenium按照文字去点击链接,进入下一篇博客。如此循环往复,直到最后一篇博客。
因某些博客的图片数量过多,导致加载过慢,如果5秒内加载不完,则直接进入下一篇文章。中间为防止爬虫过猛被屏蔽,其中使用了一些延时函数放缓进度。
最终的结果要把文章的名称、文章的网址和文章的访问量都记录下来。考虑使用字典这种结构,将文章名称和网址作为key,访问量作为value。
将字典保存为json文件,而后将json文件中的结果稍微清洗一下,做成markdown文件,放到博客里,热榜就做成了。
最后,对爬虫任务的整体时间进行记录,对比单进程和多进程的效率。
单进程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 import requestsfrom bs4 import BeautifulSouphome_url = "https://muyuuuu.github.io/" r = requests.get(home_url) soup = BeautifulSoup(r.text, "lxml" ) body = soup.body from selenium import webdriverdriver = webdriver.Chrome(executable_path='/home/lanling/chromedriver_linux64/chromedriver' ) import timearticle = {} driver.get(home_url) first_page = body.find('a' , {'class' , 'post-title-link' }) first = "" for i in first_page: first = i driver.find_element_by_xpath("//a[contains(text(),'{}')]" .format (first)).click() time.sleep(3 ) dr = driver.find_element_by_id("busuanzi_value_page_pv" ) string = "[" + first + "]" + "(" + driver.current_url + ")" article[string] = int (dr.text) print (article)start = time.time() url = driver.current_url data = requests.get(url) data = BeautifulSoup(data.text, "lxml" ) next = data.find('div' , {'class' :'post-nav-next post-nav-item' })try : while next : time.sleep(1 ) driver.find_element_by_link_text(next .text.strip()).click() time.sleep(5 ) try : view = driver.find_element_by_id("busuanzi_value_page_pv" ) except : pass url = driver.current_url time.sleep(1 ) data = requests.get(url) data = BeautifulSoup(data.text, "lxml" ) string = "[" + data.title.text + "]" + "(" + driver.current_url + ")" if view.text == "" : article[string] = -2 else : article[string] = int (view.text) print (string, int (view.text)) time.sleep(1 ) next = data.find('div' , {'class' :'post-nav-next post-nav-item' }) except : end = time.time() print (end - start)driver.quit() article_save = sorted (article.items(), key = lambda item:item[1 ]) import jsonwith open ('data.json' ,'w' ,encoding='utf-8' ) as f_obj: json.dump(article_save,f_obj,ensure_ascii=False , indent=4 )
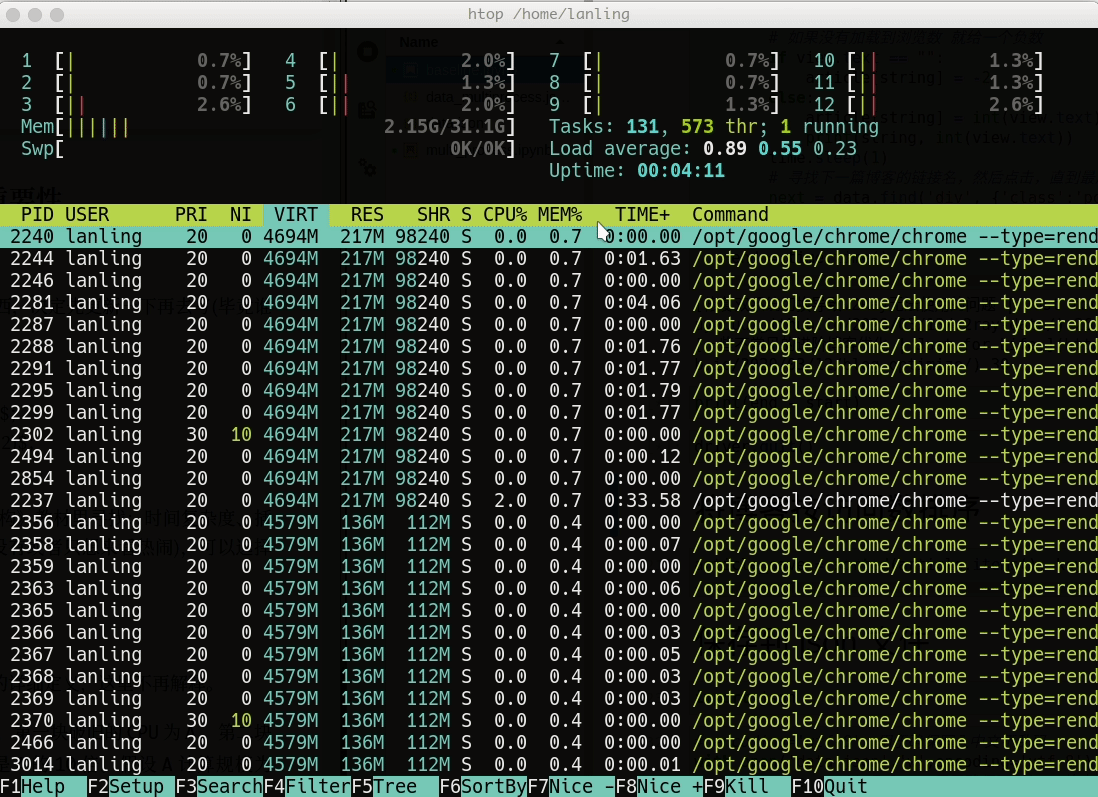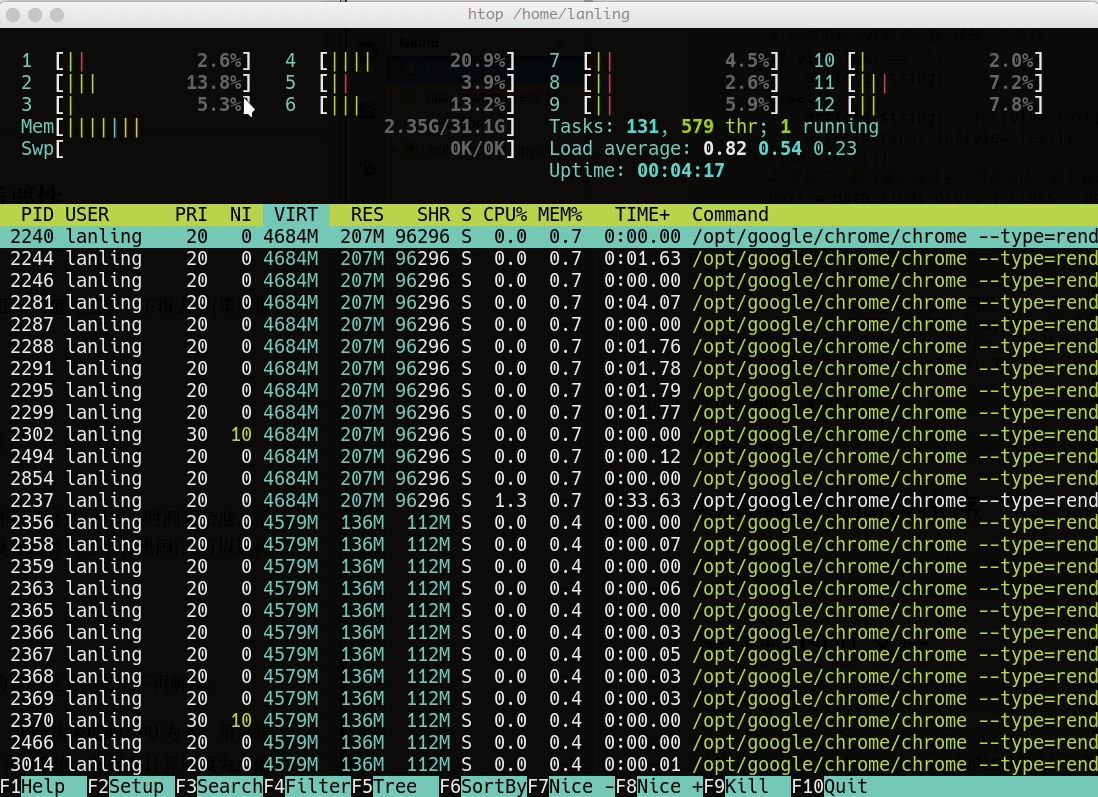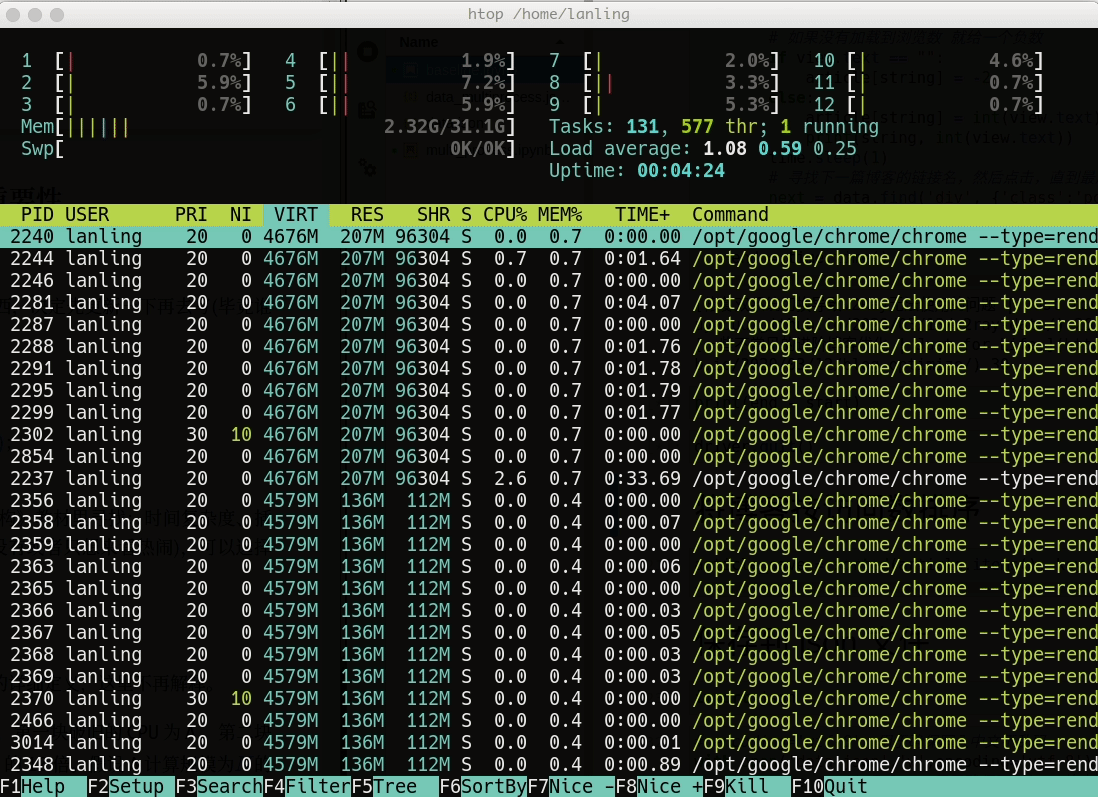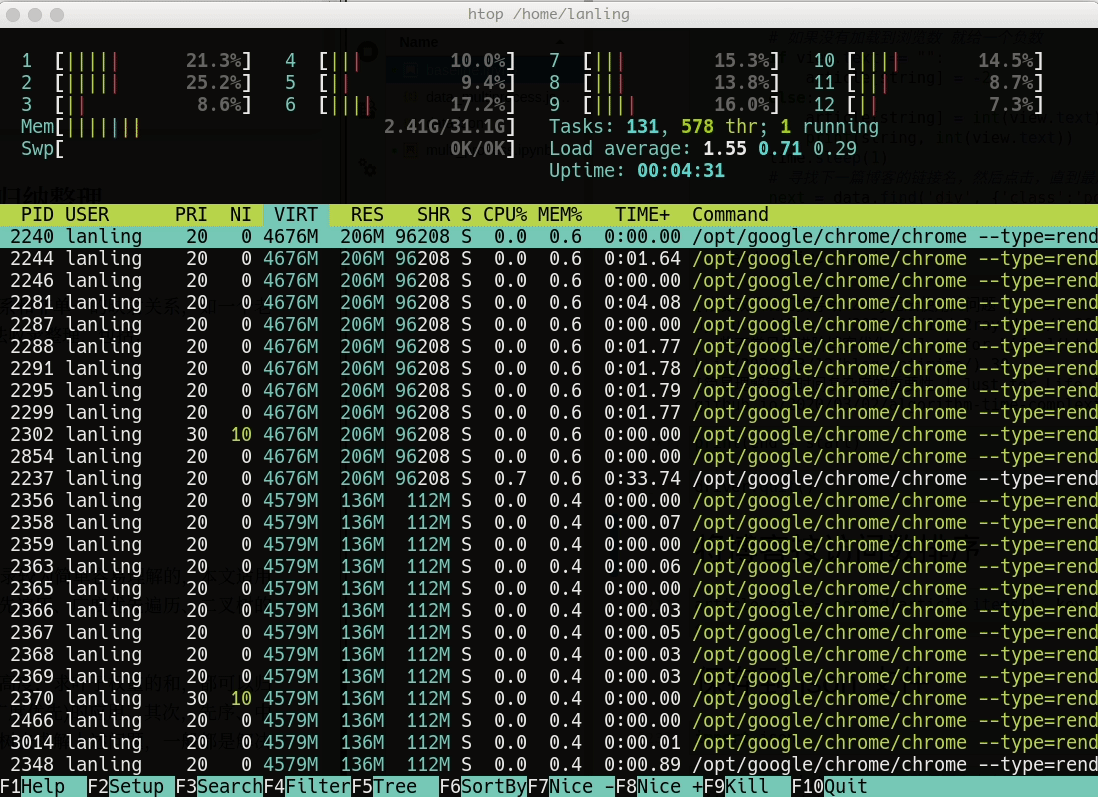
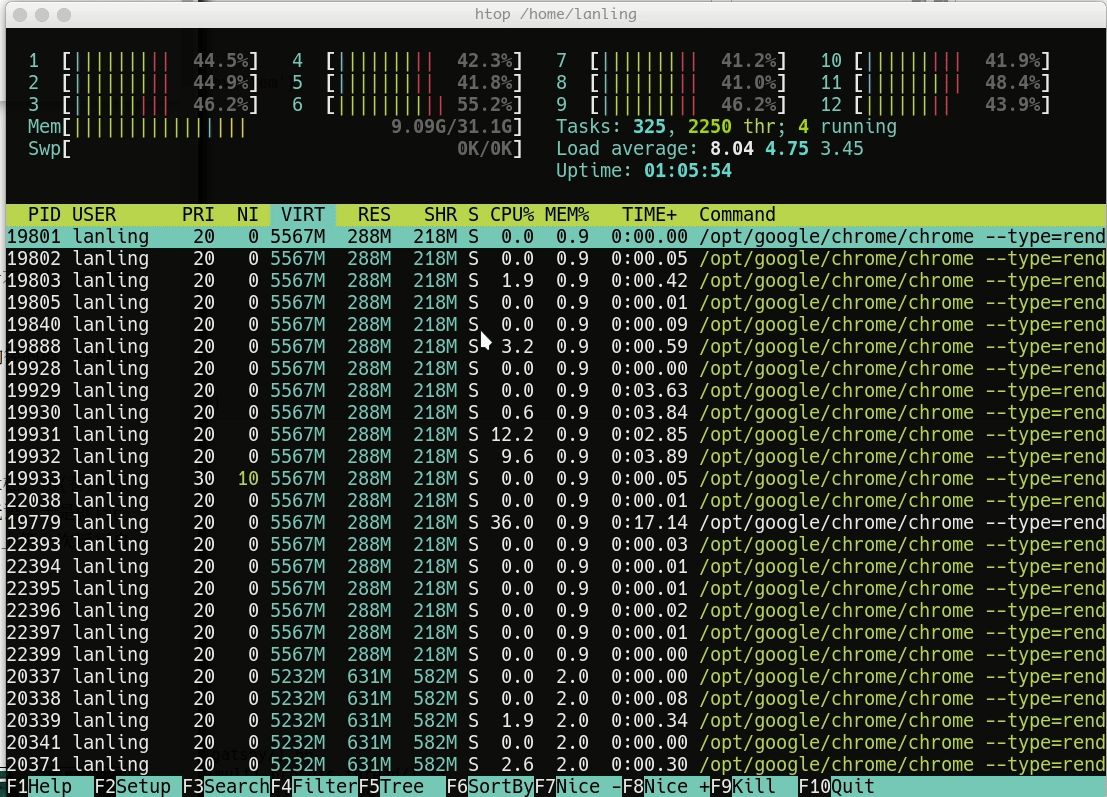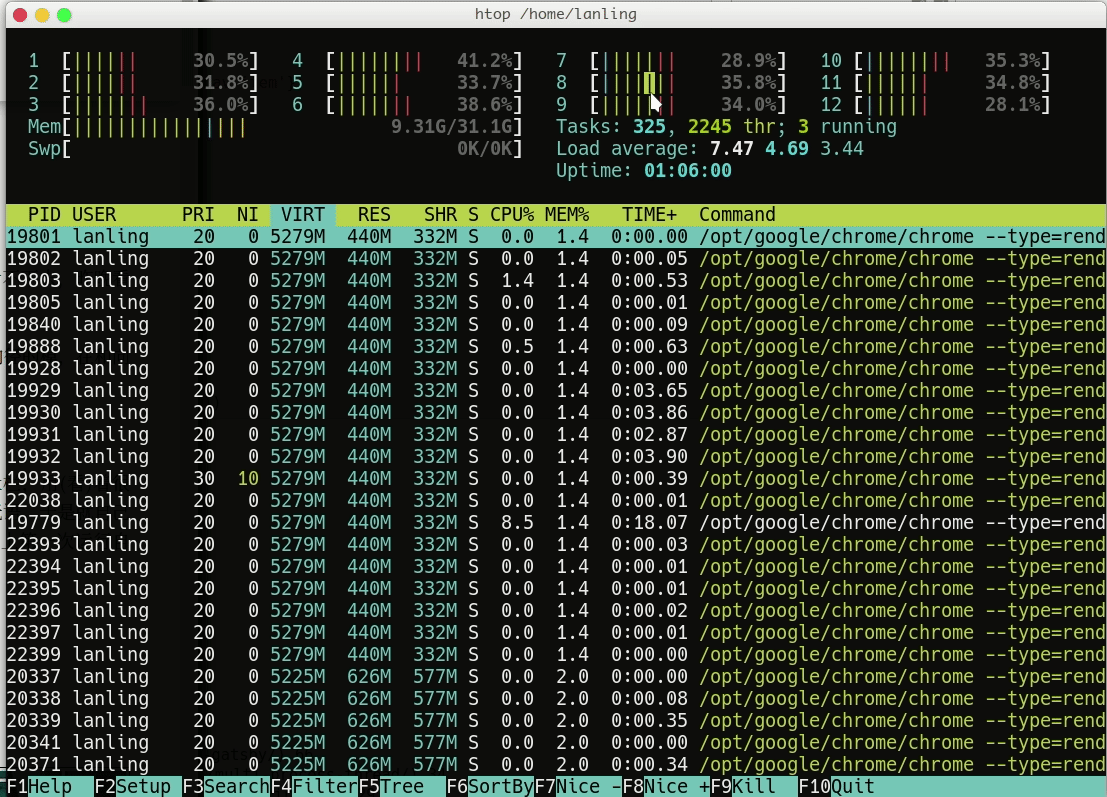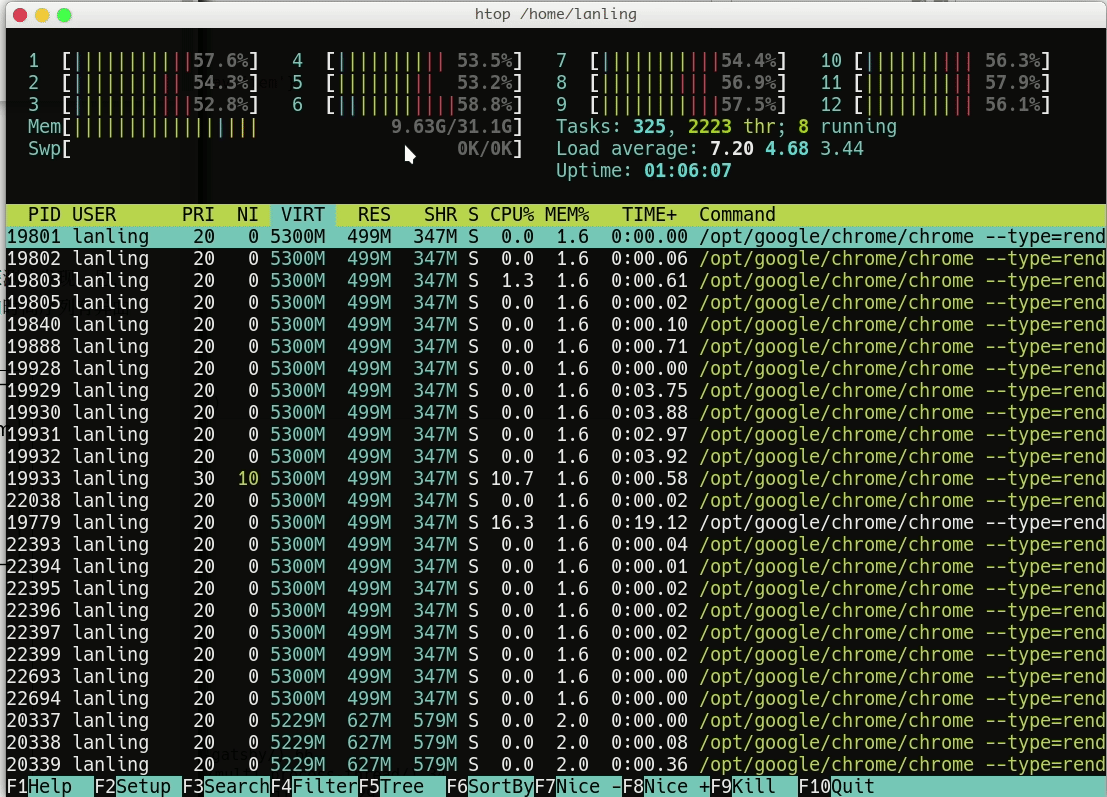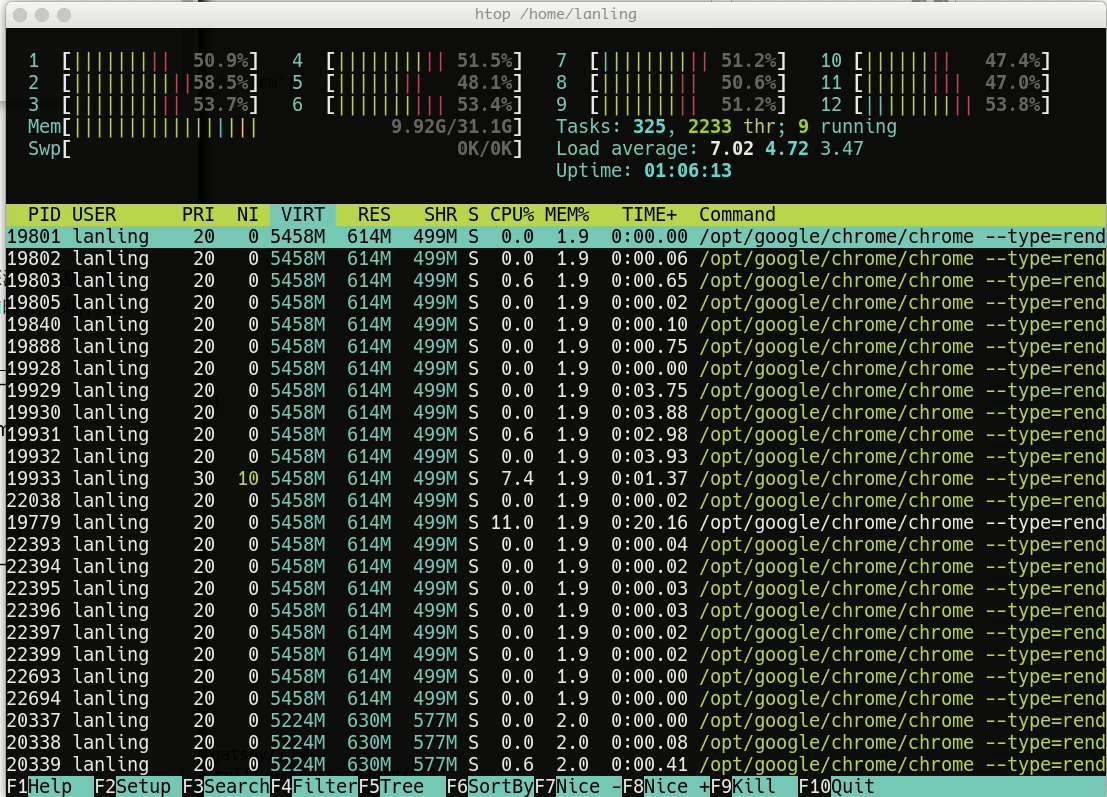
这个单进程的任务总共耗时1153 秒左右(毕竟网络时延说不准),资源利用率很少,如下所示:
多进程 多进程仅需在单进程的代码上做一点改动即可:(如果你不懂多进程,请参考我的上一篇文章,如何理解多进程 )
首先统计一下博客有几页,就创建几个进程。比如,我的博客目前有14页,就创建14个进程:
进程扔到一个进程池里,等待所有进程执行完毕即可。
多进程之间不共享变量,所以字典的创建方法需要更改。
同样,防止爬虫过猛,中间同样适用延时函数放缓进度。
记录多进程的耗时,与单进程对比。代码如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 import requestsfrom bs4 import BeautifulSouphome_url = "https://muyuuuu.github.io/" r = requests.get(home_url) soup = BeautifulSoup(r.text, "lxml" ) body = soup.body page_number = body.find('nav' , {'class' : 'pagination' }) a = page_number.find_all('a' ) max_page_number = 0 for i in a: for j in i: if str (j).isdigit(): if int (j) > max_page_number: max_page_number = int (j) print (max_page_number)process_num = max_page_number from multiprocessing import Poolimport time, randomfrom selenium import webdriverimport multiprocessingarticle = multiprocessing.Manager().dict () per_page = 7 def respite_task (url_num ): num = 1 sub_url = "" if url_num == 0 : sub_url = "https://muyuuuu.github.io/" else : sub_url = "https://muyuuuu.github.io/page/" + str (url_num) + "/" print ("here" ) driver = webdriver.Chrome(executable_path='/home/lanling/chromedriver_linux64/chromedriver' ) driver.get(sub_url) time.sleep(random.randint(2 , 6 )) r = requests.get(sub_url) soup = BeautifulSoup(r.text, "lxml" ) body = soup.body first_page = body.find('a' , {'class' , 'post-title-link' }) first = "" for i in first_page: first = i driver.find_element_by_xpath("//a[contains(text(),'{}')]" .format (first)).click() time.sleep(5 ) try : view = driver.find_element_by_id("busuanzi_value_page_pv" ) except : pass string = "[" + first + "]" + "(" + driver.current_url + ")" if view.text == "" : article[string] = -2 else : article[string] = int (view.text) print (string, int (view.text)) url = driver.current_url data = requests.get(url) data = BeautifulSoup(data.text, "lxml" ) next = data.find('div' , {'class' :'post-nav-next post-nav-item' }) try : while next and num < per_page: num += 1 time.sleep(1 ) driver.find_element_by_link_text(next .text.strip()).click() time.sleep(5 ) try : view = driver.find_element_by_id("busuanzi_value_page_pv" ) except : pass url = driver.current_url time.sleep(1 ) data = requests.get(url) data = BeautifulSoup(data.text, "lxml" ) string = "[" + data.title.text + "]" + "(" + driver.current_url + ")" if view.text == "" : article[string] = -2 else : article[string] = int (view.text) print (string, int (view.text)) time.sleep(1 ) next = data.find('div' , {'class' :'post-nav-next post-nav-item' }) except : pass finally : driver.quit() p = Pool(process_num) for i in range (process_num + 1 ): p.apply_async(respite_task, args=(i,)) print ('waitting for all subprocess done' )start = time.time() p.close() p.join() end = time.time() print ('All subprocesses done costs {} seconds' .format (end - start))article_save = sorted (article.items(), key = lambda item:item[1 ]) import jsonwith open ('data_multiprocess.json' ,'w' ,encoding='utf-8' ) as f_obj: json.dump(article_save,f_obj,ensure_ascii=False , indent=4 )
最终的结果和单线程的结果保持一致,但仅仅用了105 秒就执行完毕,足足提升了10倍。因为每个进程都有一个主线程,将主线程分配给多个核,所以导致了资源利用率比单线程要高的多:
结语 这好像不是传说中的并行计算,毕竟不是计算密集的任务,但这个几个进程的任务确实在并行执行,『知识就是力量』还是有道理的。