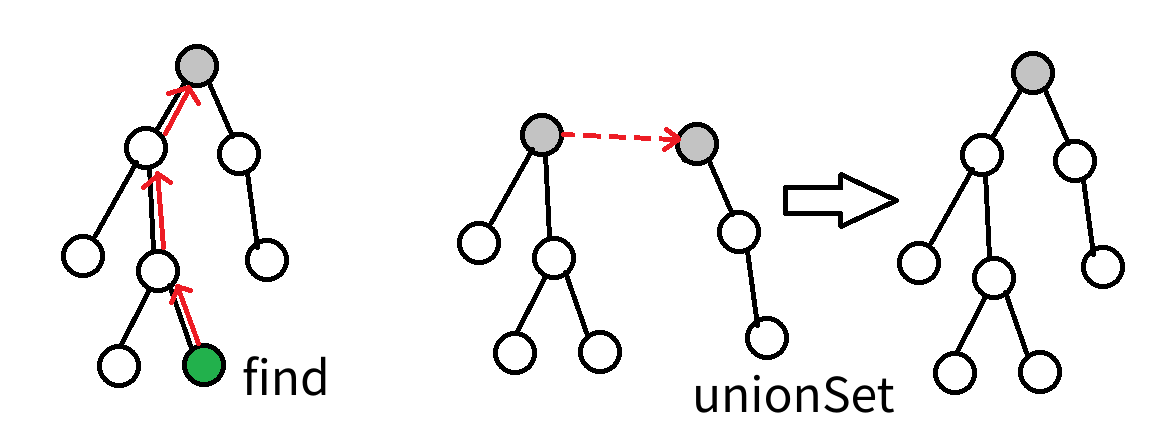
画成图就是这样的:右图的 union 表示两个集合合并后,更改一个节点的父节点(且左子树的父节点都要更改);左图中的 find 表示绿色节点在找根节点是谁,并修改这条路上所有节点的根节点。
社区聚类(基础应用)
When register on a social network, you are always asked to specify your hobbies in order to find some potential friends with the same hobbies. A social cluster is a set of people who have some of their hobbies in common. You are supposed to find all the clusters.
Each input file contains one test case. For each test case, the first line contains a positive integer $N (≤1000)$, the total number of people in a social network. Hence the people are numbered from $1$ to $N$. Then $N$ lines follow, each gives the hobby list of a person in the format:$K_i:h_i[1],h_i[2]…h_i[K_i]$, where $K_i (>0)$ is the number of hobbies, and $h_i[j]$ is the index of the $j$-th hobby, which is an integer in $[1, 1000]$.
For each case, print in one line the total number of clusters in the network. Then in the second line, print the numbers of people in the clusters in non-increasing order. The numbers must be separated by exactly one space, and there must be no extra space at the end of the line.
#include<cstdio> #include<vector> #include<algorithm> usingnamespace std; vector<int> father, isRoot; intcmp1(int a, int b){return a > b;}
// 查找父节点,并更改相关节点的父节点 intfindFather(int x){ int a = x; while(x != father[x]) x = father[x]; // 找到根节点后,把该集合内的节点的根节点都改为 x while(a != father[a]) { int z = a; a = father[a]; father[z] = x; } return x; }
// 更改父节点 voidUnion(int a, int b){ int faA = findFather(a); int faB = findFather(b); if(faA != faB) father[faA] = faB; }
This time, you are supposed to help us collect the data for family-owned property. Given each person’s family members, and the estate(房产)info under his/her own name, we need to know the size of each family, and the average area and number of sets of their real estate.
Each input file contains one test case. For each case, the first line gives a positive integer $N(≤1000)$. Then $N$ lines follow, each gives the infomation of a person who owns estate in the format:
IDFatherMother $k$ $Child_1$ $Child_2$ … $Child_k$ $M_\text{estate}$ Area
where ID is a unique 4-digit identification number for each person; Father and Mother are the ID’s of this person’s parents (if a parent has passed away, -1 will be given instead); $k(0≤k≤5)$ is the number of children of this person; $Child_i$’s are the ID‘s of his/her children; $M_\text{estate}$ is the total number of sets of the real estate under his/her name; and Area is the total area of his/her estate.
For each case, first print in a line the number of families (all the people that are related directly or indirectly are considered in the same family). Then output the family info in the format:
where ID is the smallest ID in the family; M is the total number of family members; $\text{AVG}_\text{sets}$ is the average number of sets of their real estate; and $\text{AVG}_\text{area}$ is the average area. The average numbers must be accurate up to 3 decimal places. The families must be given in descending order of their average areas, and in ascending order of the ID’s if there is a tie.