移动端算法优化是个很庞大的话题。从计算机体系到指令,涉及到非常广而深的东西。本文尝试以常见的算法为例,阐述算法在单线程场景下的加速与优化,多线程是最后的收尾,没啥可说的。而至于具体的场景,如金字塔、滤波、降噪等,优化的思路都是相同的:减少 IO,一次 IO 完成尽可能多的计算。
本文会使用 Neon, OpenCL 来优化算法,如果有可能也会引入 DSP。本文持续更新,整理算法优化相关的经验。额外的,确保打开了 O3 编译选项,打开 release 模式等,否则会影响算法的执行时间。
矩阵乘法
注:本文不考虑数学角度的优化,如修改计算公式得到相同结果什么的。实现的浮点矩阵计算为:
简单起见,$A$ 的维度为 $512\times 128$,矩阵 $B$ 的维度为 $128 \times 256$。在高通骁龙某芯片上,目前的加速结果如下:
| 版本 | 时间 |
|---|---|
| 常规矩阵乘法 | 59.84ms |
| Neon 加速版本 1 | 12.90 ms |
| Neon 加速版本 2 | 3.85ms |
| Cache 友好的矩阵乘法 | 2.52ms |
| Neon 加速版本 3 | 2.77ms |
| Neon 加速版本 4 | 2.01ms |
| Neon 加速版本 5 | 1.09ms |
为什么没 OpenCL?因为还没来得及写,仿佛欠着好多博客。
常规矩阵乘法
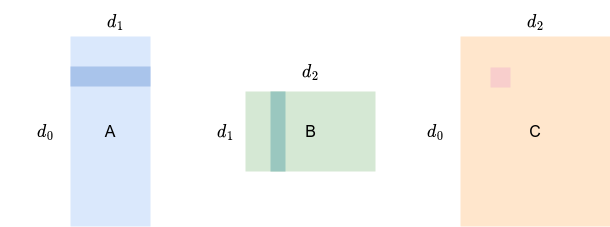
以线性代数中的矩阵乘法为例,目标矩阵的第 $i, j$ 个元素是矩阵 $A$ 的第 $i$ 行和矩阵 $B$ 的第 $j$ 列逐元素相乘相加的结果。根据这一原理写出最直观的代码,耗时 59.84ms:
1 | void sgemm_c(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) |
我们知道矩阵在计算机中是行朱序存储的,即访问矩阵 $B[i, j]$ 时,会将 $B[i, j+1], B[i, j+2],…$ 等元素也一同取到内存的 cache 中。当需要 $B[i, j+1]$ 时就从 cache 中读取而不是去内存读取,这样会节省很多时间。
所以上述代码的性能瓶颈在于:
1 | for (m = 0; m < d1; m++) { |
由于最内层的循环中 m 逐渐增加,矩阵 $B$ 的寻址方式为跳行寻址。在我们看不见的地方,cache 缓存的数据无法使用,每次读取 $B$ 矩阵的元素时还需要刷新 cache,这就导致这份代码很耗时。
Neon 加速版本 1
1 | void sgemm_neon1(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) |
Neon 加速版本 2
1 | void sgemm_neon2(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) |
Cache 友好的矩阵乘法
1 | void rsgemm_c(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) |
Neon 加速版本 3
1 | void rsgemm_neon1(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) |
Neon 加速版本 4
1 | void rsgemm_neon2(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) |
Neon 加速版本 5
1 | void rsgemm_neon3(float *C, float *A, float *B, float *bias, int d0, int d1, int d2) |

